 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortizing Maximum Inner Product Search with Learned Support Functions
Mar 09, 2026Maximum inner product search (MIPS) is a crucial subroutine in machine learning, requiring the identification of key vectors that align best with a given query. We propose amortized MIPS: a learning-based approach that trains neural networks to directly predict MIPS solutions, amortizing the computational cost of matching queries (drawn from a fixed distribution) to a fixed set of keys. Our key insight is that the MIPS value function, the maximal inner product between a query and keys, is also known as the support function of the set of keys. Support functions are convex, 1-homogeneous and their gradient w.r.t. the query is exactly the optimal key in the database. We approximate the support function using two complementary approaches: (1) we train an input-convex neural network (SupportNet) to model the support function directly; the optimal key can be recovered via (autodiff) gradient computation, and (2) we regress directly the optimal key from the query using a vector valued network (KeyNet), bypassing gradient computation entirely at inference time. To learn a SupportNet, we combine score regression with gradient matching losses, and propose homogenization wrappers that enforce the positive 1-homogeneity of a neural network, theoretically linking function values to gradients. To train a KeyNet, we introduce a score consistency loss derived from the Euler theorem for homogeneous functions. Our experiments show that learned SupportNet or KeyNet achieve high match rates and open up new directions to compress databases with a specific query distribution in mind.
LaCy: What Small Language Models Can and Should Learn is Not Just a Question of Loss
Feb 13, 2026Language models have consistently grown to compress more world knowledge into their parameters, but the knowledge that can be pretrained into them is upper-bounded by their parameter size. Especially the capacity of Small Language Models (SLMs) is limited, leading to factually incorrect generations. This problem is often mitigated by giving the SLM access to an outside source: the ability to query a larger model, documents, or a database. Under this setting, we study the fundamental question of \emph{which tokens an SLM can and should learn} during pretraining, versus \emph{which ones it should delegate} via a \texttt{<CALL>} token. We find that this is not simply a question of loss: although the loss is predictive of whether a predicted token mismatches the ground-truth, some tokens are \emph{acceptable} in that they are truthful alternative continuations of a pretraining document, and should not trigger a \texttt{<CALL>} even if their loss is high. We find that a spaCy grammar parser can help augment the loss signal to decide which tokens the SLM should learn to delegate to prevent factual errors and which are safe to learn and predict even under high losses. We propose LaCy, a novel pretraining method based on this token selection philosophy. Our experiments demonstrate that LaCy models successfully learn which tokens to predict and where to delegate for help. This results in higher FactScores when generating in a cascade with a bigger model and outperforms Rho or LLM-judge trained SLMs, while being simpler and cheaper.
Learning Unmasking Policies for Diffusion Language Models
Dec 12, 2025Diffusion (Large) Language Models (dLLMs) now match the downstream performance of their autoregressive counterparts on many tasks, while holding the promise of being more efficient during inference. One particularly successful variant is masked discrete diffusion, in which a buffer filled with special mask tokens is progressively replaced with tokens sampled from the model's vocabulary. Efficiency can be gained by unmasking several tokens in parallel, but doing too many at once risks degrading the generation quality. Thus, one critical design aspect of dLLMs is the sampling procedure that selects, at each step of the diffusion process, which tokens to replace. Indeed, recent work has found that heuristic strategies such as confidence thresholding lead to both higher quality and token throughput compared to random unmasking. However, such heuristics have downsides: they require manual tuning, and we observe that their performance degrades with larger buffer sizes. In this work, we instead propose to train sampling procedures using reinforcement learning. Specifically, we formalize masked diffusion sampling as a Markov decision process in which the dLLM serves as the environment, and propose a lightweight policy architecture based on a single-layer transformer that maps dLLM token confidences to unmasking decisions. Our experiments show that these trained policies match the performance of state-of-the-art heuristics when combined with semi-autoregressive generation, while outperforming them in the full diffusion setting. We also examine the transferability of these policies, finding that they can generalize to new underlying dLLMs and longer sequence lengths. However, we also observe that their performance degrades when applied to out-of-domain data, and that fine-grained tuning of the accuracy-efficiency trade-off can be challenging with our approach.
