 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD-NG: Meta-Auto-Decoder Neural Galerkin Method for Solving Parametric Partial Differential Equations
Dec 25, 2025Parametric partial differential equations (PDEs) are fundamental for modeling a wide range of physical and engineering systems influenced by uncertain or varying parameters. Traditional neural network-based solvers, such as Physics-Informed Neural Networks (PINNs) and Deep Galerkin Methods, often face challenges in generalization and long-time prediction efficiency due to their dependence on full space-time approximations. To address these issues, we propose a novel and scalable framework that significantly enhances the Neural Galerkin Method (NGM) by incorporating the Meta-Auto-Decoder (MAD) paradigm. Our approach leverages space-time decoupling to enable more stable and efficient time integration, while meta-learning-driven adaptation allows rapid generalization to unseen parameter configurations with minimal retraining. Furthermore, randomized sparse updates effectively reduce computational costs without compromising accuracy. Together, these advancements enable our method to achieve physically consistent, long-horizon predictions for complex parameterized evolution equations with significantly lower computational overhead. Numerical experiments on benchmark problems demonstrate that our methods performs comparatively well in terms of accuracy, robustness, and adaptability.
MCTS-SQL: An Effective Framework for Text-to-SQL with Monte Carlo Tree Search
Jan 28, 2025



Text-to-SQL is a fundamental and longstanding problem in the NLP area, aiming at converting natural language queries into SQL, enabling non-expert users to operate databases. Recent advances in LLM have greatly improved text-to-SQL performance. However, challenges persist, especially when dealing with complex user queries. Current approaches (e.g., COT prompting and multi-agent frameworks) rely on the ability of models to plan and generate SQL autonomously, but controlling performance remains difficult. In addition, LLMs are still prone to hallucinations. To alleviate these challenges, we designed a novel MCTS-SQL to guide SQL generation iteratively. The approach generates SQL queries through Monte Carlo Tree Search (MCTS) and a heuristic self-refinement mechanism are used to enhance accuracy and reliability. Key components include a schema selector for extracting relevant information and an MCTS-based generator for iterative query refinement. Experimental results from the SPIDER and BIRD benchmarks show that MCTS-SQL achieves state-of-the-art performance. Specifically, on the BIRD development dataset, MCTS-SQL achieves an Execution (EX) accuracy of 69.40% using GPT-4o as the base model and a significant improvement when dealing with challenging tasks, with an EX of 51.48%, which is 3.41% higher than the existing method.
LCFed: An Efficient Clustered Federated Learning Framework for Heterogeneous Data
Jan 03, 2025



