 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Brain Graph Learning: A Survey
Jun 01, 2024



Exploring the complex structure of the human brain is crucial for understanding its functionality and diagnosing brain disorders. Thanks to advancements in neuroimaging technology, a novel approach has emerged that involves modeling the human brain as a graph-structured pattern, with different brain regions represented as nodes and the functional relationships among these regions as edges. Moreover, graph neural networks (GNNs) have demonstrated a significant advantage in mining graph-structured data. Developing GNNs to learn brain graph representations for brain disorder analysis has recently gained increasing attention. However, there is a lack of systematic survey work summarizing current research methods in this domain. In this paper, we aim to bridge this gap by reviewing brain graph learning works that utilize GNNs. We first introduce the process of brain graph modeling based on common neuroimaging data. Subsequently, we systematically categorize current works based on the type of brain graph generated and the targeted research problems. To make this research accessible to a broader range of interested researchers, we provide an overview of representative methods and commonly used datasets, along with their implementation sources. Finally, we present our insights on future research directions. The repository of this survey is available at \url{https://github.com/XuexiongLuoMQ/Awesome-Brain-Graph-Learning-with-GNNs}.
Discriminative Graph-level Anomaly Detection via Dual-students-teacher Model
Aug 03, 2023



Different from the current node-level anomaly detection task, the goal of graph-level anomaly detection is to find abnormal graphs that significantly differ from others in a graph set. Due to the scarcity of research on the work of graph-level anomaly detection, the detailed description of graph-level anomaly is insufficient. Furthermore, existing works focus on capturing anomalous graph information to learn better graph representations, but they ignore the importance of an effective anomaly score function for evaluating abnormal graphs. Thus, in this work, we first define anomalous graph information including node and graph property anomalies in a graph set and adopt node-level and graph-level information differences to identify them, respectively. Then, we introduce a discriminative graph-level anomaly detection framework with dual-students-teacher model, where the teacher model with a heuristic loss are trained to make graph representations more divergent. Then, two competing student models trained by normal and abnormal graphs respectively fit graph representations of the teacher model in terms of node-level and graph-level representation perspectives. Finally, we combine representation errors between two student models to discriminatively distinguish anomalous graphs. Extensive experiment analysis demonstrates that our method is effective for the graph-level anomaly detection task on graph datasets in the real world.
ProcessGPT: Transforming Business Process Management with Generative Artificial Intelligence
May 29, 2023Generative Pre-trained Transformer (GPT) is a state-of-the-art machine learning model capable of generating human-like text through natural language processing (NLP). GPT is trained on massive amounts of text data and uses deep learning techniques to learn patterns and relationships within the data, enabling it to generate coherent and contextually appropriate text. This position paper proposes using GPT technology to generate new process models when/if needed. We introduce ProcessGPT as a new technology that has the potential to enhance decision-making in data-centric and knowledge-intensive processes. ProcessGPT can be designed by training a generative pre-trained transformer model on a large dataset of business process data. This model can then be fine-tuned on specific process domains and trained to generate process flows and make decisions based on context and user input. The model can be integrated with NLP and machine learning techniques to provide insights and recommendations for process improvement. Furthermore, the model can automate repetitive tasks and improve process efficiency while enabling knowledge workers to communicate analysis findings, supporting evidence, and make decisions. ProcessGPT can revolutionize business process management (BPM) by offering a powerful tool for process augmentation, automation and improvement. Finally, we demonstrate how ProcessGPT can be a powerful tool for augmenting data engineers in maintaining data ecosystem processes within large bank organizations. Our scenario highlights the potential of this approach to improve efficiency, reduce costs, and enhance the quality of business operations through the automation of data-centric and knowledge-intensive processes. These results underscore the promise of ProcessGPT as a transformative technology for organizations looking to improve their process workflows.
A Comprehensive Survey of Graph-level Learning
Jan 14, 2023



