 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Autoregressive and Diffusion-Based Sequence Generation
Apr 08, 2025



We present significant extensions to diffusion-based sequence generation models, blurring the line with autoregressive language models. We introduce hyperschedules, which assign distinct noise schedules to individual token positions, generalizing both autoregressive models (e.g., GPT) and conventional diffusion models (e.g., SEDD, MDLM) as special cases. Second, we propose two hybrid token-wise noising processes that interpolate between absorbing and uniform processes, enabling the model to fix past mistakes, and we introduce a novel inference algorithm that leverages this new feature in a simplified context inspired from MDLM. To support efficient training and inference, we design attention masks compatible with KV-caching. Our methods achieve state-of-the-art perplexity and generate diverse, high-quality sequences across standard benchmarks, suggesting a promising path for autoregressive diffusion-based sequence generation.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
XC-Cache: Cross-Attending to Cached Context for Efficient LLM Inference
Apr 23, 2024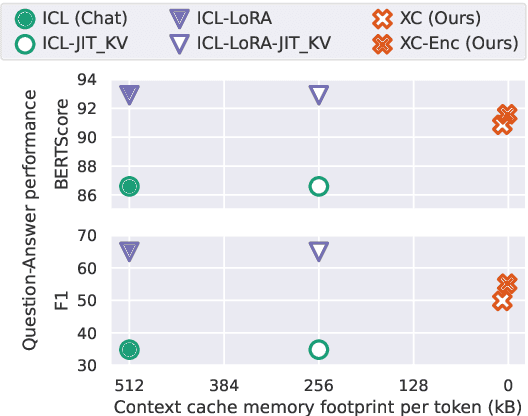
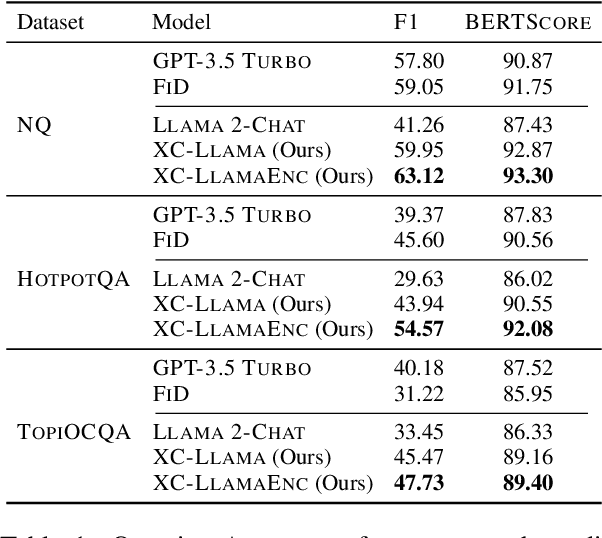
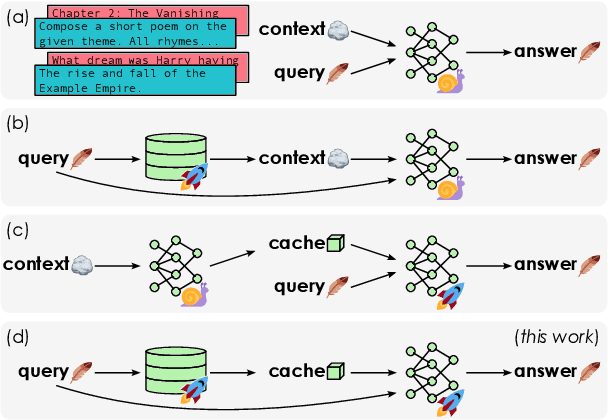
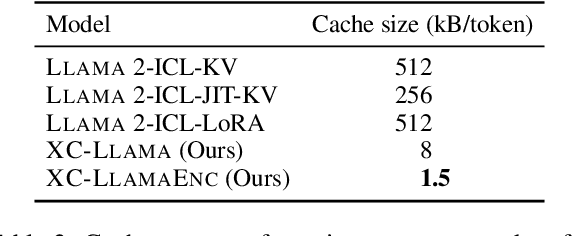
In-context learning (ICL) approaches typically leverage prompting to condition decoder-only language model generation on reference information. Just-in-time processing of a context is inefficient due to the quadratic cost of self-attention operations, and caching is desirable. However, caching transformer states can easily require almost as much space as the model parameters. When the right context isn't known in advance, caching ICL can be challenging. This work addresses these limitations by introducing models that, inspired by the encoder-decoder architecture, use cross-attention to condition generation on reference text without the prompt. More precisely, we leverage pre-trained decoder-only models and only train a small number of added layers. We use Question-Answering (QA) as a testbed to evaluate the ability of our models to perform conditional generation and observe that they outperform ICL, are comparable to fine-tuned prompted LLMs, and drastically reduce the space footprint relative to standard KV caching by two orders of magnitude.
