 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Exploration of Trust Dynamics in LLM Supply Chains
May 25, 2024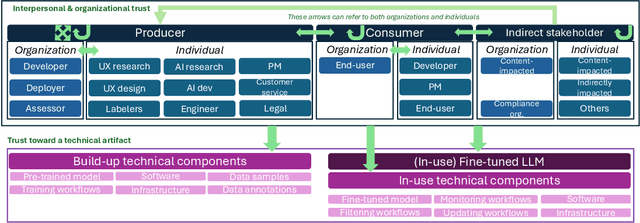
With the widespread proliferation of AI systems, trust in AI is an important and timely topic to navigate. Researchers so far have largely employed a myopic view of this relationship. In particular, a limited number of relevant trustors (e.g., end-users) and trustees (i.e., AI systems) have been considered, and empirical explorations have remained in laboratory settings, potentially overlooking factors that impact human-AI relationships in the real world. In this paper, we argue for broadening the scope of studies addressing `trust in AI' by accounting for the complex and dynamic supply chains that AI systems result from. AI supply chains entail various technical artifacts that diverse individuals, organizations, and stakeholders interact with, in a variety of ways. We present insights from an in-situ, empirical study of LLM supply chains. Our work reveals additional types of trustors and trustees and new factors impacting their trust relationships. These relationships were found to be central to the development and adoption of LLMs, but they can also be the terrain for uncalibrated trust and reliance on untrustworthy LLMs. Based on these findings, we discuss the implications for research on `trust in AI'. We highlight new research opportunities and challenges concerning the appropriate study of inter-actor relationships across the supply chain and the development of calibrated trust and meaningful reliance behaviors. We also question the meaning of building trust in the LLM supply chain.
ProcessGPT: Transforming Business Process Management with Generative Artificial Intelligence
May 29, 2023Generative Pre-trained Transformer (GPT) is a state-of-the-art machine learning model capable of generating human-like text through natural language processing (NLP). GPT is trained on massive amounts of text data and uses deep learning techniques to learn patterns and relationships within the data, enabling it to generate coherent and contextually appropriate text. This position paper proposes using GPT technology to generate new process models when/if needed. We introduce ProcessGPT as a new technology that has the potential to enhance decision-making in data-centric and knowledge-intensive processes. ProcessGPT can be designed by training a generative pre-trained transformer model on a large dataset of business process data. This model can then be fine-tuned on specific process domains and trained to generate process flows and make decisions based on context and user input. The model can be integrated with NLP and machine learning techniques to provide insights and recommendations for process improvement. Furthermore, the model can automate repetitive tasks and improve process efficiency while enabling knowledge workers to communicate analysis findings, supporting evidence, and make decisions. ProcessGPT can revolutionize business process management (BPM) by offering a powerful tool for process augmentation, automation and improvement. Finally, we demonstrate how ProcessGPT can be a powerful tool for augmenting data engineers in maintaining data ecosystem processes within large bank organizations. Our scenario highlights the potential of this approach to improve efficiency, reduce costs, and enhance the quality of business operations through the automation of data-centric and knowledge-intensive processes. These results underscore the promise of ProcessGPT as a transformative technology for organizations looking to improve their process workflows.
Rethinking and Recomputing the Value of ML Models
Sep 30, 2022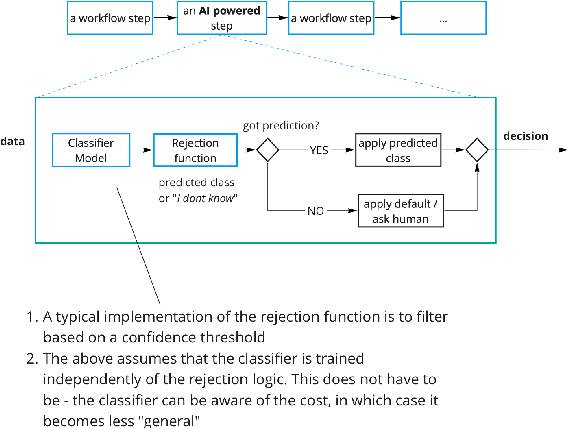
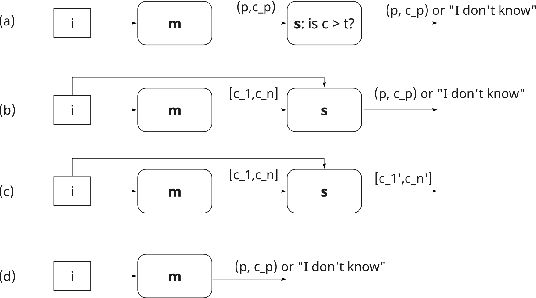
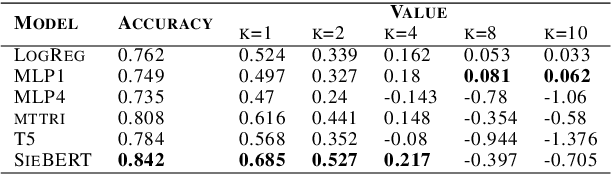
In this paper, we argue that the way we have been training and evaluating ML models has largely forgotten the fact that they are applied in an organization or societal context as they provide value to people. We show that with this perspective we fundamentally change how we evaluate, select and deploy ML models - and to some extent even what it means to learn. Specifically, we stress that the notion of value plays a central role in learning and evaluating, and different models may require different learning practices and provide different values based on the application context they are applied. We also show that this concretely impacts how we select and embed models into human workflows based on experimental datasets. Nothing of what is presented here is hard: to a large extent is a series of fairly trivial observations with massive practical implications.
