 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrover's Search-Inspired Quantum Reinforcement Learning for Massive MIMO User Scheduling
Jan 28, 2026The efficient user scheduling policy in the massive Multiple Input Multiple Output (mMIMO) system remains a significant challenge in the field of 5G and Beyond 5G (B5G) due to its high computational complexity, scalability, and Channel State Information (CSI) overhead. This paper proposes a novel Grover's search-inspired Quantum Reinforcement Learning (QRL) framework for mMIMO user scheduling. The QRL agent can explore the exponentially large scheduling space effectively by applying Grover's search to the reinforcement learning process. The model is implemented using our designed quantum-gate-based circuit, which imitates the layered architecture of reinforcement learning, where quantum operations act as policy updates and decision-making units. Moreover, the simulation results demonstrate that the proposed method achieves proper convergence and significantly outperforms classical Convolutional Neural Networks (CNN) and Quantum Deep Learning (QDL) benchmarks.
Knowledge Probing for Graph Representation Learning
Aug 07, 2024Graph learning methods have been extensively applied in diverse application areas. However, what kind of inherent graph properties e.g. graph proximity, graph structural information has been encoded into graph representation learning for downstream tasks is still under-explored. In this paper, we propose a novel graph probing framework (GraphProbe) to investigate and interpret whether the family of graph learning methods has encoded different levels of knowledge in graph representation learning. Based on the intrinsic properties of graphs, we design three probes to systematically investigate the graph representation learning process from different perspectives, respectively the node-wise level, the path-wise level, and the structural level. We construct a thorough evaluation benchmark with nine representative graph learning methods from random walk based approaches, basic graph neural networks and self-supervised graph methods, and probe them on six benchmark datasets for node classification, link prediction and graph classification. The experimental evaluation verify that GraphProbe can estimate the capability of graph representation learning. Remaking results have been concluded: GCN and WeightedGCN methods are relatively versatile methods achieving better results with respect to different tasks.
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 24, 2023



Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy.
TFDNet: Time-Frequency Enhanced Decomposed Network for Long-term Time Series Forecasting
Aug 25, 2023


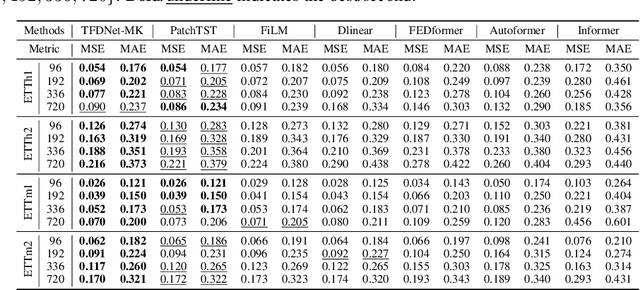
Long-term time series forecasting is a vital task and has a wide range of real applications. Recent methods focus on capturing the underlying patterns from one single domain (e.g. the time domain or the frequency domain), and have not taken a holistic view to process long-term time series from the time-frequency domains. In this paper, we propose a Time-Frequency Enhanced Decomposed Network (TFDNet) to capture both the long-term underlying patterns and temporal periodicity from the time-frequency domain. In TFDNet, we devise a multi-scale time-frequency enhanced encoder backbone and develop two separate trend and seasonal time-frequency blocks to capture the distinct patterns within the decomposed trend and seasonal components in multi-resolutions. Diverse kernel learning strategies of the kernel operations in time-frequency blocks have been explored, by investigating and incorporating the potential different channel-wise correlation patterns of multivariate time series. Experimental evaluation of eight datasets from five benchmark domains demonstrated that TFDNet is superior to state-of-the-art approaches in both effectiveness and efficiency.
