 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATA: Continual Machine Unlearning via Conflict-Averse Task Arithmetic
May 18, 2026Vision-language models (VLMs) have shown remarkable ability in aligning visual and textual representations, enabling a wide range of multimodal applications. However, their large-scale training data inevitably raises concerns about privacy, copyright, and undesirable content, creating a strong need for machine unlearning. While existing studies mainly focus on single-shot unlearning, practical VLM deployment often involves sequential removal requests over time, giving rise to continual machine unlearning. In this work, we make the first attempt to study continual unlearning for VLMs and identify three key challenges in this setting: effectiveness in removing target knowledge, fidelity in preserving retained model utility, and persistence in preventing knowledge re-emergence under sequential updates. To address these challenges, we propose CATA, a conflict-averse task arithmetic method that represents each forget request as an unlearning task vector. By maintaining historical task vectors and performing sign-aware conflict-averse aggregation, CATA suppresses conflicting update components that may weaken previous forgetting effects. Extensive experiments under both single-shot and continual settings show that CATA outperforms baselines in terms of forgetting effectiveness, model fidelity, and forgetting persistence.
Revisiting Knowledge Distillation under Distribution Shift
Jan 07, 2024Knowledge distillation transfers knowledge from large models into small models, and has recently made remarkable achievements. However, few studies has investigated the mechanism of knowledge distillation against distribution shift. Distribution shift refers to the data distribution drifts between training and testing phases. In this paper, we reconsider the paradigm of knowledge distillation by reformulating the objective function in shift situations. Under the real scenarios, we propose a unified and systematic framework to benchmark knowledge distillation against two general distributional shifts including diversity and correlation shift. The evaluation benchmark covers more than 30 methods from algorithmic, data-driven, and optimization perspectives for five benchmark datasets. Overall, we conduct extensive experiments on the student model. We reveal intriguing observations of poor teaching performance under distribution shifts; in particular, complex algorithms and data augmentation offer limited gains in many cases.
SAME: Sample Reconstruction Against Model Extraction Attacks
Dec 17, 2023While deep learning models have shown significant performance across various domains, their deployment needs extensive resources and advanced computing infrastructure. As a solution, Machine Learning as a Service (MLaaS) has emerged, lowering the barriers for users to release or productize their deep learning models. However, previous studies have highlighted potential privacy and security concerns associated with MLaaS, and one primary threat is model extraction attacks. To address this, there are many defense solutions but they suffer from unrealistic assumptions and generalization issues, making them less practical for reliable protection. Driven by these limitations, we introduce a novel defense mechanism, SAME, based on the concept of sample reconstruction. This strategy imposes minimal prerequisites on the defender's capabilities, eliminating the need for auxiliary Out-of-Distribution (OOD) datasets, user query history, white-box model access, and additional intervention during model training. It is compatible with existing active defense methods. Our extensive experiments corroborate the superior efficacy of SAME over state-of-the-art solutions. Our code is available at https://github.com/xythink/SAME.
Deep Hierarchy Quantization Compression algorithm based on Dynamic Sampling
Dec 30, 2022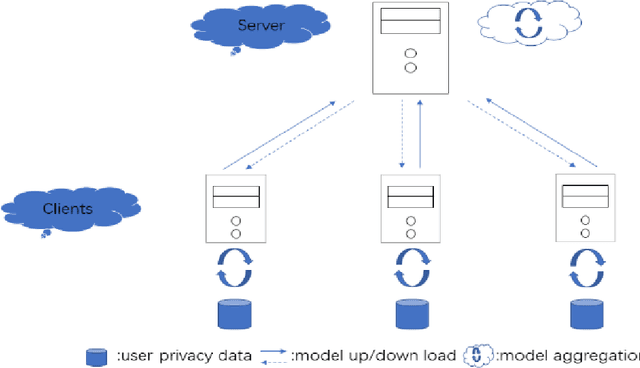
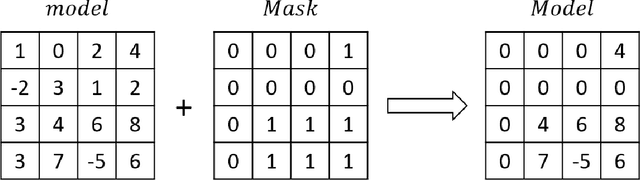
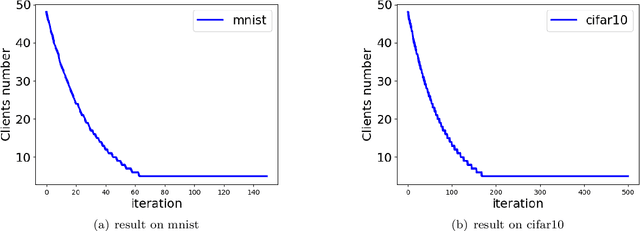
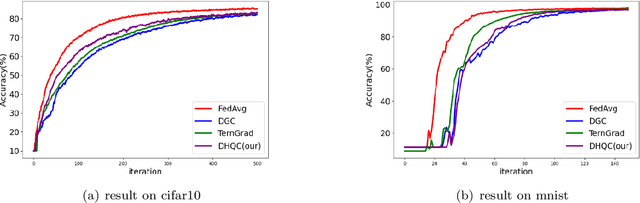
Unlike traditional distributed machine learning, federated learning stores data locally for training and then aggregates the models on the server, which solves the data security problem that may arise in traditional distributed machine learning. However, during the training process, the transmission of model parameters can impose a significant load on the network bandwidth. It has been pointed out that the vast majority of model parameters are redundant during model parameter transmission. In this paper, we explore the data distribution law of selected partial model parameters on this basis, and propose a deep hierarchical quantization compression algorithm, which further compresses the model and reduces the network load brought by data transmission through the hierarchical quantization of model parameters. And we adopt a dynamic sampling strategy for the selection of clients to accelerate the convergence of the model. Experimental results on different public datasets demonstrate the effectiveness of our algorithm.