Graphs have a superior ability to represent relational data, like chemical compounds, proteins, and social networks. Hence, graph-level learning, which takes a set of graphs as input, has been applied to many tasks including comparison, regression, classification, and more. Traditional approaches to learning a set of graphs tend to rely on hand-crafted features, such as substructures. But while these methods benefit from good interpretability, they often suffer from computational bottlenecks as they cannot skirt the graph isomorphism problem. Conversely, deep learning has helped graph-level learning adapt to the growing scale of graphs by extracting features automatically and decoding graphs into low-dimensional representations. As a result, these deep graph learning methods have been responsible for many successes. Yet, there is no comprehensive survey that reviews graph-level learning starting with traditional learning and moving through to the deep learning approaches. This article fills this gap and frames the representative algorithms into a systematic taxonomy covering traditional learning, graph-level deep neural networks, graph-level graph neural networks, and graph pooling. To ensure a thoroughly comprehensive survey, the evolutions, interactions, and communications between methods from four different branches of development are also examined. This is followed by a brief review of the benchmark data sets, evaluation metrics, and common downstream applications. The survey concludes with 13 future directions of necessary research that will help to overcome the challenges facing this booming field.
Type Information Utilized Event Detection via Multi-Channel GNNs in Electrical Power Systems
Nov 15, 2022Event detection in power systems aims to identify triggers and event types, which helps relevant personnel respond to emergencies promptly and facilitates the optimization of power supply strategies. However, the limited length of short electrical record texts causes severe information sparsity, and numerous domain-specific terminologies of power systems makes it difficult to transfer knowledge from language models pre-trained on general-domain texts. Traditional event detection approaches primarily focus on the general domain and ignore these two problems in the power system domain. To address the above issues, we propose a Multi-Channel graph neural network utilizing Type information for Event Detection in power systems, named MC-TED, leveraging a semantic channel and a topological channel to enrich information interaction from short texts. Concretely, the semantic channel refines textual representations with semantic similarity, building the semantic information interaction among potential event-related words. The topological channel generates a relation-type-aware graph modeling word dependencies, and a word-type-aware graph integrating part-of-speech tags. To further reduce errors worsened by professional terminologies in type analysis, a type learning mechanism is designed for updating the representations of both the word type and relation type in the topological channel. In this way, the information sparsity and professional term occurrence problems can be alleviated by enabling interaction between topological and semantic information. Furthermore, to address the lack of labeled data in power systems, we built a Chinese event detection dataset based on electrical Power Event texts, named PoE. In experiments, our model achieves compelling results not only on the PoE dataset, but on general-domain event detection datasets including ACE 2005 and MAVEN.
DAGAD: Data Augmentation for Graph Anomaly Detection
Oct 18, 2022



Graph anomaly detection in this paper aims to distinguish abnormal nodes that behave differently from the benign ones accounting for the majority of graph-structured instances. Receiving increasing attention from both academia and industry, yet existing research on this task still suffers from two critical issues when learning informative anomalous behavior from graph data. For one thing, anomalies are usually hard to capture because of their subtle abnormal behavior and the shortage of background knowledge about them, which causes severe anomalous sample scarcity. Meanwhile, the overwhelming majority of objects in real-world graphs are normal, bringing the class imbalance problem as well. To bridge the gaps, this paper devises a novel Data Augmentation-based Graph Anomaly Detection (DAGAD) framework for attributed graphs, equipped with three specially designed modules: 1) an information fusion module employing graph neural network encoders to learn representations, 2) a graph data augmentation module that fertilizes the training set with generated samples, and 3) an imbalance-tailored learning module to discriminate the distributions of the minority (anomalous) and majority (normal) classes. A series of experiments on three datasets prove that DAGAD outperforms ten state-of-the-art baseline detectors concerning various mostly-used metrics, together with an extensive ablation study validating the strength of our proposed modules.
Graph-level Neural Networks: Current Progress and Future Directions
May 31, 2022