Expecting The Unexpected: Towards Broad Out-Of-Distribution Detection
Aug 22, 2023



Improving the reliability of deployed machine learning systems often involves developing methods to detect out-of-distribution (OOD) inputs. However, existing research often narrowly focuses on samples from classes that are absent from the training set, neglecting other types of plausible distribution shifts. This limitation reduces the applicability of these methods in real-world scenarios, where systems encounter a wide variety of anomalous inputs. In this study, we categorize five distinct types of distribution shifts and critically evaluate the performance of recent OOD detection methods on each of them. We publicly release our benchmark under the name BROAD (Benchmarking Resilience Over Anomaly Diversity). Our findings reveal that while these methods excel in detecting unknown classes, their performance is inconsistent when encountering other types of distribution shifts. In other words, they only reliably detect unexpected inputs that they have been specifically designed to expect. As a first step toward broad OOD detection, we learn a generative model of existing detection scores with a Gaussian mixture. By doing so, we present an ensemble approach that offers a more consistent and comprehensive solution for broad OOD detection, demonstrating superior performance compared to existing methods. Our code to download BROAD and reproduce our experiments is publicly available.
Flaky Performances when Pretraining on Relational Databases
Nov 09, 2022We explore the downstream task performances for graph neural network (GNN) self-supervised learning (SSL) methods trained on subgraphs extracted from relational databases (RDBs). Intuitively, this joint use of SSL and GNNs should allow to leverage more of the available data, which could translate to better results. However, we found that naively porting contrastive SSL techniques can cause ``negative transfer'': linear evaluation on fixed representations from a pretrained model performs worse than on representations from the randomly-initialized model. Based on the conjecture that contrastive SSL conflicts with the message passing layers of the GNN, we propose InfoNode: a contrastive loss aiming to maximize the mutual information between a node's initial- and final-layer representation. The primary empirical results support our conjecture and the effectiveness of InfoNode.
On the Value of ML Models
Dec 13, 2021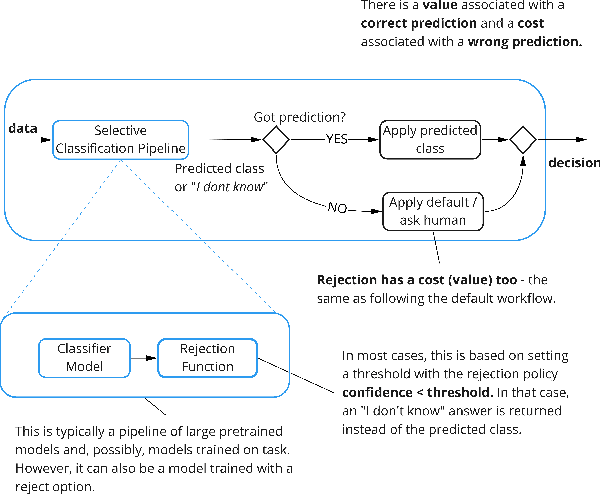
We argue that, when establishing and benchmarking Machine Learning (ML) models, the research community should favour evaluation metrics that better capture the value delivered by their model in practical applications. For a specific class of use cases -- selective classification -- we show that not only can it be simple enough to do, but that it has import consequences and provides insights what to look for in a ``good'' ML model.
* Poster presentation at Workshop on Human and Machine Decisions at NeurIPS 2021 (WHMD 2021). https://sites.google.com/view/whmd2021