 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeadline-Aware Online Scheduling for LLM Fine-Tuning with Spot Market Predictions
Dec 24, 2025



As foundation models grow in size, fine-tuning them becomes increasingly expensive. While GPU spot instances offer a low-cost alternative to on-demand resources, their volatile prices and availability make deadline-aware scheduling particularly challenging. We tackle this difficulty by using a mix of spot and on-demand instances. Distinctively, we show the predictability of prices and availability in a spot instance market, the power of prediction in enabling cost-efficient scheduling and its sensitivity to estimation errors. An integer programming problem is formulated to capture the use of mixed instances under both the price and availability dynamics. We propose an online allocation algorithm with prediction based on the committed horizon control approach that leverages a \emph{commitment level} to enforce the partial sequence of decisions. When this prediction becomes inaccurate, we further present a complementary online algorithm without predictions. An online policy selection algorithm is developed that learns the best policy from a pool constructed by varying the parameters of both algorithms. We prove that the prediction-based algorithm achieves tighter performance bounds as prediction error decreases, while the policy selection algorithm possesses a regret bound of $\mathcal{O}(\sqrt{T})$. Experimental results demonstrate that our online framework can adaptively select the best policy under varying spot market dynamics and prediction quality, consistently outperforming baselines and improving utility by up to 54.8\%.
A Communication and Computation Efficient Fully First-order Method for Decentralized Bilevel Optimization
Oct 18, 2024


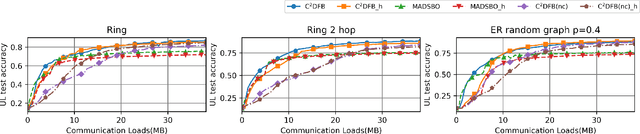
Bilevel optimization, crucial for hyperparameter tuning, meta-learning and reinforcement learning, remains less explored in the decentralized learning paradigm, such as decentralized federated learning (DFL). Typically, decentralized bilevel methods rely on both gradients and Hessian matrices to approximate hypergradients of upper-level models. However, acquiring and sharing the second-order oracle is compute and communication intensive. % and sharing this information incurs heavy communication overhead. To overcome these challenges, this paper introduces a fully first-order decentralized method for decentralized Bilevel optimization, $\text{C}^2$DFB which is both compute- and communicate-efficient. In $\text{C}^2$DFB, each learning node optimizes a min-min-max problem to approximate hypergradient by exclusively using gradients information. To reduce the traffic load at the inner-loop of solving the lower-level problem, $\text{C}^2$DFB incorporates a lightweight communication protocol for efficiently transmitting compressed residuals of local parameters. % during the inner loops. Rigorous theoretical analysis ensures its convergence % of the algorithm, indicating a first-order oracle calls of $\tilde{\mathcal{O}}(\epsilon^{-4})$. Experiments on hyperparameter tuning and hyper-representation tasks validate the superiority of $\text{C}^2$DFB across various typologies and heterogeneous data distributions.
AxiomVision: Accuracy-Guaranteed Adaptive Visual Model Selection for Perspective-Aware Video Analytics
Jul 29, 2024The rapid evolution of multimedia and computer vision technologies requires adaptive visual model deployment strategies to effectively handle diverse tasks and varying environments. This work introduces AxiomVision, a novel framework that can guarantee accuracy by leveraging edge computing to dynamically select the most efficient visual models for video analytics under diverse scenarios. Utilizing a tiered edge-cloud architecture, AxiomVision enables the deployment of a broad spectrum of visual models, from lightweight to complex DNNs, that can be tailored to specific scenarios while considering camera source impacts. In addition, AxiomVision provides three core innovations: (1) a dynamic visual model selection mechanism utilizing continual online learning, (2) an efficient online method that efficiently takes into account the influence of the camera's perspective, and (3) a topology-driven grouping approach that accelerates the model selection process. With rigorous theoretical guarantees, these advancements provide a scalable and effective solution for visual tasks inherent to multimedia systems, such as object detection, classification, and counting. Empirically, AxiomVision achieves a 25.7\% improvement in accuracy.
Hierarchical Reinforcement Learning Empowered Task Offloading in V2I Networks
May 18, 2024Edge computing plays an essential role in the vehicle-to-infrastructure (V2I) networks, where vehicles offload their intensive computation tasks to the road-side units for saving energy and reduce the latency. This paper designs the optimal task offloading policy to address the concerns involving processing delay, energy consumption and edge computing cost. Each computation task consisting of some interdependent sub-tasks is characterized as a directed acyclic graph (DAG). In such dynamic networks, a novel hierarchical Offloading scheme is proposed by leveraging deep reinforcement learning (DRL). The inter-dependencies among the DAGs of the computation tasks are extracted using a graph neural network with attention mechanism. A parameterized DRL algorithm is developed to deal with the hierarchical action space containing both discrete and continuous actions. Simulation results with a real-world car speed dataset demonstrate that the proposed scheme can effectively reduce the system overhead.
