 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning at the Forefront of Fairness: A Multifaceted Perspective
Jan 31, 2026Fairness in Federated Learning (FL) is emerging as a critical factor driven by heterogeneous clients' constraints and balanced model performance across various scenarios. In this survey, we delineate a comprehensive classification of the state-of-the-art fairness-aware approaches from a multifaceted perspective, i.e., model performance-oriented and capability-oriented. Moreover, we provide a framework to categorize and address various fairness concerns and associated technical aspects, examining their effectiveness in balancing equity and performance within FL frameworks. We further examine several significant evaluation metrics leveraged to measure fairness quantitatively. Finally, we explore exciting open research directions and propose prospective solutions that could drive future advancements in this important area, laying a solid foundation for researchers working toward fairness in FL.
Siamese Foundation Models for Crystal Structure Prediction
Mar 13, 2025



Crystal Structure Prediction (CSP), which aims to generate stable crystal structures from compositions, represents a critical pathway for discovering novel materials. While structure prediction tasks in other domains, such as proteins, have seen remarkable progress, CSP remains a relatively underexplored area due to the more complex geometries inherent in crystal structures. In this paper, we propose Siamese foundation models specifically designed to address CSP. Our pretrain-finetune framework, named DAO, comprises two complementary foundation models: DAO-G for structure generation and DAO-P for energy prediction. Experiments on CSP benchmarks (MP-20 and MPTS-52) demonstrate that our DAO-G significantly surpasses state-of-the-art (SOTA) methods across all metrics. Extensive ablation studies further confirm that DAO-G excels in generating diverse polymorphic structures, and the dataset relaxation and energy guidance provided by DAO-P are essential for enhancing DAO-G's performance. When applied to three real-world superconductors ($\text{CsV}_3\text{Sb}_5$, $ \text{Zr}_{16}\text{Rh}_8\text{O}_4$ and $\text{Zr}_{16}\text{Pd}_8\text{O}_4$) that are known to be challenging to analyze, our foundation models achieve accurate critical temperature predictions and structure generations. For instance, on $\text{CsV}_3\text{Sb}_5$, DAO-G generates a structure close to the experimental one with an RMSE of 0.0085; DAO-P predicts the $T_c$ value with high accuracy (2.26 K vs. the ground-truth value of 2.30 K). In contrast, conventional DFT calculators like Quantum Espresso only successfully derive the structure of the first superconductor within an acceptable time, while the RMSE is nearly 8 times larger, and the computation speed is more than 1000 times slower. These compelling results collectively highlight the potential of our approach for advancing materials science research and development.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
BGTplanner: Maximizing Training Accuracy for Differentially Private Federated Recommenders via Strategic Privacy Budget Allocation
Dec 04, 2024



To mitigate the rising concern about privacy leakage, the federated recommender (FR) paradigm emerges, in which decentralized clients co-train the recommendation model without exposing their raw user-item rating data. The differentially private federated recommender (DPFR) further enhances FR by injecting differentially private (DP) noises into clients. Yet, current DPFRs, suffering from noise distortion, cannot achieve satisfactory accuracy. Various efforts have been dedicated to improving DPFRs by adaptively allocating the privacy budget over the learning process. However, due to the intricate relation between privacy budget allocation and model accuracy, existing works are still far from maximizing DPFR accuracy. To address this challenge, we develop BGTplanner (Budget Planner) to strategically allocate the privacy budget for each round of DPFR training, improving overall training performance. Specifically, we leverage the Gaussian process regression and historical information to predict the change in recommendation accuracy with a certain allocated privacy budget. Additionally, Contextual Multi-Armed Bandit (CMAB) is harnessed to make privacy budget allocation decisions by reconciling the current improvement and long-term privacy constraints. Our extensive experimental results on real datasets demonstrate that \emph{BGTplanner} achieves an average improvement of 6.76\% in training performance compared to state-of-the-art baselines.
A Communication and Computation Efficient Fully First-order Method for Decentralized Bilevel Optimization
Oct 18, 2024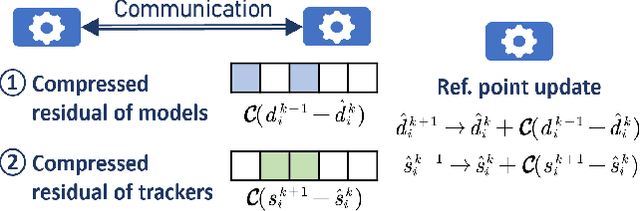


