 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-to-Head autonomous racing at the limits of handling in the A2RL challenge
Feb 09, 2026Autonomous racing presents a complex challenge involving multi-agent interactions between vehicles operating at the limit of performance and dynamics. As such, it provides a valuable research and testing environment for advancing autonomous driving technology and improving road safety. This article presents the algorithms and deployment strategies developed by the TUM Autonomous Motorsport team for the inaugural Abu Dhabi Autonomous Racing League (A2RL). We showcase how our software emulates human driving behavior, pushing the limits of vehicle handling and multi-vehicle interactions to win the A2RL. Finally, we highlight the key enablers of our success and share our most significant learnings.
Analyzing the Impact of Simulation Fidelity on the Evaluation of Autonomous Driving Motion Control
Feb 08, 2026Simulation is crucial in the development of autonomous driving software. In particular, assessing control algorithms requires an accurate vehicle dynamics simulation. However, recent publications use models with varying levels of detail. This disparity makes it difficult to compare individual control algorithms. Therefore, this paper aims to investigate the influence of the fidelity of vehicle dynamics modeling on the closed-loop behavior of trajectory-following controllers. For this purpose, we introduce a comprehensive Autoware-compatible vehicle model. By simplifying this, we derive models with varying fidelity. Evaluating over 550 simulation runs allows us to quantify each model's approximation quality compared to real-world data. Furthermore, we investigate whether the influence of model simplifications changes with varying margins to the acceleration limit of the vehicle. From this, we deduce to which degree a vehicle model can be simplified to evaluate control algorithms depending on the specific application. The real-world data used to validate the simulation environment originate from the Indy Autonomous Challenge race at the Autodromo Nazionale di Monza in June 2023. They show the fastest fully autonomous lap of TUM Autonomous Motorsport, with vehicle speeds reaching 267 kph and lateral accelerations of up to 15 mps2.
FlowCalib: LiDAR-to-Vehicle Miscalibration Detection using Scene Flows
Jan 30, 2026Accurate sensor-to-vehicle calibration is essential for safe autonomous driving. Angular misalignments of LiDAR sensors can lead to safety-critical issues during autonomous operation. However, current methods primarily focus on correcting sensor-to-sensor errors without considering the miscalibration of individual sensors that cause these errors in the first place. We introduce FlowCalib, the first framework that detects LiDAR-to-vehicle miscalibration using motion cues from the scene flow of static objects. Our approach leverages the systematic bias induced by rotational misalignment in the flow field generated from sequential 3D point clouds, eliminating the need for additional sensors. The architecture integrates a neural scene flow prior for flow estimation and incorporates a dual-branch detection network that fuses learned global flow features with handcrafted geometric descriptors. These combined representations allow the system to perform two complementary binary classification tasks: a global binary decision indicating whether misalignment is present and separate, axis-specific binary decisions indicating whether each rotational axis is misaligned. Experiments on the nuScenes dataset demonstrate FlowCalib's ability to robustly detect miscalibration, establishing a benchmark for sensor-to-vehicle miscalibration detection.
RSLCPP -- Deterministic Simulations Using ROS 2
Jan 11, 2026Simulation is crucial in real-world robotics, offering safe, scalable, and efficient environments for developing applications, ranging from humanoid robots to autonomous vehicles and drones. While the Robot Operating System (ROS) has been widely adopted as the backbone of these robotic applications in both academia and industry, its asynchronous, multiprocess design complicates reproducibility, especially across varying hardware platforms. Deterministic callback execution cannot be guaranteed when computation times and communication delays vary. This lack of reproducibility complicates scientific benchmarking and continuous integration, where consistent results are essential. To address this, we present a methodology to create deterministic simulations using ROS 2 nodes. Our ROS Simulation Library for C++ (RSLCPP) implements this approach, enabling existing nodes to be combined into a simulation routine that yields reproducible results without requiring any code changes. We demonstrate that our approach yields identical results across various CPUs and architectures when testing both a synthetic benchmark and a real-world robotics system. RSLCPP is open-sourced at https://github.com/TUMFTM/rslcpp.