Decentralized Stochastic Proximal Gradient Descent with Variance Reduction over Time-varying Networks
Jan 23, 2022
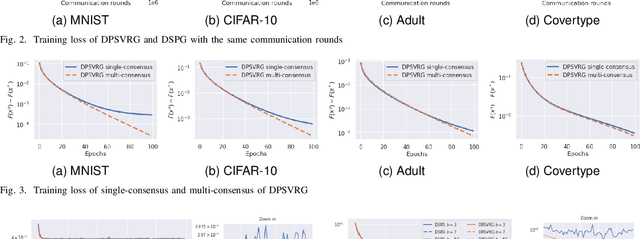

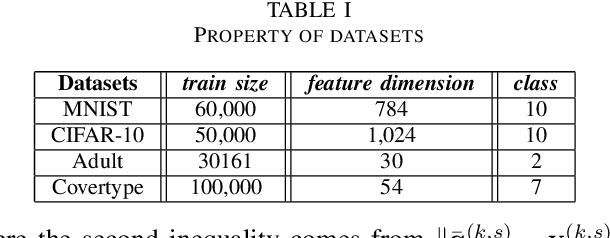
In decentralized learning, a network of nodes cooperate to minimize an overall objective function that is usually the finite-sum of their local objectives, and incorporates a non-smooth regularization term for the better generalization ability. Decentralized stochastic proximal gradient (DSPG) method is commonly used to train this type of learning models, while the convergence rate is retarded by the variance of stochastic gradients. In this paper, we propose a novel algorithm, namely DPSVRG, to accelerate the decentralized training by leveraging the variance reduction technique. The basic idea is to introduce an estimator in each node, which tracks the local full gradient periodically, to correct the stochastic gradient at each iteration. By transforming our decentralized algorithm into a centralized inexact proximal gradient algorithm with variance reduction, and controlling the bounds of error sequences, we prove that DPSVRG converges at the rate of $O(1/T)$ for general convex objectives plus a non-smooth term with $T$ as the number of iterations, while DSPG converges at the rate $O(\frac{1}{\sqrt{T}})$. Our experiments on different applications, network topologies and learning models demonstrate that DPSVRG converges much faster than DSPG, and the loss function of DPSVRG decreases smoothly along with the training epochs.
Toward Packet Routing with Fully-distributed Multi-agent Deep Reinforcement Learning
May 09, 2019
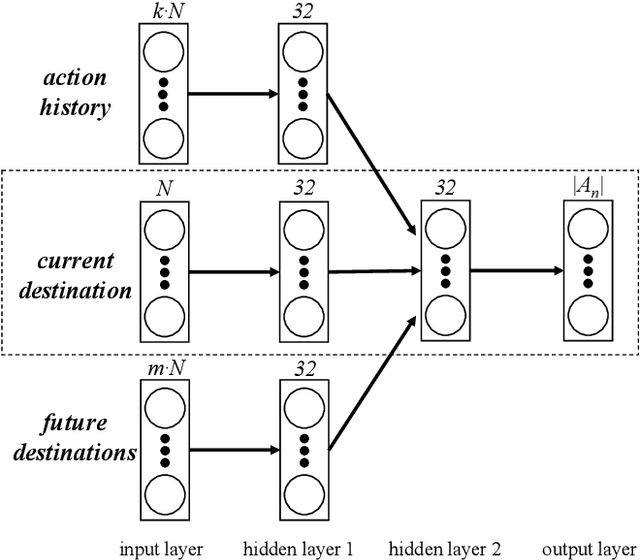
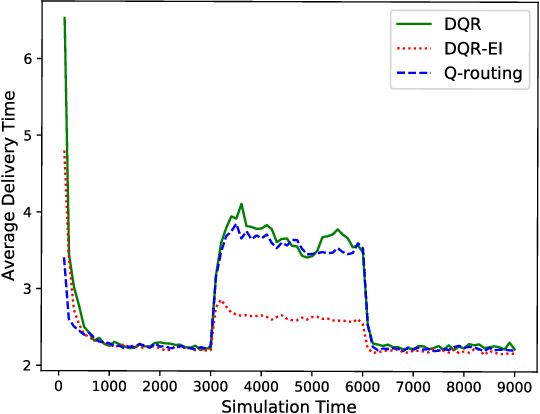
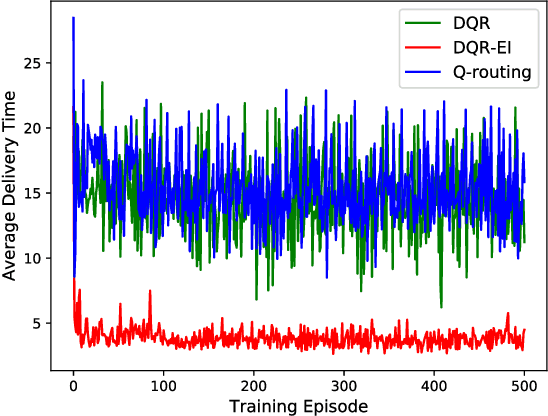