On the Value of ML Models
Dec 13, 2021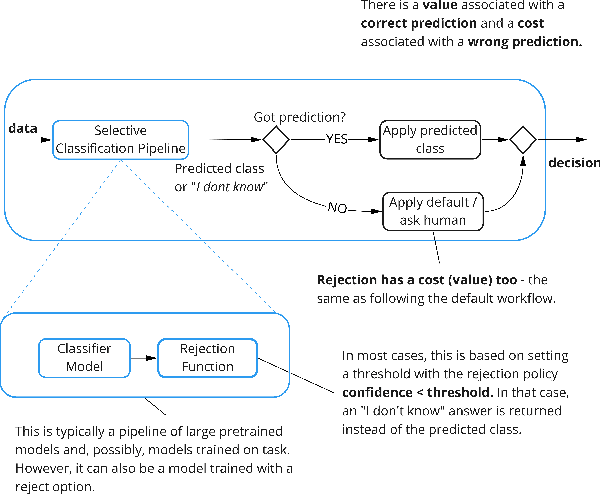
We argue that, when establishing and benchmarking Machine Learning (ML) models, the research community should favour evaluation metrics that better capture the value delivered by their model in practical applications. For a specific class of use cases -- selective classification -- we show that not only can it be simple enough to do, but that it has import consequences and provides insights what to look for in a ``good'' ML model.
* Poster presentation at Workshop on Human and Machine Decisions at NeurIPS 2021 (WHMD 2021). https://sites.google.com/view/whmd2021
The Science of Rejection: A Research Area for Human Computation
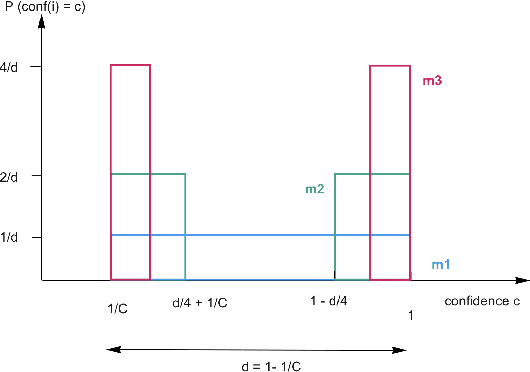
Nov 11, 2021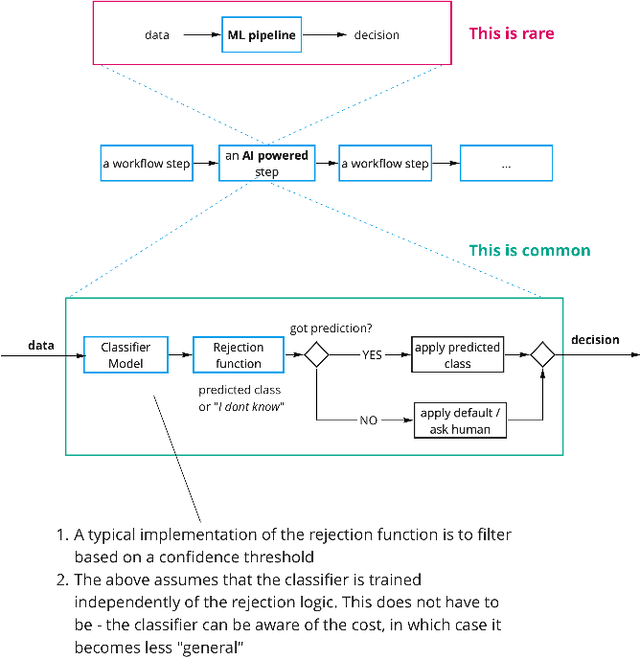
We motivate why the science of learning to reject model predictions is central to ML, and why human computation has a lead role in this effort.