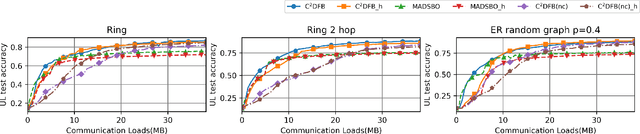
Bilevel optimization, crucial for hyperparameter tuning, meta-learning and reinforcement learning, remains less explored in the decentralized learning paradigm, such as decentralized federated learning (DFL). Typically, decentralized bilevel methods rely on both gradients and Hessian matrices to approximate hypergradients of upper-level models. However, acquiring and sharing the second-order oracle is compute and communication intensive. % and sharing this information incurs heavy communication overhead. To overcome these challenges, this paper introduces a fully first-order decentralized method for decentralized Bilevel optimization, $\text{C}^2$DFB which is both compute- and communicate-efficient. In $\text{C}^2$DFB, each learning node optimizes a min-min-max problem to approximate hypergradient by exclusively using gradients information. To reduce the traffic load at the inner-loop of solving the lower-level problem, $\text{C}^2$DFB incorporates a lightweight communication protocol for efficiently transmitting compressed residuals of local parameters. % during the inner loops. Rigorous theoretical analysis ensures its convergence % of the algorithm, indicating a first-order oracle calls of $\tilde{\mathcal{O}}(\epsilon^{-4})$. Experiments on hyperparameter tuning and hyper-representation tasks validate the superiority of $\text{C}^2$DFB across various typologies and heterogeneous data distributions.
Snapshot: Towards Application-centered Models for Pedestrian Trajectory Prediction in Urban Traffic Environments
Sep 03, 2024



This paper explores pedestrian trajectory prediction in urban traffic while focusing on both model accuracy and real-world applicability. While promising approaches exist, they are often not publicly available, revolve around pedestrian datasets excluding traffic-related information, or resemble architectures that are either not real-time capable or robust. To address these limitations, we first introduce a dedicated benchmark based on Argoverse 2, specifically targeting pedestrians in urban settings. Following this, we present Snapshot, a modular, feed-forward neural network that outperforms the current state of the art while utilizing significantly less information. Despite its agent-centric encoding scheme, Snapshot demonstrates scalability, real-time performance, and robustness to varying motion histories. Moreover, by integrating Snapshot into a modular autonomous driving software stack, we showcase its real-world applicability
Mitigating Noise Detriment in Differentially Private Federated Learning with Model Pre-training
Aug 18, 2024