Calibrating the Full Predictive Class Distribution of 3D Object Detectors for Autonomous Driving
Oct 02, 2025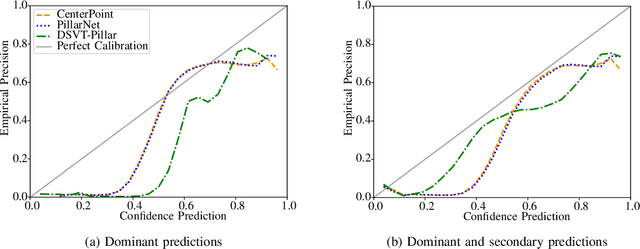
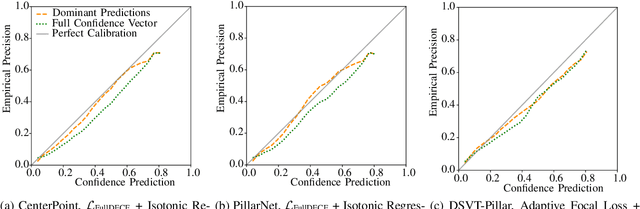

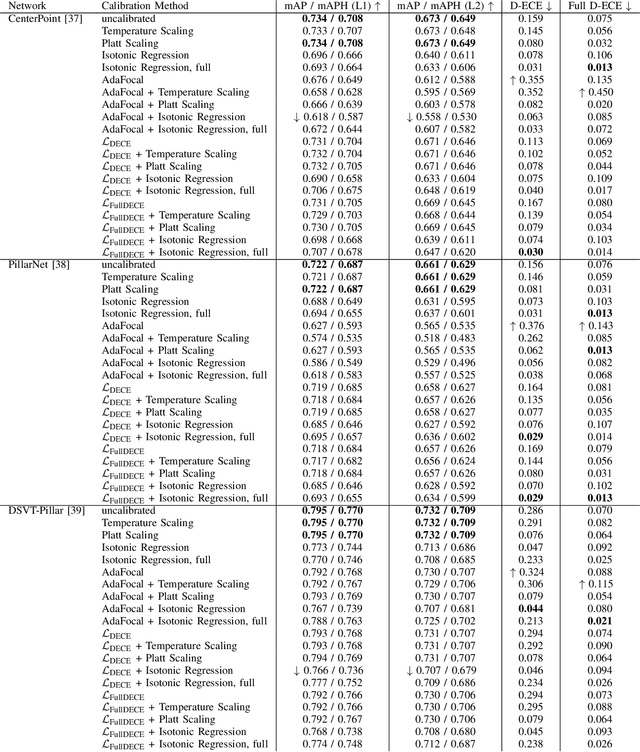
In autonomous systems, precise object detection and uncertainty estimation are critical for self-aware and safe operation. This work addresses confidence calibration for the classification task of 3D object detectors. We argue that it is necessary to regard the calibration of the full predictive confidence distribution over all classes and deduce a metric which captures the calibration of dominant and secondary class predictions. We propose two auxiliary regularizing loss terms which introduce either calibration of the dominant prediction or the full prediction vector as a training goal. We evaluate a range of post-hoc and train-time methods for CenterPoint, PillarNet and DSVT-Pillar and find that combining our loss term, which regularizes for calibration of the full class prediction, and isotonic regression lead to the best calibration of CenterPoint and PillarNet with respect to both dominant and secondary class predictions. We further find that DSVT-Pillar can not be jointly calibrated for dominant and secondary predictions using the same method.
To New Beginnings: A Survey of Unified Perception in Autonomous Vehicle Software
Aug 28, 2025Autonomous vehicle perception typically relies on modular pipelines that decompose the task into detection, tracking, and prediction. While interpretable, these pipelines suffer from error accumulation and limited inter-task synergy. Unified perception has emerged as a promising paradigm that integrates these sub-tasks within a shared architecture, potentially improving robustness, contextual reasoning, and efficiency while retaining interpretable outputs. In this survey, we provide a comprehensive overview of unified perception, introducing a holistic and systemic taxonomy that categorizes methods along task integration, tracking formulation, and representation flow. We define three paradigms -Early, Late, and Full Unified Perception- and systematically review existing methods, their architectures, training strategies, datasets used, and open-source availability, while highlighting future research directions. This work establishes the first comprehensive framework for understanding and advancing unified perception, consolidates fragmented efforts, and guides future research toward more robust, generalizable, and interpretable perception.
VESPA: Towards un(Human)supervised Open-World Pointcloud Labeling for Autonomous Driving
Jul 27, 2025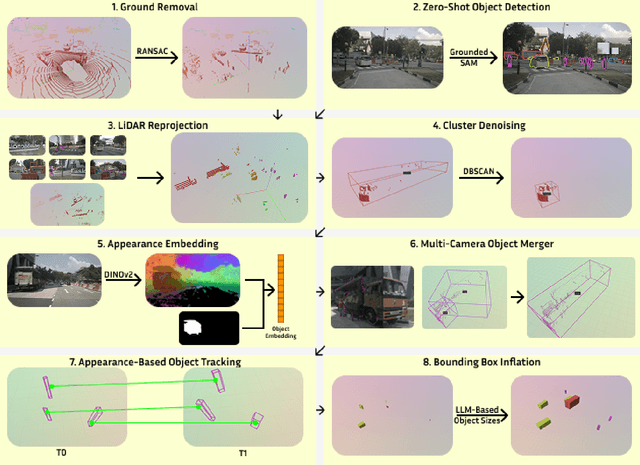



Data collection for autonomous driving is rapidly accelerating, but manual annotation, especially for 3D labels, remains a major bottleneck due to its high cost and labor intensity. Autolabeling has emerged as a scalable alternative, allowing the generation of labels for point clouds with minimal human intervention. While LiDAR-based autolabeling methods leverage geometric information, they struggle with inherent limitations of lidar data, such as sparsity, occlusions, and incomplete object observations. Furthermore, these methods typically operate in a class-agnostic manner, offering limited semantic granularity. To address these challenges, we introduce VESPA, a multimodal autolabeling pipeline that fuses the geometric precision of LiDAR with the semantic richness of camera images. Our approach leverages vision-language models (VLMs) to enable open-vocabulary object labeling and to refine detection quality directly in the point cloud domain. VESPA supports the discovery of novel categories and produces high-quality 3D pseudolabels without requiring ground-truth annotations or HD maps. On Nuscenes dataset, VESPA achieves an AP of 52.95% for object discovery and up to 46.54% for multiclass object detection, demonstrating strong performance in scalable 3D scene understanding. Code will be available upon acceptance.