Crowdsourcing Diverse Paraphrases for Training Task-oriented Bots
Sep 20, 2021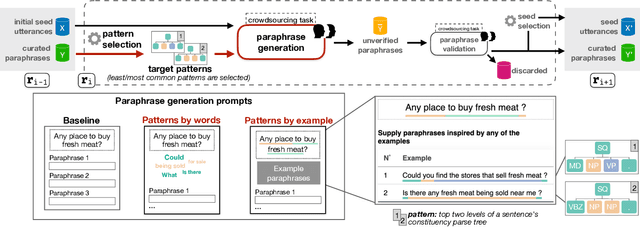
A prominent approach to build datasets for training task-oriented bots is crowd-based paraphrasing. Current approaches, however, assume the crowd would naturally provide diverse paraphrases or focus only on lexical diversity. In this WiP we addressed an overlooked aspect of diversity, introducing an approach for guiding the crowdsourcing process towards paraphrases that are syntactically diverse.
Active Hybrid Classification
Jan 21, 2021
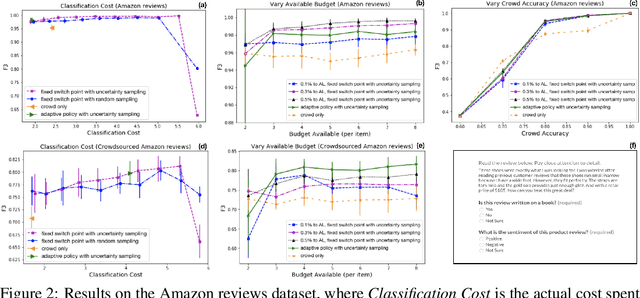
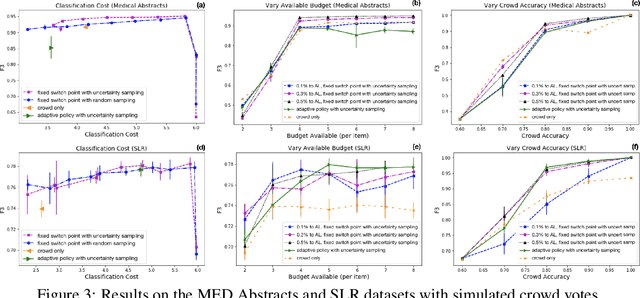
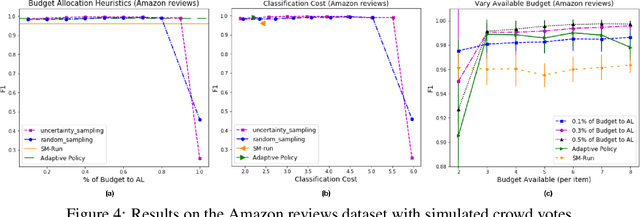
Hybrid crowd-machine classifiers can achieve superior performance by combining the cost-effectiveness of automatic classification with the accuracy of human judgment. This paper shows how crowd and machines can support each other in tackling classification problems. Specifically, we propose an architecture that orchestrates active learning and crowd classification and combines them in a virtuous cycle. We show that when the pool of items to classify is finite we face learning vs. exploitation trade-off in hybrid classification, as we need to balance crowd tasks optimized for creating a training dataset with tasks optimized for classifying items in the pool. We define the problem, propose a set of heuristics and evaluate the approach on three real-world datasets with different characteristics in terms of machine and crowd classification performance, showing that our active hybrid approach significantly outperforms baselines.