Clustered federated learning (CFL) addresses the performance challenges posed by data heterogeneity in federated learning (FL) by organizing edge devices with similar data distributions into clusters, enabling collaborative model training tailored to each group. However, existing CFL approaches strictly limit knowledge sharing to within clusters, lacking the integration of global knowledge with intra-cluster training, which leads to suboptimal performance. Moreover, traditional clustering methods incur significant computational overhead, especially as the number of edge devices increases. In this paper, we propose LCFed, an efficient CFL framework to combat these challenges. By leveraging model partitioning and adopting distinct aggregation strategies for each sub-model, LCFed effectively incorporates global knowledge into intra-cluster co-training, achieving optimal training performance. Additionally, LCFed customizes a computationally efficient model similarity measurement method based on low-rank models, enabling real-time cluster updates with minimal computational overhead. Extensive experiments show that LCFed outperforms state-of-the-art benchmarks in both test accuracy and clustering computational efficiency.
KACDP: A Highly Interpretable Credit Default Prediction Model
Nov 26, 2024In the field of finance, the prediction of individual credit default is of vital importance. However, existing methods face problems such as insufficient interpretability and transparency as well as limited performance when dealing with high-dimensional and nonlinear data. To address these issues, this paper introduces a method based on Kolmogorov-Arnold Networks (KANs). KANs is a new type of neural network architecture with learnable activation functions and no linear weights, which has potential advantages in handling complex multi-dimensional data. Specifically, this paper applies KANs to the field of individual credit risk prediction for the first time and constructs the Kolmogorov-Arnold Credit Default Predict (KACDP) model. Experiments show that the KACDP model outperforms mainstream credit default prediction models in performance metrics (ROC_AUC and F1 values). Meanwhile, through methods such as feature attribution scores and visualization of the model structure, the model's decision-making process and the importance of different features are clearly demonstrated, providing transparent and interpretable decision-making basis for financial institutions and meeting the industry's strict requirements for model interpretability. In conclusion, the KACDP model constructed in this paper exhibits excellent predictive performance and satisfactory interpretability in individual credit risk prediction, providing an effective way to address the limitations of existing methods and offering a new and practical credit risk prediction tool for financial institutions.
Neural Network-based High-index Saddle Dynamics Method for Searching Saddle Points and Solution Landscape
Nov 25, 2024The high-index saddle dynamics (HiSD) method is a powerful approach for computing saddle points and solution landscape. However, its practical applicability is constrained by the need for the explicit energy function expression. To overcome this challenge, we propose a neural network-based high-index saddle dynamics (NN-HiSD) method. It utilizes neural network-based surrogate model to approximates the energy function, allowing the use of the HiSD method in the cases where the energy function is either unavailable or computationally expensive. We further enhance the efficiency of the NN-HiSD method by incorporating momentum acceleration techniques, specifically Nesterov's acceleration and the heavy-ball method. We also provide a rigorous convergence analysis of the NN-HiSD method. We conduct numerical experiments on systems with and without explicit energy functions, specifically including the alanine dipeptide model and bacterial ribosomal assembly intermediates for the latter, demonstrating the effectiveness and reliability of the proposed method.
PSNE: Efficient Spectral Sparsification Algorithms for Scaling Network Embedding
Aug 05, 2024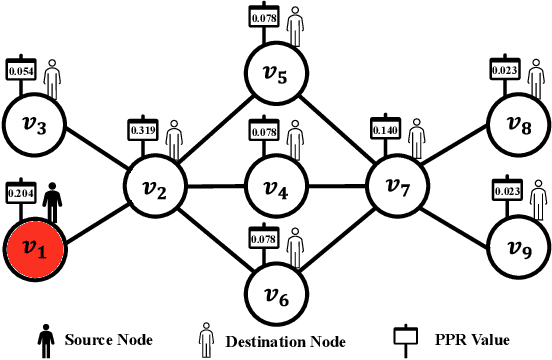

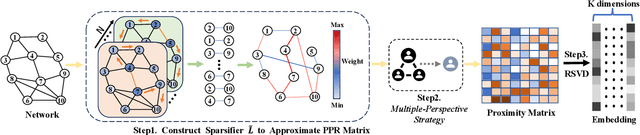
Network embedding has numerous practical applications and has received extensive attention in graph learning, which aims at mapping vertices into a low-dimensional and continuous dense vector space by preserving the underlying structural properties of the graph. Many network embedding methods have been proposed, among which factorization of the Personalized PageRank (PPR for short) matrix has been empirically and theoretically well supported recently. However, several fundamental issues cannot be addressed. (1) Existing methods invoke a seminal Local Push subroutine to approximate \textit{a single} row or column of the PPR matrix. Thus, they have to execute $n$ ($n$ is the number of nodes) Local Push subroutines to obtain a provable PPR matrix, resulting in prohibitively high computational costs for large $n$. (2) The PPR matrix has limited power in capturing the structural similarity between vertices, leading to performance degradation. To overcome these dilemmas, we propose PSNE, an efficient spectral s\textbf{P}arsification method for \textbf{S}caling \textbf{N}etwork \textbf{E}mbedding, which can fast obtain the embedding vectors that retain strong structural similarities. Specifically, PSNE first designs a matrix polynomial sparser to accelerate the calculation of the PPR matrix, which has a theoretical guarantee in terms of the Frobenius norm. Subsequently, PSNE proposes a simple but effective multiple-perspective strategy to enhance further the representation power of the obtained approximate PPR matrix. Finally, PSNE applies a randomized singular value decomposition algorithm on the sparse and multiple-perspective PPR matrix to get the target embedding vectors. Experimental evaluation of real-world and synthetic datasets shows that our solutions are indeed more efficient, effective, and scalable compared with ten competitors.
Exploring Lightweight Federated Learning for Distributed Load Forecasting
Apr 04, 2024