CountPath: Automating Fragment Counting in Digital Pathology
Mar 13, 2025



Quality control of medical images is a critical component of digital pathology, ensuring that diagnostic images meet required standards. A pre-analytical task within this process is the verification of the number of specimen fragments, a process that ensures that the number of fragments on a slide matches the number documented in the macroscopic report. This step is important to ensure that the slides contain the appropriate diagnostic material from the grossing process, thereby guaranteeing the accuracy of subsequent microscopic examination and diagnosis. Traditionally, this assessment is performed manually, requiring significant time and effort while being subject to significant variability due to its subjective nature. To address these challenges, this study explores an automated approach to fragment counting using the YOLOv9 and Vision Transformer models. Our results demonstrate that the automated system achieves a level of performance comparable to expert assessments, offering a reliable and efficient alternative to manual counting. Additionally, we present findings on interobserver variability, showing that the automated approach achieves an accuracy of 86%, which falls within the range of variation observed among experts (82-88%), further supporting its potential for integration into routine pathology workflows.
One Model to Train them All: Hierarchical Self-Distillation for Enhanced Early Layer Embeddings
Mar 04, 2025Deploying language models often requires handling model size vs. performance trade-offs to satisfy downstream latency constraints while preserving the model's usefulness. Model distillation is commonly employed to reduce model size while maintaining acceptable performance. However, distillation can be inefficient since it involves multiple training steps. In this work, we introduce MODULARSTARENCODER, a modular multi-exit encoder with 1B parameters, useful for multiple tasks within the scope of code retrieval. MODULARSTARENCODER is trained with a novel self-distillation mechanism that significantly improves lower-layer representations-allowing different portions of the model to be used while still maintaining a good trade-off in terms of performance. Our architecture focuses on enhancing text-to-code and code-to-code search by systematically capturing syntactic and semantic structures across multiple levels of representation. Specific encoder layers are targeted as exit heads, allowing higher layers to guide earlier layers during training. This self-distillation effect improves intermediate representations, increasing retrieval recall at no extra training cost. In addition to the multi-exit scheme, our approach integrates a repository-level contextual loss that maximally utilizes the training context window, further enhancing the learned representations. We also release a new dataset constructed via code translation, seamlessly expanding traditional text-to-code benchmarks with code-to-code pairs across diverse programming languages. Experimental results highlight the benefits of self-distillation through multi-exit supervision.
PairBench: A Systematic Framework for Selecting Reliable Judge VLMs
Feb 21, 2025As large vision language models (VLMs) are increasingly used as automated evaluators, understanding their ability to effectively compare data pairs as instructed in the prompt becomes essential. To address this, we present PairBench, a low-cost framework that systematically evaluates VLMs as customizable similarity tools across various modalities and scenarios. Through PairBench, we introduce four metrics that represent key desiderata of similarity scores: alignment with human annotations, consistency for data pairs irrespective of their order, smoothness of similarity