Chatbots as conversational healthcare services
Nov 08, 2020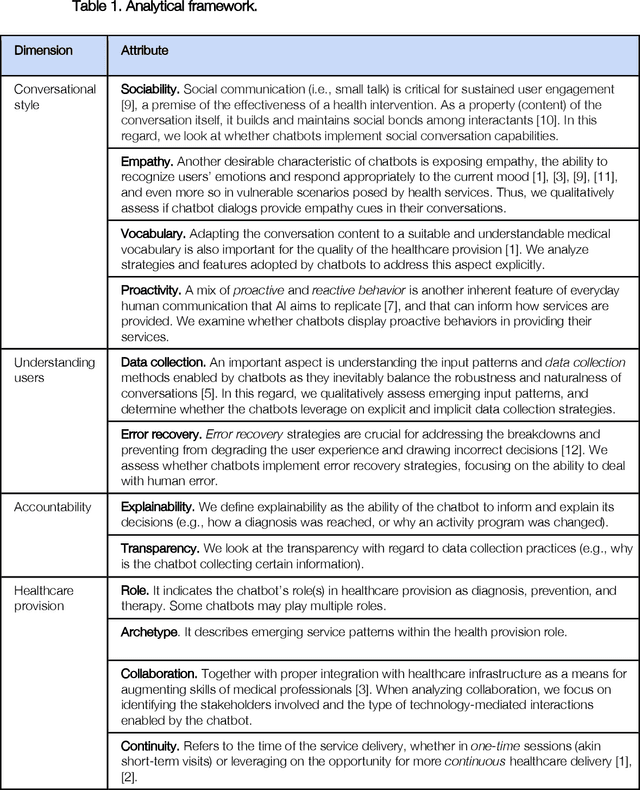
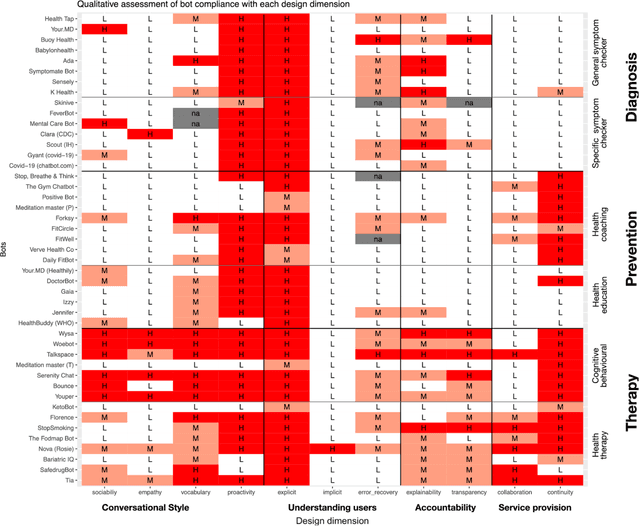
Chatbots are emerging as a promising platform for accessing and delivering healthcare services. The evidence is in the growing number of publicly available chatbots aiming at taking an active role in the provision of prevention, diagnosis, and treatment services. This article takes a closer look at how these emerging chatbots address design aspects relevant to healthcare service provision, emphasizing the Human-AI interaction aspects and the transparency in AI automation and decision making.
Siamese Graph Neural Networks for Data Integration
Jan 17, 2020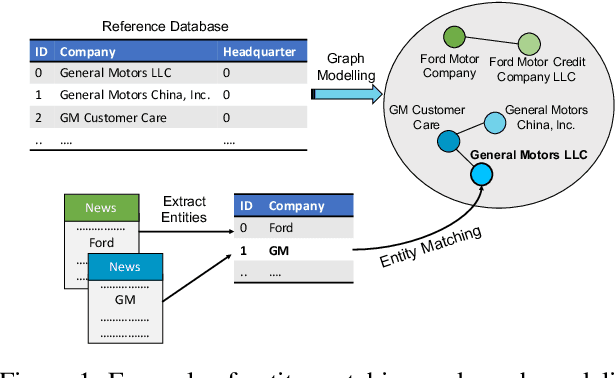

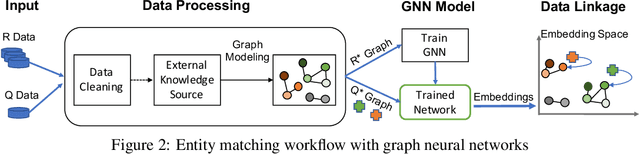
Data integration has been studied extensively for decades and approached from different angles. However, this domain still remains largely rule-driven and lacks universal automation. Recent development in machine learning and in particular deep learning has opened the way to more general and more efficient solutions to data integration problems. In this work, we propose a general approach to modeling and integrating entities from structured data, such as relational databases, as well as unstructured sources, such as free text from news articles. Our approach is designed to explicitly model and leverage relations between entities, thereby using all available information and preserving as much context as possible. This is achieved by combining siamese and graph neural networks to propagate information between connected entities and support high scalability. We evaluate our method on the task of integrating data about business entities, and we demonstrate that it outperforms standard rule-based systems, as well as other deep learning approaches that do not use graph-based representations.