Graph-structured data consisting of objects (i.e., nodes) and relationships among objects (i.e., edges) are ubiquitous. Graph-level learning is a matter of studying a collection of graphs instead of a single graph. Traditional graph-level learning methods used to be the mainstream. However, with the increasing scale and complexity of graphs, Graph-level Neural Networks (GLNNs, deep learning-based graph-level learning methods) have been attractive due to their superiority in modeling high-dimensional data. Thus, a survey on GLNNs is necessary. To frame this survey, we propose a systematic taxonomy covering GLNNs upon deep neural networks, graph neural networks, and graph pooling. The representative and state-of-the-art models in each category are focused on this survey. We also investigate the reproducibility, benchmarks, and new graph datasets of GLNNs. Finally, we conclude future directions to further push forward GLNNs. The repository of this survey is available at https://github.com/GeZhangMQ/Awesome-Graph-level-Neural-Networks.
Single-stage Rotate Object Detector via Two Points with Solar Corona Heatmap
Feb 14, 2022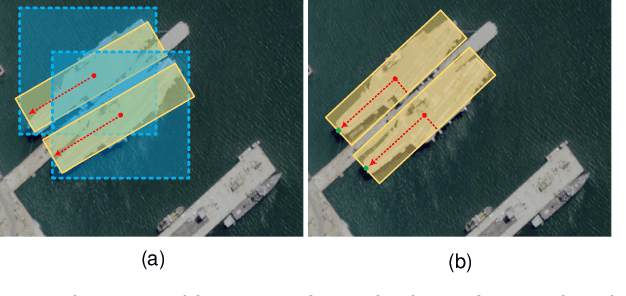

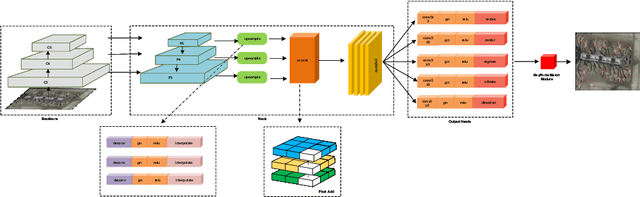
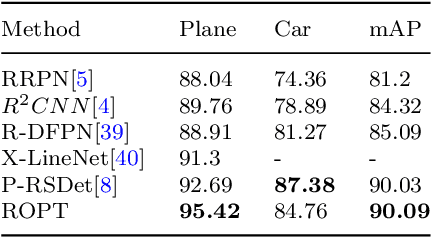
Oriented object detection is a crucial task in computer vision. Current top-down oriented detection methods usually directly detect entire objects, and not only neglecting the authentic direction of targets, but also do not fully utilise the key semantic information, which causes a decrease in detection accuracy. In this study, we developed a single-stage rotating object detector via two points with a solar corona heatmap (ROTP) to detect oriented objects. The ROTP predicts parts of the object and then aggregates them to form a whole image. Herein, we meticulously represent an object in a random direction using the vertex, centre point with width, and height. Specifically, we regress two heatmaps that characterise the relative location of each object, which enhances the accuracy of locating objects and avoids deviations caused by angle predictions. To rectify the central misjudgement of the Gaussian heatmap on high-aspect ratio targets, we designed a solar corona heatmap generation method to improve the perception difference between the central and non-central samples. Additionally, we predicted the vertex relative to the direction of the centre point to connect two key points that belong to the same goal. Experiments on the HRSC 2016, UCASAOD, and DOTA datasets show that our ROTP achieves the most advanced performance with a simpler modelling and less manual intervention.
A Comprehensive Survey on Graph Anomaly Detection with Deep Learning
Jun 14, 2021

