 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetacognition as Reward: Reinforcing LLM Reasoning via Knowledge and Regulation Signals
May 22, 2026Recent RL methods have substantially improved the reasoning abilities of LLMs. Existing reward designs mainly follow two paradigms: (1) Reinforcement learning with verifiable rewards (RLVR) derives outcome signals from executable checks or ground-truth answers, but provides limited guidance for intermediate reasoning behaviors. (2) Rubrics-as-reward (RaR) goes beyond final-answer checking by using natural-language rubrics to assess reasoning quality and task compliance, but often requires instance-specific rubrics and substantial design effort. To address these issues, we introduce Metacognition-as-Reward (MaR), a metacognition-inspired RL framework that guides LLM reasoning through two general process dimensions: i) metacognitive knowledge, which identifies task-relevant information without hand-crafted instance-specific rubrics, and ii) metacognitive regulation, which plans and adjusts the reasoning process to provide reward guidance beyond final-answer outcomes. MaR scaffolds model rollouts into explicit metacognitive components and optimizes them with a trajectory-level reward over task knowledge coverage, regulation fidelity, and final-answer correctness. In this way, MaR extends reward feedback to reasoning trajectories while grounding the reward signals in general metacognitive dimensions. Experiments on 22 benchmarks show that MaR consistently improves model performance, achieving up to a 7.7% gain over the base model and up to an 11.0% gain over vanilla DAPO. Notably, Qwen3.5-9B + MaR narrows the gap to frontier models, surpassing GPT-OSS-120B on overall average and outperforming stronger models on several individual benchmarks. Process-level analysis further shows substantial improvements in reasoning process quality. MaR also generalizes to out-of-domain datasets, where MaR-trained models improve over their corresponding base models on average.
DEPO: Dual-Efficiency Preference Optimization for LLM Agents
Nov 19, 2025Recent advances in large language models (LLMs) have greatly improved their reasoning and decision-making abilities when deployed as agents. Richer reasoning, however, often comes at the cost of longer chain of thought (CoT), hampering interaction efficiency in real-world scenarios. Nevertheless, there still lacks systematic definition of LLM agent efficiency, hindering targeted improvements. To this end, we introduce dual-efficiency, comprising (i) step-level efficiency, which minimizes tokens per step, and (ii) trajectory-level efficiency, which minimizes the number of steps to complete a task. Building on this definition, we propose DEPO, a dual-efficiency preference optimization method that jointly rewards succinct responses and fewer action steps. Experiments on WebShop and BabyAI show that DEPO cuts token usage by up to 60.9% and steps by up to 26.9%, while achieving up to a 29.3% improvement in performance. DEPO also generalizes to three out-of-domain math benchmarks and retains its efficiency gains when trained on only 25% of the data. Our project page is at https://opencausalab.github.io/DEPO.
Collaborative Memory: Multi-User Memory Sharing in LLM Agents with Dynamic Access Control
May 23, 2025Complex tasks are increasingly delegated to ensembles of specialized LLM-based agents that reason, communicate, and coordinate actions-both among themselves and through interactions with external tools, APIs, and databases. While persistent memory has been shown to enhance single-agent performance, most approaches assume a monolithic, single-user context-overlooking the benefits and challenges of knowledge transfer across users under dynamic, asymmetric permissions. We introduce Collaborative Memory, a framework for multi-user, multi-agent environments with asymmetric, time-evolving access controls encoded as bipartite graphs linking users, agents, and resources. Our system maintains two memory tiers: (1) private memory-private fragments visible only to their originating user; and (2) shared memory-selectively shared fragments. Each fragment carries immutable provenance attributes (contributing agents, accessed resources, and timestamps) to support retrospective permission checks. Granular read policies enforce current user-agent-resource constraints and project existing memory fragments into filtered transformed views. Write policies determine fragment retention and sharing, applying context-aware transformations to update the memory. Both policies may be designed conditioned on system, agent, and user-level information. Our framework enables safe, efficient, and interpretable cross-user knowledge sharing, with provable adherence to asymmetric, time-varying policies and full auditability of memory operations.
