 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Packet Routing with Fully-distributed Multi-agent Deep Reinforcement Learning
Paper and Code
May 09, 2019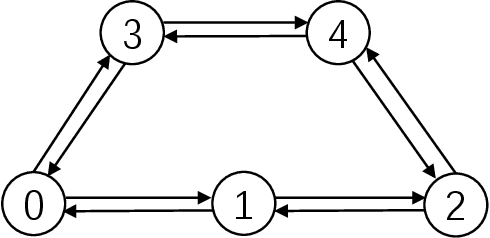
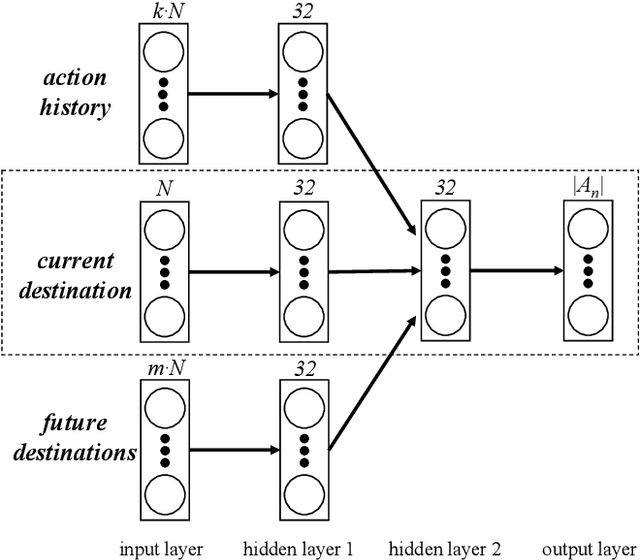
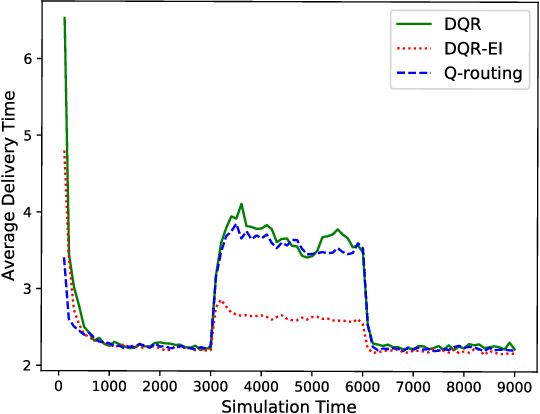
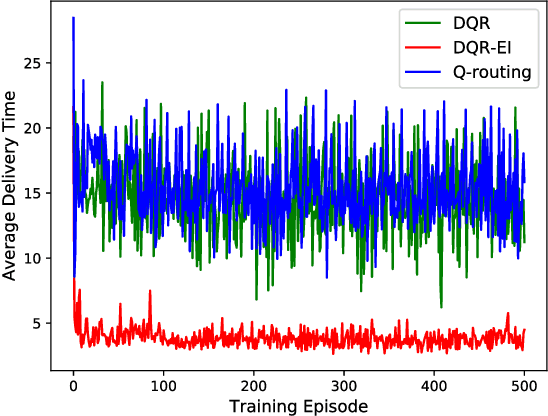
Packet routing is one of the fundamental problems in computer networks in which a router determines the next-hop of each packet in the queue to get it as quickly as possible to its destination. Reinforcement learning has been introduced to design the autonomous packet routing policy namely Q-routing only using local information available to each router. However, the curse of dimensionality of Q-routing prohibits the more comprehensive representation of dynamic network states, thus limiting the potential benefit of reinforcement learning. Inspired by recent success of deep reinforcement learning (DRL), we embed deep neural networks in multi-agent Q-routing. Each router possesses an independent neural network that is trained without communicating with its neighbors and makes decision locally. Two multi-agent DRL-enabled routing algorithms are proposed: one simply replaces Q-table of vanilla Q-routing by a deep neural network, and the other further employs extra information including the past actions and the destinations of non-head of line packets. Our simulation manifests that the direct substitution of Q-table by a deep neural network may not yield minimal delivery delays because the neural network does not learn more from the same input. When more information is utilized, adaptive routing policy can converge and significantly reduce the packet delivery time.