 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Graph Anomaly Detection: A Survey and New Perspectives
Sep 16, 2024Graph anomaly detection (GAD), which aims to identify unusual graph instances (nodes, edges, subgraphs, or graphs), has attracted increasing attention in recent years due to its significance in a wide range of applications. Deep learning approaches, graph neural networks (GNNs) in particular, have been emerging as a promising paradigm for GAD, owing to its strong capability in capturing complex structure and/or node attributes in graph data. Considering the large number of methods proposed for GNN-based GAD, it is of paramount importance to summarize the methodologies and findings in the existing GAD studies, so that we can pinpoint effective model designs for tackling open GAD problems. To this end, in this work we aim to present a comprehensive review of deep learning approaches for GAD. Existing GAD surveys are focused on task-specific discussions, making it difficult to understand the technical insights of existing methods and their limitations in addressing some unique challenges in GAD. To fill this gap, we first discuss the problem complexities and their resulting challenges in GAD, and then provide a systematic review of current deep GAD methods from three novel perspectives of methodology, including GNN backbone design, proxy task design for GAD, and graph anomaly measures. To deepen the discussions, we further propose a taxonomy of 13 fine-grained method categories under these three perspectives to provide more in-depth insights into the model designs and their capabilities. To facilitate the experiments and validation, we also summarize a collection of widely-used GAD datasets and empirical comparison. We further discuss multiple open problems to inspire more future high-quality research. A continuously updated repository for datasets, links to the codes of algorithms, and empirical comparison is available at https://github.com/mala-lab/Awesome-Deep-Graph-Anomaly-Detection.
Leveraging Opposite Gender Interaction Ratio as a Path towards Fairness in Online Dating Recommendations Based on User Sexual Orientation
Feb 19, 2024Online dating platforms have gained widespread popularity as a means for individuals to seek potential romantic relationships. While recommender systems have been designed to improve the user experience in dating platforms by providing personalized recommendations, increasing concerns about fairness have encouraged the development of fairness-aware recommender systems from various perspectives (e.g., gender and race). However, sexual orientation, which plays a significant role in finding a satisfying relationship, is under-investigated. To fill this crucial gap, we propose a novel metric, Opposite Gender Interaction Ratio (OGIR), as a way to investigate potential unfairness for users with varying preferences towards the opposite gender. We empirically analyze a real online dating dataset and observe existing recommender algorithms could suffer from group unfairness according to OGIR. We further investigate the potential causes for such gaps in recommendation quality, which lead to the challenges of group quantity imbalance and group calibration imbalance. Ultimately, we propose a fair recommender system based on re-weighting and re-ranking strategies to respectively mitigate these associated imbalance challenges. Experimental results demonstrate both strategies improve fairness while their combination achieves the best performance towards maintaining model utility while improving fairness.
Precedence-Constrained Winter Value for Effective Graph Data Valuation
Feb 02, 2024



Data valuation is essential for quantifying data's worth, aiding in assessing data quality and determining fair compensation. While existing data valuation methods have proven effective in evaluating the value of Euclidean data, they face limitations when applied to the increasingly popular graph-structured data. Particularly, graph data valuation introduces unique challenges, primarily stemming from the intricate dependencies among nodes and the exponential growth in value estimation costs. To address the challenging problem of graph data valuation, we put forth an innovative solution, Precedence-Constrained Winter (PC-Winter) Value, to account for the complex graph structure. Furthermore, we develop a variety of strategies to address the computational challenges and enable efficient approximation of PC-Winter. Extensive experiments demonstrate the effectiveness of PC-Winter across diverse datasets and tasks.
Fairness and Diversity in Recommender Systems: A Survey
Jul 10, 2023



Recommender systems are effective tools for mitigating information overload and have seen extensive applications across various domains. However, the single focus on utility goals proves to be inadequate in addressing real-world concerns, leading to increasing attention to fairness-aware and diversity-aware recommender systems. While most existing studies explore fairness and diversity independently, we identify strong connections between these two domains. In this survey, we first discuss each of them individually and then dive into their connections. Additionally, motivated by the concepts of user-level and item-level fairness, we broaden the understanding of diversity to encompass not only the item level but also the user level. With this expanded perspective on user and item-level diversity, we re-interpret fairness studies from the viewpoint of diversity. This fresh perspective enhances our understanding of fairness-related work and paves the way for potential future research directions. Papers discussed in this survey along with public code links are available at https://github.com/YuyingZhao/Awesome-Fairness-and-Diversity-Papers-in-Recommender-Systems .