HeAL3D: Heuristical-enhanced Active Learning for 3D Object Detection
May 01, 2025


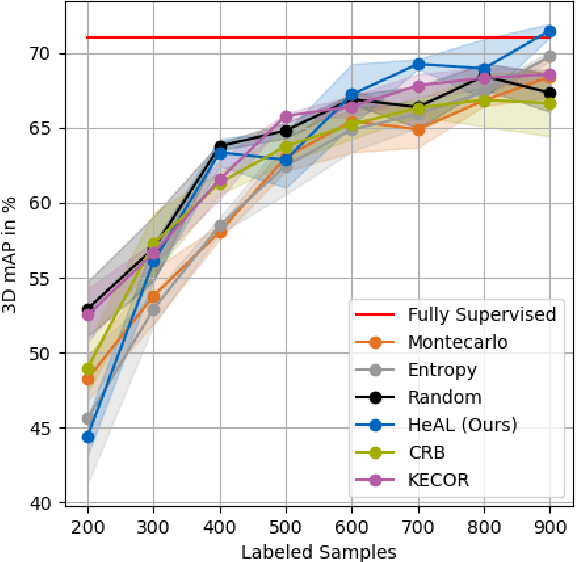
Active Learning has proved to be a relevant approach to perform sample selection for training models for Autonomous Driving. Particularly, previous works on active learning for 3D object detection have shown that selection of samples in uncontrolled scenarios is challenging. Furthermore, current approaches focus exclusively on the theoretical aspects of the sample selection problem but neglect the practical insights that can be obtained from the extensive literature and application of 3D detection models. In this paper, we introduce HeAL (Heuristical-enhanced Active Learning for 3D Object Detection) which integrates those heuristical features together with Localization and Classification to deliver the most contributing samples to the model's training. In contrast to previous works, our approach integrates heuristical features such as object distance and point-quantity to estimate the uncertainty, which enhance the usefulness of selected samples to train detection models. Our quantitative evaluation on KITTI shows that HeAL presents competitive mAP with respect to the State-of-the-Art, and achieves the same mAP as the full-supervised baseline with only 24% of the samples.
Inconsistency-based Active Learning for LiDAR Object Detection
May 01, 2025Deep learning models for object detection in autonomous driving have recently achieved impressive performance gains and are already being deployed in vehicles worldwide. However, current models require increasingly large datasets for training. Acquiring and labeling such data is costly, necessitating the development of new strategies to optimize this process. Active learning is a promising approach that has been extensively researched in the image domain. In our work, we extend this concept to the LiDAR domain by developing several inconsistency-based sample selection strategies and evaluate their effectiveness in various settings. Our results show that using a naive inconsistency approach based on the number of detected boxes, we achieve the same mAP as the random sampling strategy with 50% of the labeled data.
V3LMA: Visual 3D-enhanced Language Model for Autonomous Driving
Apr 30, 2025Large Vision Language Models (LVLMs) have shown strong capabilities in understanding and analyzing visual scenes across various domains. However, in the context of autonomous driving, their limited comprehension of 3D environments restricts their effectiveness in achieving a complete and safe understanding of dynamic surroundings. To address this, we introduce V3LMA, a novel approach that enhances 3D scene understanding by integrating Large Language Models (LLMs) with LVLMs. V3LMA leverages textual descriptions generated from object detections and video inputs, significantly boosting performance without requiring fine-tuning. Through a dedicated preprocessing pipeline that extracts 3D object data, our method improves situational awareness and decision-making in complex traffic scenarios, achieving a score of 0.56 on the LingoQA benchmark. We further explore different fusion strategies and token combinations with the goal of advancing the interpretation of traffic scenes, ultimately enabling safer autonomous driving systems.