 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-based Augmentation for Imbalanced Node Classification on Text-Attributed Graphs
Paper and Code
Oct 22, 2024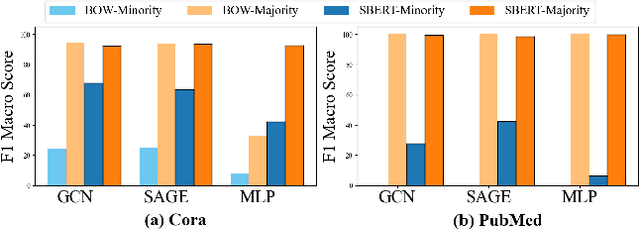
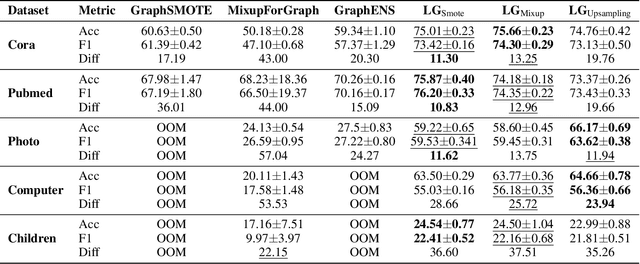

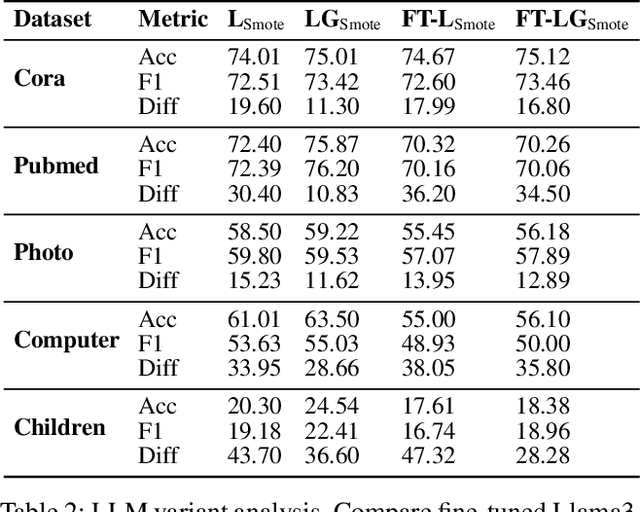
Node classification on graphs frequently encounters the challenge of class imbalance, leading to biased performance and posing significant risks in real-world applications. Although several data-centric solutions have been proposed, none of them focus on Text-Attributed Graphs (TAGs), and therefore overlook the potential of leveraging the rich semantics encoded in textual features for boosting the classification of minority nodes. Given this crucial gap, we investigate the possibility of augmenting graph data in the text space, leveraging the textual generation power of Large Language Models (LLMs) to handle imbalanced node classification on TAGs. Specifically, we propose a novel approach called LA-TAG (LLM-based Augmentation on Text-Attributed Graphs), which prompts LLMs to generate synthetic texts based on existing node texts in the graph. Furthermore, to integrate these synthetic text-attributed nodes into the graph, we introduce a text-based link predictor to connect the synthesized nodes with the existing nodes. Our experiments across multiple datasets and evaluation metrics show that our framework significantly outperforms traditional non-textual-based data augmentation strategies and specific node imbalance solutions. This highlights the promise of using LLMs to resolve imbalance issues on TAGs.