A Survey on Explainability of Graph Neural Networks
Jun 02, 2023



Graph neural networks (GNNs) are powerful graph-based deep-learning models that have gained significant attention and demonstrated remarkable performance in various domains, including natural language processing, drug discovery, and recommendation systems. However, combining feature information and combinatorial graph structures has led to complex non-linear GNN models. Consequently, this has increased the challenges of understanding the workings of GNNs and the underlying reasons behind their predictions. To address this, numerous explainability methods have been proposed to shed light on the inner mechanism of the GNNs. Explainable GNNs improve their security and enhance trust in their recommendations. This survey aims to provide a comprehensive overview of the existing explainability techniques for GNNs. We create a novel taxonomy and hierarchy to categorize these methods based on their objective and methodology. We also discuss the strengths, limitations, and application scenarios of each category. Furthermore, we highlight the key evaluation metrics and datasets commonly used to assess the explainability of GNNs. This survey aims to assist researchers and practitioners in understanding the existing landscape of explainability methods, identifying gaps, and fostering further advancements in interpretable graph-based machine learning.
Counterfactual Learning on Graphs: A Survey
Apr 03, 2023Graph-structured data are pervasive in the real-world such as social networks, molecular graphs and transaction networks. Graph neural networks (GNNs) have achieved great success in representation learning on graphs, facilitating various downstream tasks. However, GNNs have several drawbacks such as lacking interpretability, can easily inherit the bias of the training data and cannot model the casual relations. Recently, counterfactual learning on graphs has shown promising results in alleviating these drawbacks. Various graph counterfactual learning approaches have been proposed for counterfactual fairness, explainability, link prediction and other applications on graphs. To facilitate the development of this promising direction, in this survey, we categorize and comprehensively review papers on graph counterfactual learning. We divide existing methods into four categories based on research problems studied. For each category, we provide background and motivating examples, a general framework summarizing existing works and a detailed review of these works. We point out promising future research directions at the intersection of graph-structured data, counterfactual learning, and real-world applications. To offer a comprehensive view of resources for future studies, we compile a collection of open-source implementations, public datasets, and commonly-used evaluation metrics. This survey aims to serve as a ``one-stop-shop'' for building a unified understanding of graph counterfactual learning categories and current resources. We also maintain a repository for papers and resources and will keep updating the repository https://github.com/TimeLovercc/Awesome-Graph-Causal-Learning.
A Comprehensive Survey of Graph-level Learning
Jan 14, 2023



Graphs have a superior ability to represent relational data, like chemical compounds, proteins, and social networks. Hence, graph-level learning, which takes a set of graphs as input, has been applied to many tasks including comparison, regression, classification, and more. Traditional approaches to learning a set of graphs tend to rely on hand-crafted features, such as substructures. But while these methods benefit from good interpretability, they often suffer from computational bottlenecks as they cannot skirt the graph isomorphism problem. Conversely, deep learning has helped graph-level learning adapt to the growing scale of graphs by extracting features automatically and decoding graphs into low-dimensional representations. As a result, these deep graph learning methods have been responsible for many successes. Yet, there is no comprehensive survey that reviews graph-level learning starting with traditional learning and moving through to the deep learning approaches. This article fills this gap and frames the representative algorithms into a systematic taxonomy covering traditional learning, graph-level deep neural networks, graph-level graph neural networks, and graph pooling. To ensure a thoroughly comprehensive survey, the evolutions, interactions, and communications between methods from four different branches of development are also examined. This is followed by a brief review of the benchmark data sets, evaluation metrics, and common downstream applications. The survey concludes with 13 future directions of necessary research that will help to overcome the challenges facing this booming field.