Domain Balancing: Face Recognition on Long-Tailed Domains
Mar 30, 2020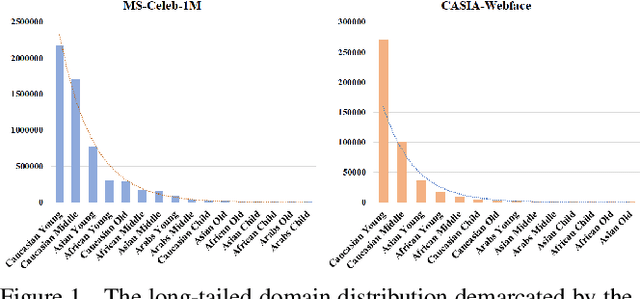
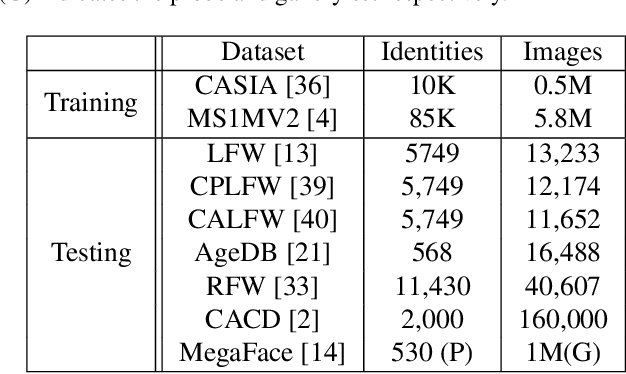
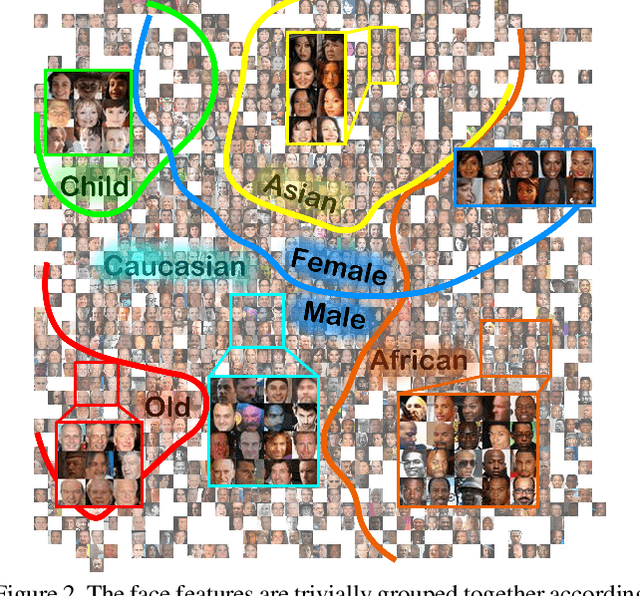
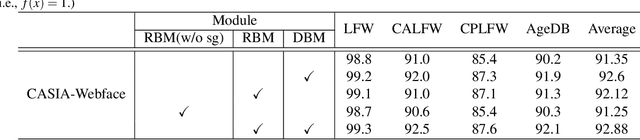
Long-tailed problem has been an important topic in face recognition task. However, existing methods only concentrate on the long-tailed distribution of classes. Differently, we devote to the long-tailed domain distribution problem, which refers to the fact that a small number of domains frequently appear while other domains far less existing. The key challenge of the problem is that domain labels are too complicated (related to race, age, pose, illumination, etc.) and inaccessible in real applications. In this paper, we propose a novel Domain Balancing (DB) mechanism to handle this problem. Specifically, we first propose a Domain Frequency Indicator (DFI) to judge whether a sample is from head domains or tail domains. Secondly, we formulate a light-weighted Residual Balancing Mapping (RBM) block to balance the domain distribution by adjusting the network according to DFI. Finally, we propose a Domain Balancing Margin (DBM) in the loss function to further optimize the feature space of the tail domains to improve generalization. Extensive analysis and experiments on several face recognition benchmarks demonstrate that the proposed method effectively enhances the generalization capacities and achieves superior performance.