Combining Crowd and Machines for Multi-predicate Item Screening
Apr 01, 2019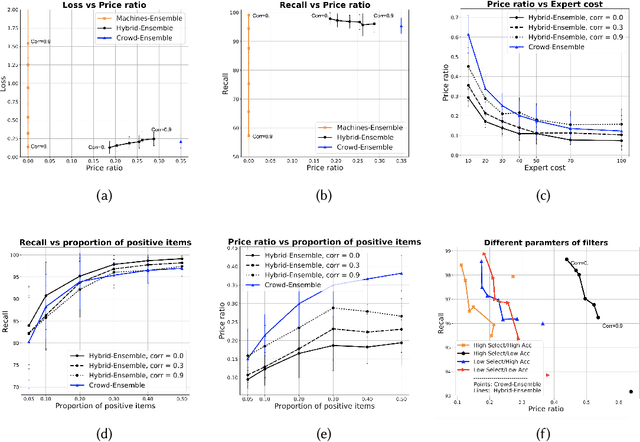

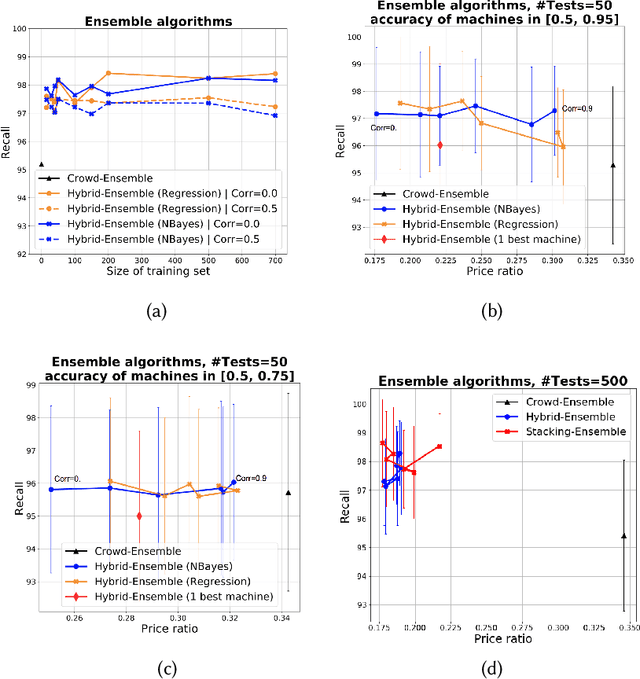
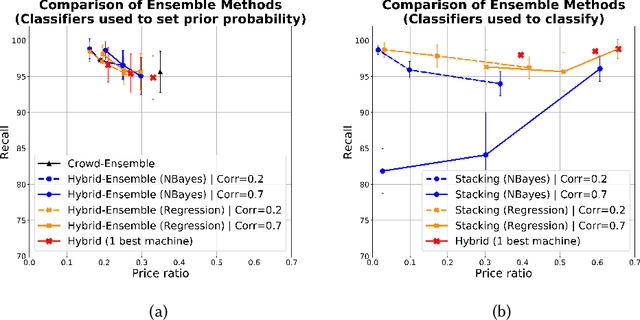
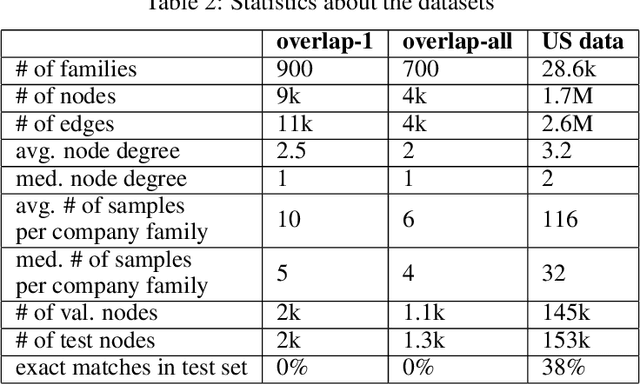
This paper discusses how crowd and machine classifiers can be efficiently combined to screen items that satisfy a set of predicates. We show that this is a recurring problem in many domains, present machine-human (hybrid) algorithms that screen items efficiently and estimate the gain over human-only or machine-only screening in terms of performance and cost. We further show how, given a new classification problem and a set of classifiers of unknown accuracy for the problem at hand, we can identify how to manage the cost-accuracy trade off by progressively determining if we should spend budget to obtain test data (to assess the accuracy of the given classifiers), or to train an ensemble of classifiers, or whether we should leverage the existing machine classifiers with the crowd, and in this case how to efficiently combine them based on their estimated characteristics to obtain the classification. We demonstrate that the techniques we propose obtain significant cost/accuracy improvements with respect to the leading classification algorithms.