Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Value of ML Models
Paper and Code
Dec 13, 2021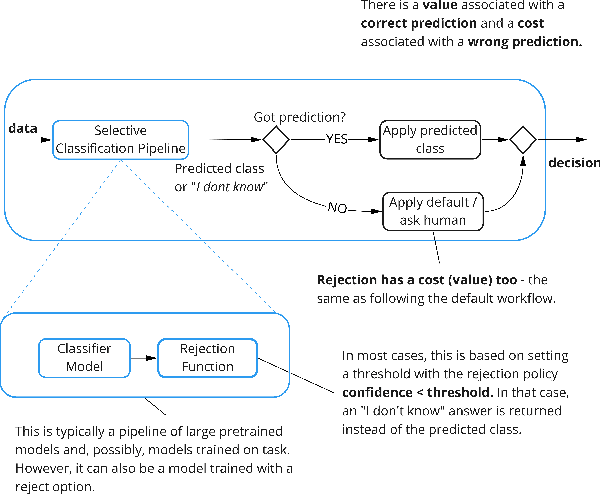
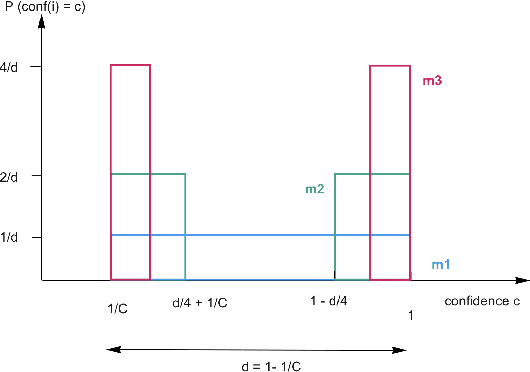
We argue that, when establishing and benchmarking Machine Learning (ML) models, the research community should favour evaluation metrics that better capture the value delivered by their model in practical applications. For a specific class of use cases -- selective classification -- we show that not only can it be simple enough to do, but that it has import consequences and provides insights what to look for in a ``good'' ML model.
* Fabio Casati, Pierre-Andr\'e No\"el and Jie Yang (2021, December
14). On the Value of ML Models [Poster presentation]. Workshop on Human and
Machine Decisions, NeurIPS 2021, virtual.
https://sites.google.com/view/whmd2021 * Poster presentation at Workshop on Human and Machine Decisions at
NeurIPS 2021 (WHMD 2021). https://sites.google.com/view/whmd2021
View paper on