SimAug: Enhancing Recommendation with Pretrained Language Models for Dense and Balanced Data Augmentation
May 03, 2025Deep Neural Networks (DNNs) are extensively used in collaborative filtering due to their impressive effectiveness. These systems depend on interaction data to learn user and item embeddings that are crucial for recommendations. However, the data often suffers from sparsity and imbalance issues: limited observations of user-item interactions can result in sub-optimal performance, and a predominance of interactions with popular items may introduce recommendation bias. To address these challenges, we employ Pretrained Language Models (PLMs) to enhance the interaction data with textual information, leading to a denser and more balanced dataset. Specifically, we propose a simple yet effective data augmentation method (SimAug) based on the textual similarity from PLMs, which can be seamlessly integrated to any systems as a lightweight, plug-and-play component in the pre-processing stage. Our experiments across nine datasets consistently demonstrate improvements in both utility and fairness when training with the augmented data generated by SimAug. The code is available at https://github.com/YuyingZhao/SimAug.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025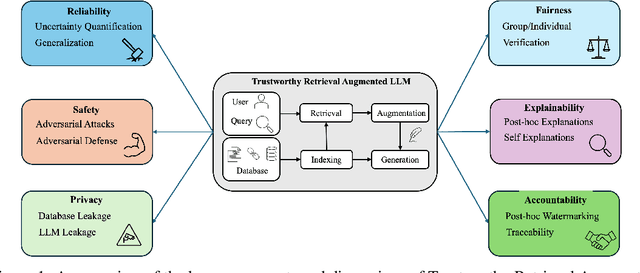
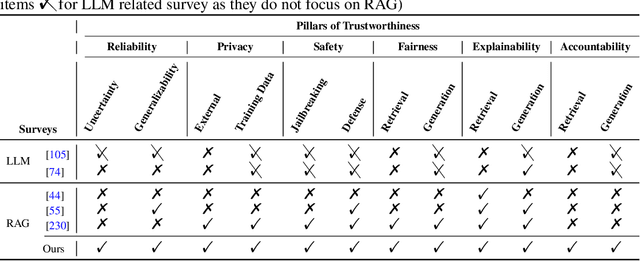


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Large Language Model-based Augmentation for Imbalanced Node Classification on Text-Attributed Graphs
Oct 22, 2024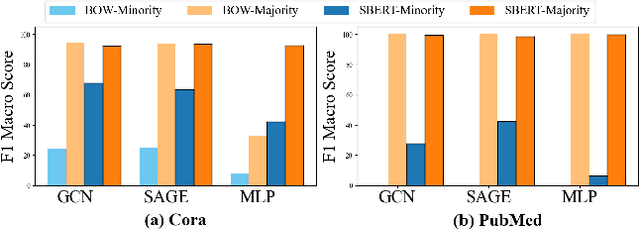
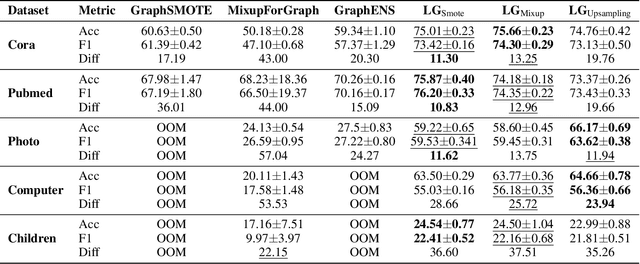

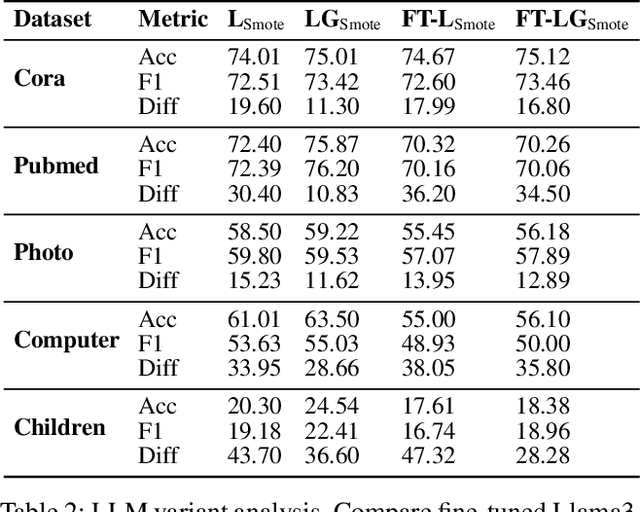
Node classification on graphs frequently encounters the challenge of class imbalance, leading to biased performance and posing significant risks in real-world applications. Although several data-centric solutions have been proposed, none of them focus on Text-Attributed Graphs (TAGs), and therefore overlook the potential of leveraging the rich semantics encoded in textual features for boosting the classification of minority nodes. Given this crucial gap, we investigate the possibility of augmenting graph data in the text space, leveraging the textual generation power of Large Language Models (LLMs) to handle imbalanced node classification on TAGs. Specifically, we propose a novel approach called LA-TAG (LLM-based Augmentation on Text-Attributed Graphs), which prompts LLMs to generate synthetic texts based on existing node texts in the graph. Furthermore, to integrate these synthetic text-attributed nodes into the graph, we introduce a text-based link predictor to connect the synthesized nodes with the existing nodes. Our experiments across multiple datasets and evaluation metrics show that our framework significantly outperforms traditional non-textual-based data augmentation strategies and specific node imbalance solutions. This highlights the promise of using LLMs to resolve imbalance issues on TAGs.