Link Prediction on Heterophilic Graphs via Disentangled Representation Learning
Aug 03, 2022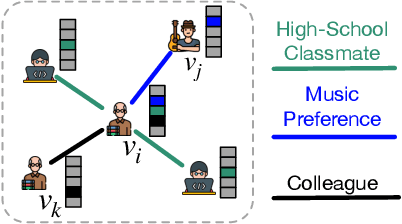
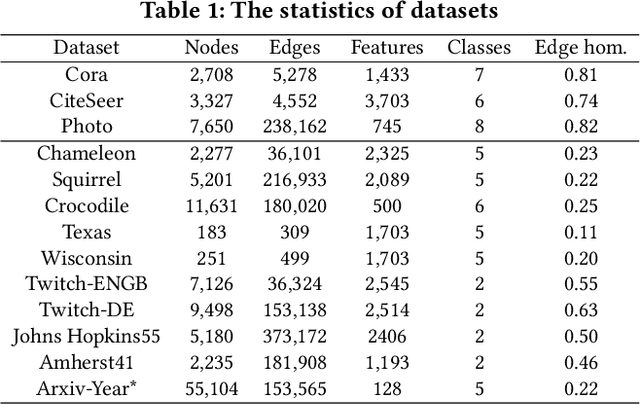
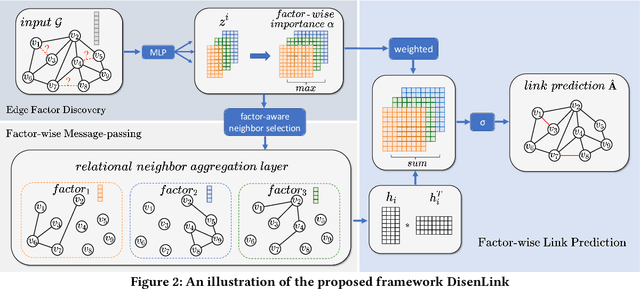
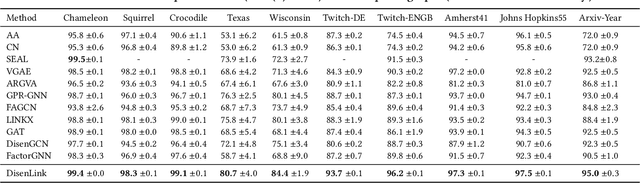
Link prediction is an important task that has wide applications in various domains. However, the majority of existing link prediction approaches assume the given graph follows homophily assumption, and designs similarity-based heuristics or representation learning approaches to predict links. However, many real-world graphs are heterophilic graphs, where the homophily assumption does not hold, which challenges existing link prediction methods. Generally, in heterophilic graphs, there are many latent factors causing the link formation, and two linked nodes tend to be similar in one or two factors but might be dissimilar in other factors, leading to low overall similarity. Thus, one way is to learn disentangled representation for each node with each vector capturing the latent representation of a node on one factor, which paves a way to model the link formation in heterophilic graphs, resulting in better node representation learning and link prediction performance. However, the work on this is rather limited. Therefore, in this paper, we study a novel problem of exploring disentangled representation learning for link prediction on heterophilic graphs. We propose a novel framework DisenLink which can learn disentangled representations by modeling the link formation and perform factor-aware message-passing to facilitate link prediction. Extensive experiments on 13 real-world datasets demonstrate the effectiveness of DisenLink for link prediction on both heterophilic and hemophiliac graphs. Our codes are available at https://github.com/sjz5202/DisenLink
Feature Overcorrelation in Deep Graph Neural Networks: A New Perspective
Jun 15, 2022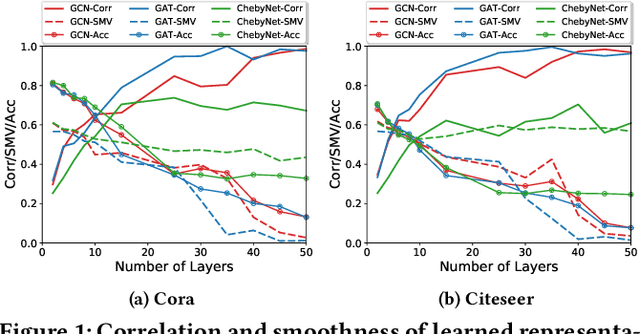
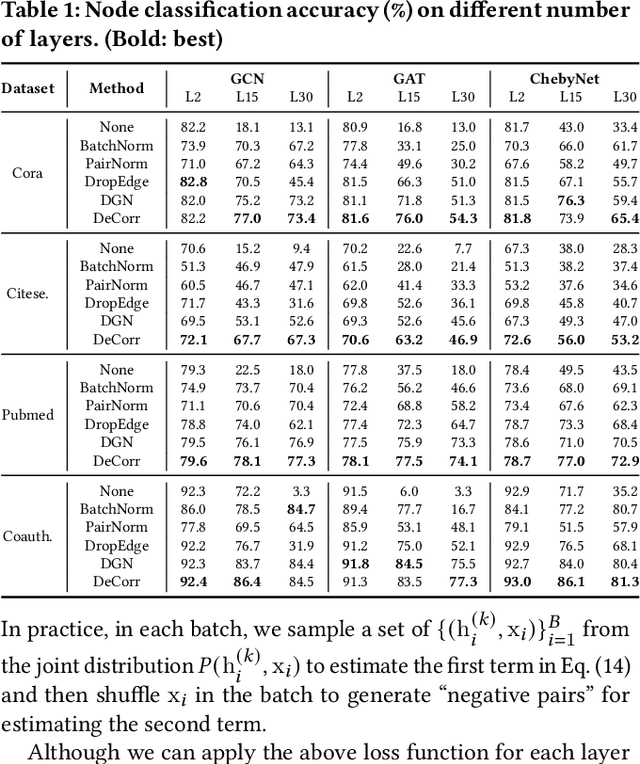
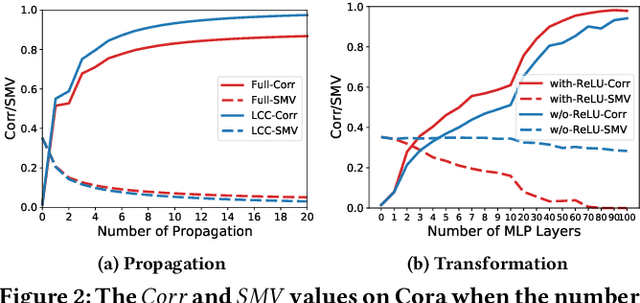