Federated Learning (FL) is a distributed learning scheme that enables deep learning to be applied to sensitive data streams and applications in a privacy-preserving manner. This paper focuses on the use of FL for analyzing smart energy meter data with the aim to achieve comparable accuracy to state-of-the-art methods for load forecasting while ensuring the privacy of individual meter data. We show that with a lightweight fully connected deep neural network, we are able to achieve forecasting accuracy comparable to existing schemes, both at each meter source and at the aggregator, by utilising the FL framework. The use of lightweight models further reduces the energy and resource consumption caused by complex deep-learning models, making this approach ideally suited for deployment across resource-constrained smart meter systems. With our proposed lightweight model, we are able to achieve an overall average load forecasting RMSE of 0.17, with the model having a negligible energy overhead of 50 mWh when performing training and inference on an Arduino Uno platform.
FedAC: An Adaptive Clustered Federated Learning Framework for Heterogeneous Data
Mar 29, 2024Clustered federated learning (CFL) is proposed to mitigate the performance deterioration stemming from data heterogeneity in federated learning (FL) by grouping similar clients for cluster-wise model training. However, current CFL methods struggle due to inadequate integration of global and intra-cluster knowledge and the absence of an efficient online model similarity metric, while treating the cluster count as a fixed hyperparameter limits flexibility and robustness. In this paper, we propose an adaptive CFL framework, named FedAC, which (1) efficiently integrates global knowledge into intra-cluster learning by decoupling neural networks and utilizing distinct aggregation methods for each submodule, significantly enhancing performance; (2) includes a costeffective online model similarity metric based on dimensionality reduction; (3) incorporates a cluster number fine-tuning module for improved adaptability and scalability in complex, heterogeneous environments. Extensive experiments show that FedAC achieves superior empirical performance, increasing the test accuracy by around 1.82% and 12.67% on CIFAR-10 and CIFAR-100 datasets, respectively, under different non-IID settings compared to SOTA methods.
A Survey on Large Language Models from Concept to Implementation
Mar 27, 2024Recent advancements in Large Language Models (LLMs), particularly those built on Transformer architectures, have significantly broadened the scope of natural language processing (NLP) applications, transcending their initial use in chatbot technology. This paper investigates the multifaceted applications of these models, with an emphasis on the GPT series. This exploration focuses on the transformative impact of artificial intelligence (AI) driven tools in revolutionizing traditional tasks like coding and problem-solving, while also paving new paths in research and development across diverse industries. From code interpretation and image captioning to facilitating the construction of interactive systems and advancing computational domains, Transformer models exemplify a synergy of deep learning, data analysis, and neural network design. This survey provides an in-depth look at the latest research in Transformer models, highlighting their versatility and the potential they hold for transforming diverse application sectors, thereby offering readers a comprehensive understanding of the current and future landscape of Transformer-based LLMs in practical applications.
Deep Learning-Assisted Simultaneous Targets Sensing and Super-Resolution Imaging
May 02, 2023



Recently, metasurfaces have experienced revolutionary growth in the sensing and superresolution imaging field, due to their enabling of subwavelength manipulation of electromagnetic waves. However, the addition of metasurfaces multiplies the complexity of retrieving target information from the detected fields. Besides, although the deep learning method affords a compelling platform for a series of electromagnetic problems, many studies mainly concentrate on resolving one single function and limit the research's versatility. In this study, a multifunctional deep neural network is demonstrated to reconstruct target information in a metasurface targets interactive system. Firstly, the interactive scenario is confirmed to tolerate the system noises in a primary verification experiment. Then, fed with the electric field distributions, the multitask deep neural network can not only sense the quantity and permittivity of targets but also generate superresolution images with high precision. The deep learning method provides another way to recover targets' diverse information in metasurface based target detection, accelerating the progression of target reconstruction areas. This methodology may also hold promise for inverse reconstruction or forward prediction problems in other electromagnetic scenarios.