PSNE: Efficient Spectral Sparsification Algorithms for Scaling Network Embedding
Aug 05, 2024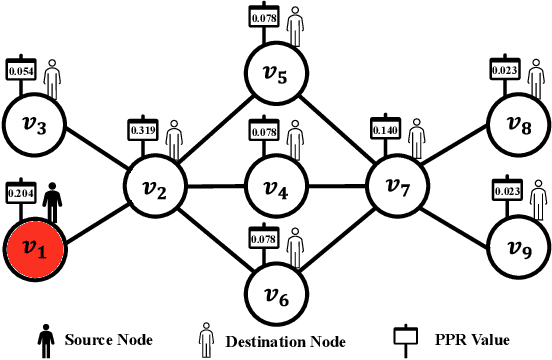

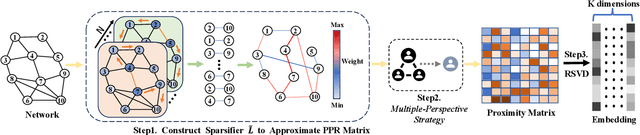
Network embedding has numerous practical applications and has received extensive attention in graph learning, which aims at mapping vertices into a low-dimensional and continuous dense vector space by preserving the underlying structural properties of the graph. Many network embedding methods have been proposed, among which factorization of the Personalized PageRank (PPR for short) matrix has been empirically and theoretically well supported recently. However, several fundamental issues cannot be addressed. (1) Existing methods invoke a seminal Local Push subroutine to approximate \textit{a single} row or column of the PPR matrix. Thus, they have to execute $n$ ($n$ is the number of nodes) Local Push subroutines to obtain a provable PPR matrix, resulting in prohibitively high computational costs for large $n$. (2) The PPR matrix has limited power in capturing the structural similarity between vertices, leading to performance degradation. To overcome these dilemmas, we propose PSNE, an efficient spectral s\textbf{P}arsification method for \textbf{S}caling \textbf{N}etwork \textbf{E}mbedding, which can fast obtain the embedding vectors that retain strong structural similarities. Specifically, PSNE first designs a matrix polynomial sparser to accelerate the calculation of the PPR matrix, which has a theoretical guarantee in terms of the Frobenius norm. Subsequently, PSNE proposes a simple but effective multiple-perspective strategy to enhance further the representation power of the obtained approximate PPR matrix. Finally, PSNE applies a randomized singular value decomposition algorithm on the sparse and multiple-perspective PPR matrix to get the target embedding vectors. Experimental evaluation of real-world and synthetic datasets shows that our solutions are indeed more efficient, effective, and scalable compared with ten competitors.
SimCE: Simplifying Cross-Entropy Loss for Collaborative Filtering
Jun 23, 2024



The learning objective is integral to collaborative filtering systems, where the Bayesian Personalized Ranking (BPR) loss is widely used for learning informative backbones. However, BPR often experiences slow convergence and suboptimal local optima, partially because it only considers one negative item for each positive item, neglecting the potential impacts of other unobserved items. To address this issue, the recently proposed Sampled Softmax Cross-Entropy (SSM) compares one positive sample with multiple negative samples, leading to better performance. Our comprehensive experiments confirm that recommender systems consistently benefit from multiple negative samples during training. Furthermore, we introduce a \underline{Sim}plified Sampled Softmax \underline{C}ross-\underline{E}ntropy Loss (SimCE), which simplifies the SSM using its upper bound. Our validation on 12 benchmark datasets, using both MF and LightGCN backbones, shows that SimCE significantly outperforms both BPR and SSM.