Pre-training exploits public datasets to pre-train an advanced machine learning model, so that the model can be easily tuned to adapt to various downstream tasks. Pre-training has been extensively explored to mitigate computation and communication resource consumption. Inspired by these advantages, we are the first to explore how model pre-training can mitigate noise detriment in differentially private federated learning (DPFL). DPFL is upgraded from federated learning (FL), the de-facto standard for privacy preservation when training the model across multiple clients owning private data. DPFL introduces differentially private (DP) noises to obfuscate model gradients exposed in FL, which however can considerably impair model accuracy. In our work, we compare head fine-tuning (HT) and full fine-tuning (FT), which are based on pre-training, with scratch training (ST) in DPFL through a comprehensive empirical study. Our experiments tune pre-trained models (obtained by pre-training on ImageNet-1K) with CIFAR-10, CHMNIST and Fashion-MNIST (FMNIST) datasets, respectively. The results demonstrate that HT and FT can significantly mitigate noise influence by diminishing gradient exposure times. In particular, HT outperforms FT when the privacy budget is tight or the model size is large. Visualization and explanation study further substantiates our findings. Our pioneering study introduces a new perspective on enhancing DPFL and expanding its practical applications.
The Power of Bias: Optimizing Client Selection in Federated Learning with Heterogeneous Differential Privacy
Aug 16, 2024
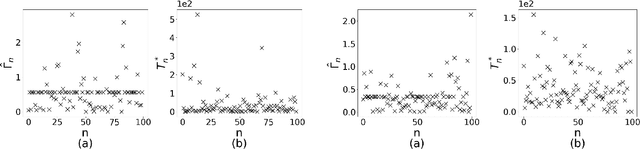
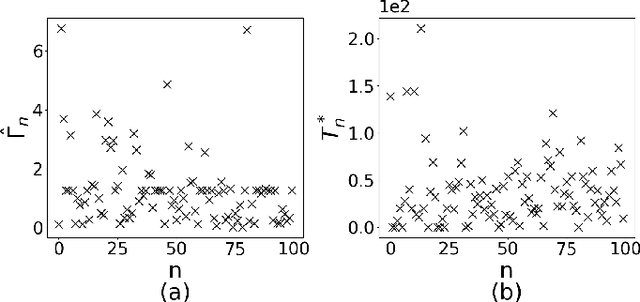
To preserve the data privacy, the federated learning (FL) paradigm emerges in which clients only expose model gradients rather than original data for conducting model training. To enhance the protection of model gradients in FL, differentially private federated learning (DPFL) is proposed which incorporates differentially private (DP) noises to obfuscate gradients before they are exposed. Yet, an essential but largely overlooked problem in DPFL is the heterogeneity of clients' privacy requirement, which can vary significantly between clients and extremely complicates the client selection problem in DPFL. In other words, both the data quality and the influence of DP noises should be taken into account when selecting clients. To address this problem, we conduct convergence analysis of DPFL under heterogeneous privacy, a generic client selection strategy, popular DP mechanisms and convex loss. Based on convergence analysis, we formulate the client selection problem to minimize the value of loss function in DPFL with heterogeneous privacy, which is a convex optimization problem and can be solved efficiently. Accordingly, we propose the DPFL-BCS (biased client selection) algorithm. The extensive experiment results with real datasets under both convex and non-convex loss functions indicate that DPFL-BCS can remarkably improve model utility compared with the SOTA baselines.
Fed-CVLC: Compressing Federated Learning Communications with Variable-Length Codes
Feb 06, 2024



In Federated Learning (FL) paradigm, a parameter server (PS) concurrently communicates with distributed participating clients for model collection, update aggregation, and model distribution over multiple rounds, without touching private data owned by individual clients. FL is appealing in preserving data privacy; yet the communication between the PS and scattered clients can be a severe bottleneck. Model compression algorithms, such as quantization and sparsification, have been suggested but they generally assume a fixed code length, which does not reflect the heterogeneity and variability of model updates. In this paper, through both analysis and experiments, we show strong evidences that variable-length is beneficial for compression in FL. We accordingly present Fed-CVLC (Federated Learning Compression with Variable-Length Codes), which fine-tunes the code length in response of the dynamics of model updates. We develop optimal tuning strategy that minimizes the loss function (equivalent to maximizing the model utility) subject to the budget for communication. We further demonstrate that Fed-CVLC is indeed a general compression design that bridges quantization and sparsification, with greater flexibility. Extensive experiments have been conducted with public datasets to demonstrate that Fed-CVLC remarkably outperforms state-of-the-art baselines, improving model utility by 1.50%-5.44%, or shrinking communication traffic by 16.67%-41.61%.
Expediting In-Network Federated Learning by Voting-Based Consensus Model Compression
Feb 06, 2024



Recently, federated learning (FL) has gained momentum because of its capability in preserving data privacy. To conduct model training by FL, multiple clients exchange model updates with a parameter server via Internet. To accelerate the communication speed, it has been explored to deploy a programmable switch (PS) in lieu of the parameter server to coordinate clients. The challenge to deploy the PS in FL lies in its scarce memory space, prohibiting running memory consuming aggregation algorithms on the PS. To overcome this challenge, we propose Federated Learning in-network Aggregation with Compression (FediAC) algorithm, consisting of two phases: client voting and model aggregating. In the former phase, clients report their significant model update indices to the PS to estimate global significant model updates. In the latter phase, clients upload global significant model updates to the PS for aggregation. FediAC consumes much less memory space and communication traffic than existing works because the first phase can guarantee consensus compression across clients. The PS easily aligns model update indices to swiftly complete aggregation in the second phase. Finally, we conduct extensive experiments by using public datasets to demonstrate that FediAC remarkably surpasses the state-of-the-art baselines in terms of model accuracy and communication traffic.