Recent years have witnessed remarkable success achieved by graph neural networks (GNNs) in many real-world applications such as recommendation and drug discovery. Despite the success, oversmoothing has been identified as one of the key issues which limit the performance of deep GNNs. It indicates that the learned node representations are highly indistinguishable due to the stacked aggregators. In this paper, we propose a new perspective to look at the performance degradation of deep GNNs, i.e., feature overcorrelation. Through empirical and theoretical study on this matter, we demonstrate the existence of feature overcorrelation in deeper GNNs and reveal potential reasons leading to this issue. To reduce the feature correlation, we propose a general framework DeCorr which can encourage GNNs to encode less redundant information. Extensive experiments have demonstrated that DeCorr can help enable deeper GNNs and is complementary to existing techniques tackling the oversmoothing issue.
Graph-level Neural Networks: Current Progress and Future Directions
May 31, 2022

Graph-structured data consisting of objects (i.e., nodes) and relationships among objects (i.e., edges) are ubiquitous. Graph-level learning is a matter of studying a collection of graphs instead of a single graph. Traditional graph-level learning methods used to be the mainstream. However, with the increasing scale and complexity of graphs, Graph-level Neural Networks (GLNNs, deep learning-based graph-level learning methods) have been attractive due to their superiority in modeling high-dimensional data. Thus, a survey on GLNNs is necessary. To frame this survey, we propose a systematic taxonomy covering GLNNs upon deep neural networks, graph neural networks, and graph pooling. The representative and state-of-the-art models in each category are focused on this survey. We also investigate the reproducibility, benchmarks, and new graph datasets of GLNNs. Finally, we conclude future directions to further push forward GLNNs. The repository of this survey is available at https://github.com/GeZhangMQ/Awesome-Graph-level-Neural-Networks.