Edge Classification on Graphs: New Directions in Topological Imbalance
Jun 18, 2024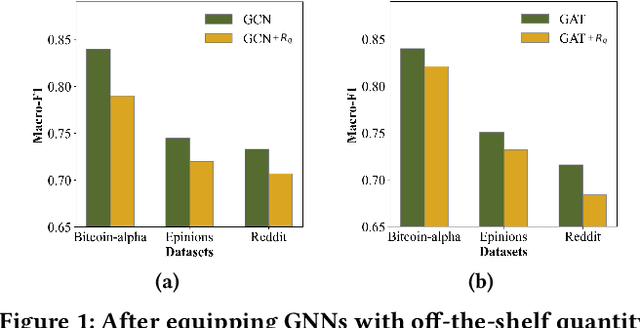
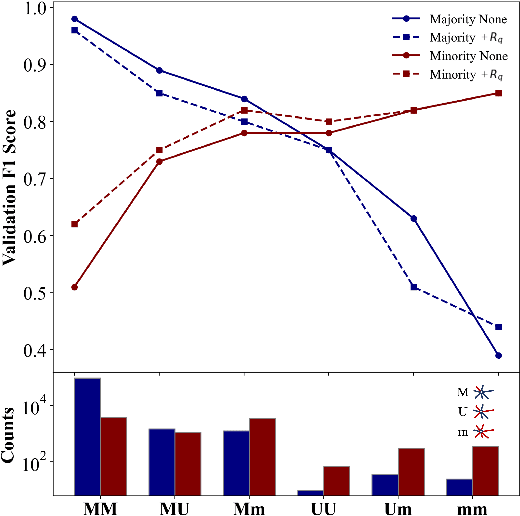
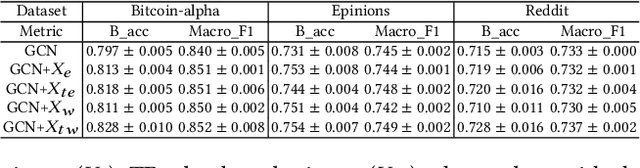
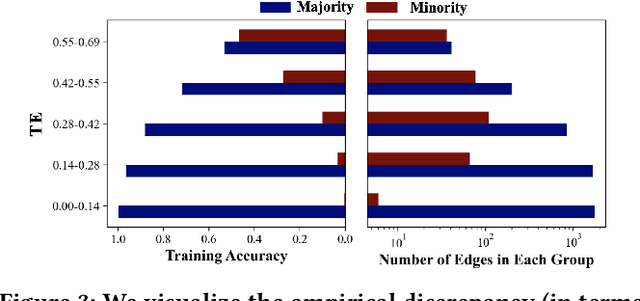
Recent years have witnessed the remarkable success of applying Graph machine learning (GML) to node/graph classification and link prediction. However, edge classification task that enjoys numerous real-world applications such as social network analysis and cybersecurity, has not seen significant advancement. To address this gap, our study pioneers a comprehensive approach to edge classification. We identify a novel `Topological Imbalance Issue', which arises from the skewed distribution of edges across different classes, affecting the local subgraph of each edge and harming the performance of edge classifications. Inspired by the recent studies in node classification that the performance discrepancy exists with varying local structural patterns, we aim to investigate if the performance discrepancy in topological imbalanced edge classification can also be mitigated by characterizing the local class distribution variance. To overcome this challenge, we introduce Topological Entropy (TE), a novel topological-based metric that measures the topological imbalance for each edge. Our empirical studies confirm that TE effectively measures local class distribution variance, and indicate that prioritizing edges with high TE values can help address the issue of topological imbalance. Based on this, we develop two strategies - Topological Reweighting and TE Wedge-based Mixup - to focus training on (synthetic) edges based on their TEs. While topological reweighting directly manipulates training edge weights according to TE, our wedge-based mixup interpolates synthetic edges between high TE wedges. Ultimately, we integrate these strategies into a novel topological imbalance strategy for edge classification: TopoEdge. Through extensive experiments, we demonstrate the efficacy of our proposed strategies on newly curated datasets and thus establish a new benchmark for (imbalanced) edge classification.
Augmenting Textual Generation via Topology Aware Retrieval
May 27, 2024



Despite the impressive advancements of Large Language Models (LLMs) in generating text, they are often limited by the knowledge contained in the input and prone to producing inaccurate or hallucinated content. To tackle these issues, Retrieval-augmented Generation (RAG) is employed as an effective strategy to enhance the available knowledge base and anchor the responses in reality by pulling additional texts from external databases. In real-world applications, texts are often linked through entities within a graph, such as citations in academic papers or comments in social networks. This paper exploits these topological relationships to guide the retrieval process in RAG. Specifically, we explore two kinds of topological connections: proximity-based, focusing on closely connected nodes, and role-based, which looks at nodes sharing similar subgraph structures. Our empirical research confirms their relevance to text relationships, leading us to develop a Topology-aware Retrieval-augmented Generation framework. This framework includes a retrieval module that selects texts based on their topological relationships and an aggregation module that integrates these texts into prompts to stimulate LLMs for text generation. We have curated established text-attributed networks and conducted comprehensive experiments to validate the effectiveness of this framework, demonstrating its potential to enhance RAG with topological awareness.