Packet routing is one of the fundamental problems in computer networks in which a router determines the next-hop of each packet in the queue to get it as quickly as possible to its destination. Reinforcement learning has been introduced to design the autonomous packet routing policy namely Q-routing only using local information available to each router. However, the curse of dimensionality of Q-routing prohibits the more comprehensive representation of dynamic network states, thus limiting the potential benefit of reinforcement learning. Inspired by recent success of deep reinforcement learning (DRL), we embed deep neural networks in multi-agent Q-routing. Each router possesses an independent neural network that is trained without communicating with its neighbors and makes decision locally. Two multi-agent DRL-enabled routing algorithms are proposed: one simply replaces Q-table of vanilla Q-routing by a deep neural network, and the other further employs extra information including the past actions and the destinations of non-head of line packets. Our simulation manifests that the direct substitution of Q-table by a deep neural network may not yield minimal delivery delays because the neural network does not learn more from the same input. When more information is utilized, adaptive routing policy can converge and significantly reduce the packet delivery time.
* 8 pages, 9 figures
Deep Reinforcement Learning for Multi-Resource Multi-Machine Job Scheduling
Nov 20, 2017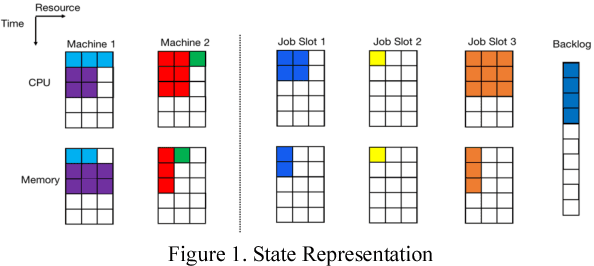
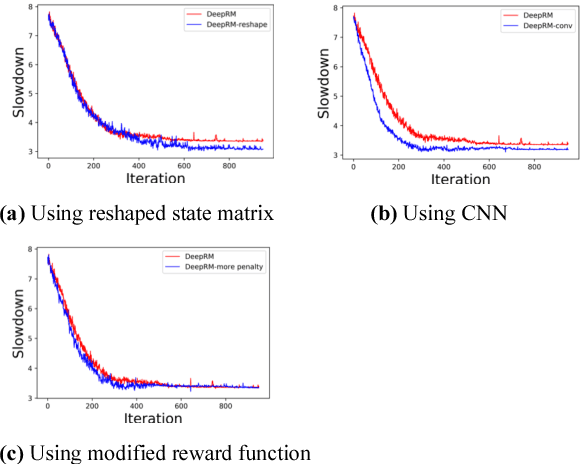
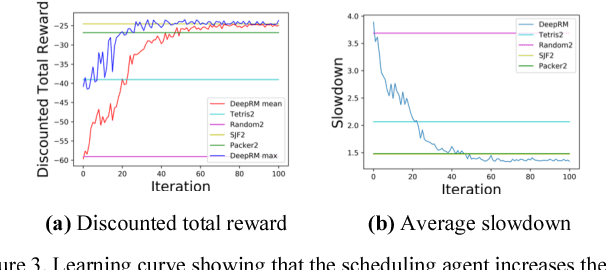
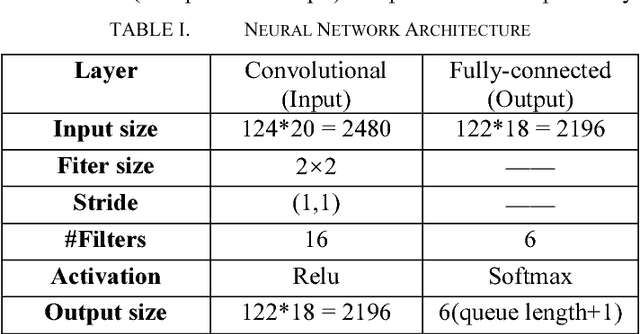
Minimizing job scheduling time is a fundamental issue in data center networks that has been extensively studied in recent years. The incoming jobs require different CPU and memory units, and span different number of time slots. The traditional solution is to design efficient heuristic algorithms with performance guarantee under certain assumptions. In this paper, we improve a recently proposed job scheduling algorithm using deep reinforcement learning and extend it to multiple server clusters. Our study reveals that deep reinforcement learning method has the potential to outperform traditional resource allocation algorithms in a variety of complicated environments.