 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANID: How Far Are We? Evaluating the Discrepancies Between AI-synthesized Images and Natural Images through Multimodal Guidance
Dec 23, 2024In the rapidly evolving field of Artificial Intelligence Generated Content (AIGC), one of the key challenges is distinguishing AI-synthesized images from natural images. Despite the remarkable capabilities of advanced AI generative models in producing visually compelling images, significant discrepancies remain when these images are compared to natural ones. To systematically investigate and quantify these discrepancies, we introduce an AI-Natural Image Discrepancy Evaluation benchmark aimed at addressing the critical question: \textit{how far are AI-generated images (AIGIs) from truly realistic images?} We have constructed a large-scale multimodal dataset, the Distinguishing Natural and AI-generated Images (DNAI) dataset, which includes over 440,000 AIGI samples generated by 8 representative models using both unimodal and multimodal prompts, such as Text-to-Image (T2I), Image-to-Image (I2I), and Text \textit{vs.} Image-to-Image (TI2I). Our fine-grained assessment framework provides a comprehensive evaluation of the DNAI dataset across five key dimensions: naive visual feature quality, semantic alignment in multimodal generation, aesthetic appeal, downstream task applicability, and coordinated human validation. Extensive evaluation results highlight significant discrepancies across these dimensions, underscoring the necessity of aligning quantitative metrics with human judgment to achieve a holistic understanding of AI-generated image quality. Code is available at \href{https://github.com/ryliu68/ANID}{https://github.com/ryliu68/ANID}.
Knowledge Probing for Graph Representation Learning
Aug 07, 2024Graph learning methods have been extensively applied in diverse application areas. However, what kind of inherent graph properties e.g. graph proximity, graph structural information has been encoded into graph representation learning for downstream tasks is still under-explored. In this paper, we propose a novel graph probing framework (GraphProbe) to investigate and interpret whether the family of graph learning methods has encoded different levels of knowledge in graph representation learning. Based on the intrinsic properties of graphs, we design three probes to systematically investigate the graph representation learning process from different perspectives, respectively the node-wise level, the path-wise level, and the structural level. We construct a thorough evaluation benchmark with nine representative graph learning methods from random walk based approaches, basic graph neural networks and self-supervised graph methods, and probe them on six benchmark datasets for node classification, link prediction and graph classification. The experimental evaluation verify that GraphProbe can estimate the capability of graph representation learning. Remaking results have been concluded: GCN and WeightedGCN methods are relatively versatile methods achieving better results with respect to different tasks.
Revisiting Knowledge Distillation under Distribution Shift
Jan 07, 2024Knowledge distillation transfers knowledge from large models into small models, and has recently made remarkable achievements. However, few studies has investigated the mechanism of knowledge distillation against distribution shift. Distribution shift refers to the data distribution drifts between training and testing phases. In this paper, we reconsider the paradigm of knowledge distillation by reformulating the objective function in shift situations. Under the real scenarios, we propose a unified and systematic framework to benchmark knowledge distillation against two general distributional shifts including diversity and correlation shift. The evaluation benchmark covers more than 30 methods from algorithmic, data-driven, and optimization perspectives for five benchmark datasets. Overall, we conduct extensive experiments on the student model. We reveal intriguing observations of poor teaching performance under distribution shifts; in particular, complex algorithms and data augmentation offer limited gains in many cases.
TFDNet: Time-Frequency Enhanced Decomposed Network for Long-term Time Series Forecasting
Aug 25, 2023


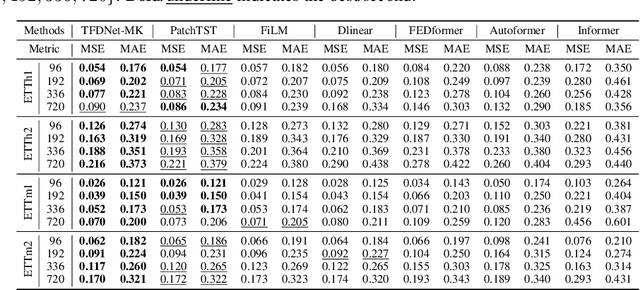
Long-term time series forecasting is a vital task and has a wide range of real applications. Recent methods focus on capturing the underlying patterns from one single domain (e.g. the time domain or the frequency domain), and have not taken a holistic view to process long-term time series from the time-frequency domains. In this paper, we propose a Time-Frequency Enhanced Decomposed Network (TFDNet) to capture both the long-term underlying patterns and temporal periodicity from the time-frequency domain. In TFDNet, we devise a multi-scale time-frequency enhanced encoder backbone and develop two separate trend and seasonal time-frequency blocks to capture the distinct patterns within the decomposed trend and seasonal components in multi-resolutions. Diverse kernel learning strategies of the kernel operations in time-frequency blocks have been explored, by investigating and incorporating the potential different channel-wise correlation patterns of multivariate time series. Experimental evaluation of eight datasets from five benchmark domains demonstrated that TFDNet is superior to state-of-the-art approaches in both effectiveness and efficiency.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023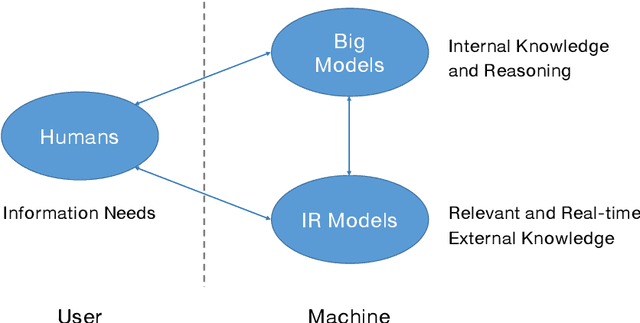
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.