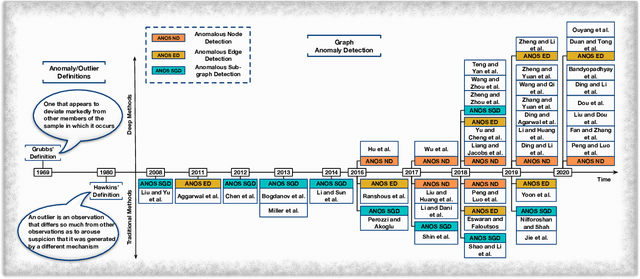

Anomalies represent rare observations (e.g., data records or events) that are deviating significantly from others. Over the last forty years, researches on anomalies have received great interests because of their significance in many disciplines (e.g., computer science, chemistry, and biology). Anomaly detection, which aims to identify these rare observations, is among the most vital tasks and has shown its power in preventing detrimental events, such as financial fraud and network intrusion, from happening. The detection task is typically solved by detecting outlying data points in the features space and inherently overlooks the structural information in real-world data. Graphs have been prevalently used to preserve the structural information, and this raises the graph anomaly detection problem - identifying anomalous graph objects (i.e., nodes, edges and sub-graphs). However, conventional anomaly detection techniques cannot well solve this problem because of the complexity of graph data (e.g., irregular structures, non-independent and large-scale). For the aptitudes of deep learning in breaking these limitations, graph anomaly detection with deep learning has received intensified studies recently. In this survey, we aim to provide a systematic and comprehensive review of the contemporary deep learning techniques for graph anomaly detection. Specifically, our categorization follows a task-driven strategy and classifies existing works according to the anomalous graph objects they can detect. We especially focus on the motivations, key intuitions and technical details of existing works. We also summarize open-sourced implementations, public datasets, and commonly-used evaluation metrics for future studies. Finally, we highlight twelve future research directions according to our survey results covering emerging problems introduced by graph data, anomaly detection and real applications.
A Comprehensive Survey on Community Detection with Deep Learning
May 26, 2021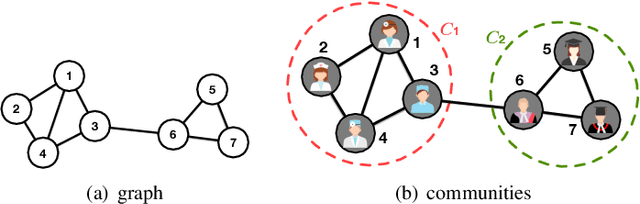
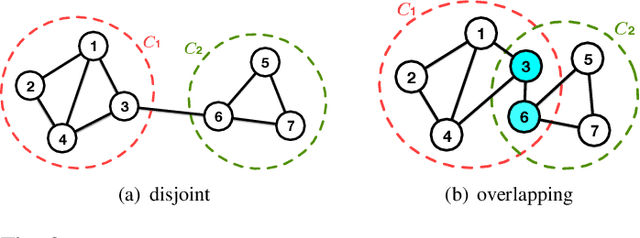
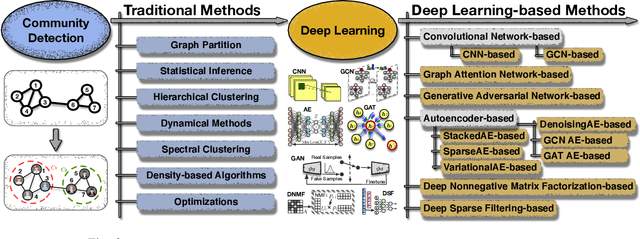
A community reveals the features and connections of its members that are different from those in other communities in a network. Detecting communities is of great significance in network analysis. Despite the classical spectral clustering and statistical inference methods, we notice a significant development of deep learning techniques for community detection in recent years with their advantages in handling high dimensional network data. Hence, a comprehensive overview of community detection's latest progress through deep learning is timely to both academics and practitioners. This survey devises and proposes a new taxonomy covering different categories of the state-of-the-art methods, including deep learning-based models upon deep neural networks, deep nonnegative matrix factorization and deep sparse filtering. The main category, i.e., deep neural networks, is further divided into convolutional networks, graph attention networks, generative adversarial networks and autoencoders. The survey also summarizes the popular benchmark data sets, model evaluation metrics, and open-source implementations to address experimentation settings. We then discuss the practical applications of community detection in various domains and point to implementation scenarios. Finally, we outline future directions by suggesting challenging topics in this fast-growing deep learning field.