Privacy Inference Attacks and Defenses in Cloud-based Deep Neural Network: A Survey
May 13, 2021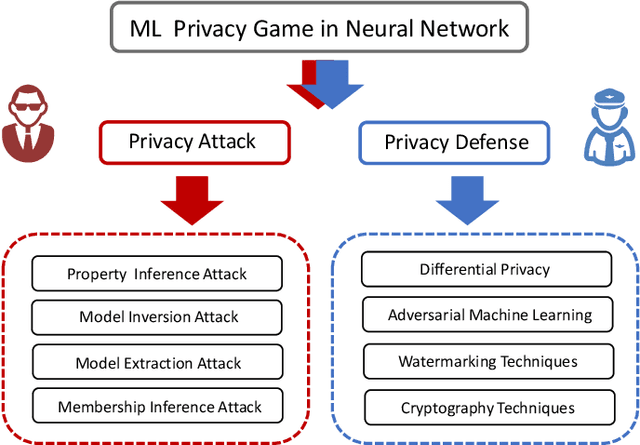
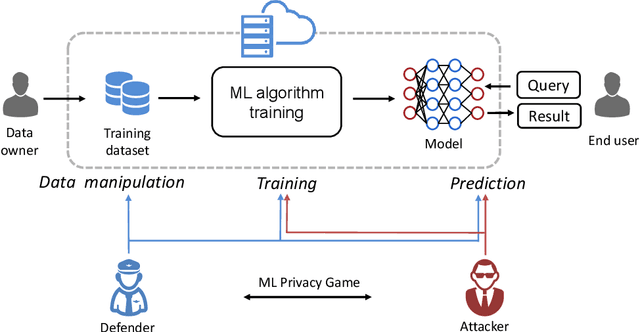
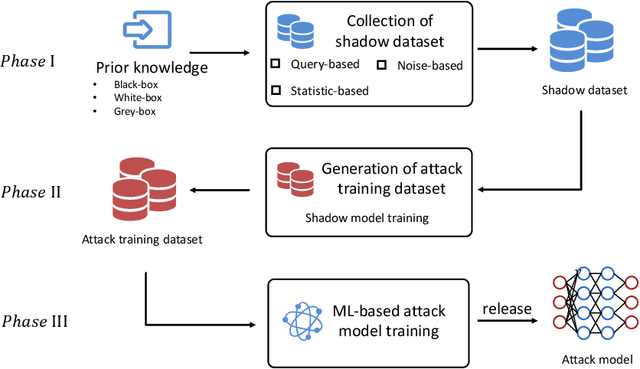
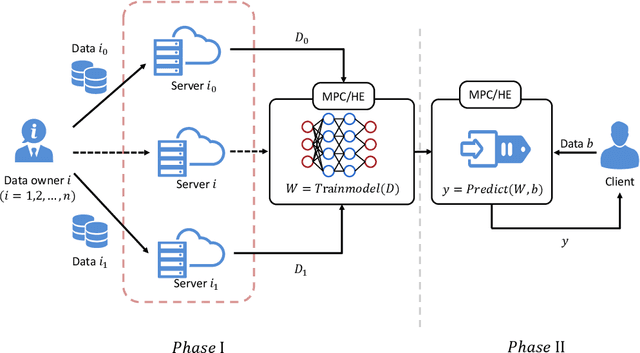
Deep Neural Network (DNN), one of the most powerful machine learning algorithms, is increasingly leveraged to overcome the bottleneck of effectively exploring and analyzing massive data to boost advanced scientific development. It is not a surprise that cloud computing providers offer the cloud-based DNN as an out-of-the-box service. Though there are some benefits from the cloud-based DNN, the interaction mechanism among two or multiple entities in the cloud inevitably induces new privacy risks. This survey presents the most recent findings of privacy attacks and defenses appeared in cloud-based neural network services. We systematically and thoroughly review privacy attacks and defenses in the pipeline of cloud-based DNN service, i.e., data manipulation, training, and prediction. In particular, a new theory, called cloud-based ML privacy game, is extracted from the recently published literature to provide a deep understanding of state-of-the-art research. Finally, the challenges and future work are presented to help researchers to continue to push forward the competitions between privacy attackers and defenders.