distributions, and controllability through prompting. Our analysis demonstrates that no model, whether closed- or open-source, is superior on all metrics; the optimal choice depends on an auto evaluator's desired behavior (e.g., a smooth vs. a sharp judge), highlighting risks of widespread adoption of VLMs as evaluators without thorough assessment. For instance, the majority of VLMs struggle with maintaining symmetric similarity scores regardless of order. Additionally, our results show that the performance of VLMs on the metrics in PairBench closely correlates with popular benchmarks, showcasing its predictive power in ranking models.
XC-Cache: Cross-Attending to Cached Context for Efficient LLM Inference
Apr 23, 2024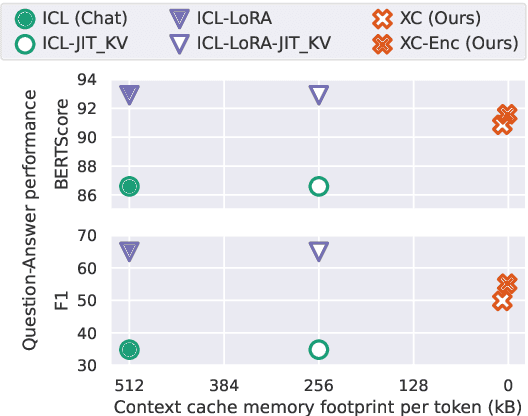
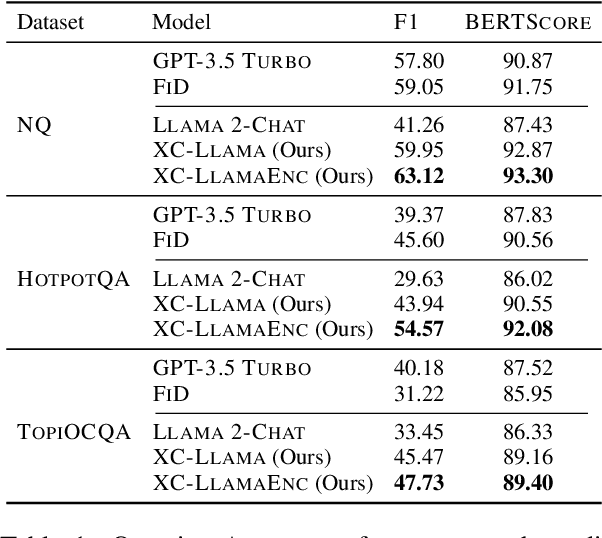
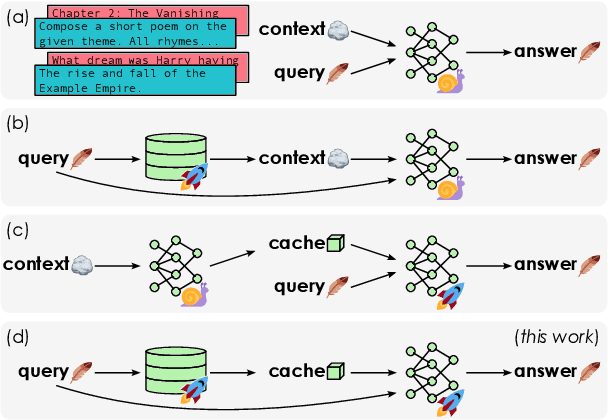
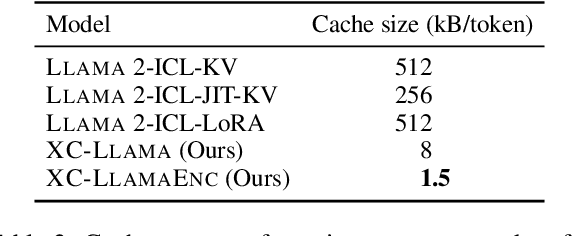
In-context learning (ICL) approaches typically leverage prompting to condition decoder-only language model generation on reference information. Just-in-time processing of a context is inefficient due to the quadratic cost of self-attention operations, and caching is desirable. However, caching transformer states can easily require almost as much space as the model parameters. When the right context isn't known in advance, caching ICL can be challenging. This work addresses these limitations by introducing models that, inspired by the encoder-decoder architecture, use cross-attention to condition generation on reference text without the prompt. More precisely, we leverage pre-trained decoder-only models and only train a small number of added layers. We use Question-Answering (QA) as a testbed to evaluate the ability of our models to perform conditional generation and observe that they outperform ICL, are comparable to fine-tuned prompted LLMs, and drastically reduce the space footprint relative to standard KV caching by two orders of magnitude.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
A CAD System for Colorectal Cancer from WSI: A Clinically Validated Interpretable ML-based Prototype
Jan 06, 2023The integration of Artificial Intelligence (AI) and Digital Pathology has been increasing over the past years. Nowadays, applications of deep learning (DL) methods to diagnose cancer from whole-slide images (WSI) are, more than ever, a reality within different research groups. Nonetheless, the development of these systems was limited by a myriad of constraints regarding the lack of training samples, the scaling difficulties, the opaqueness of DL methods, and, more importantly, the lack of clinical validation. As such, we propose a system designed specifically for the diagnosis of colorectal samples. The construction of such a system consisted of four stages: (1) a careful data collection and annotation process, which resulted in one of the largest WSI colorectal samples datasets; (2) the design of an interpretable mixed-supervision scheme to leverage the domain knowledge introduced by pathologists through spatial annotations; (3) the development of an effective sampling approach based on the expected severeness of each tile, which decreased the computation cost by a factor of almost 6x; (4) the creation of a prototype that integrates the full set of features of the model to be evaluated in clinical practice. During these stages, the proposed method was evaluated in four separate test sets, two of them are external and completely independent. On the largest of those sets, the proposed approach achieved an accuracy of 93.44%. DL for colorectal samples is a few steps closer to stop being research exclusive and to become fully integrated in clinical practice.
Adversarial target-invariant representation learning for domain generalization
Nov 03, 2019
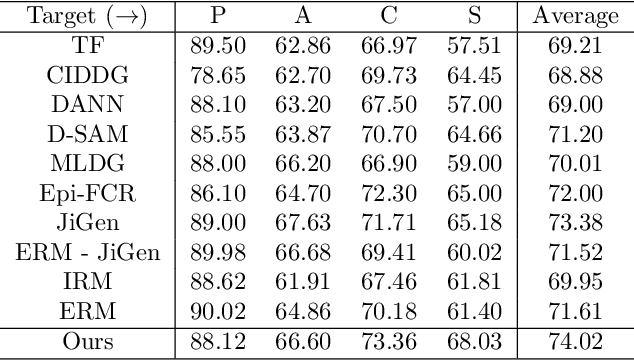
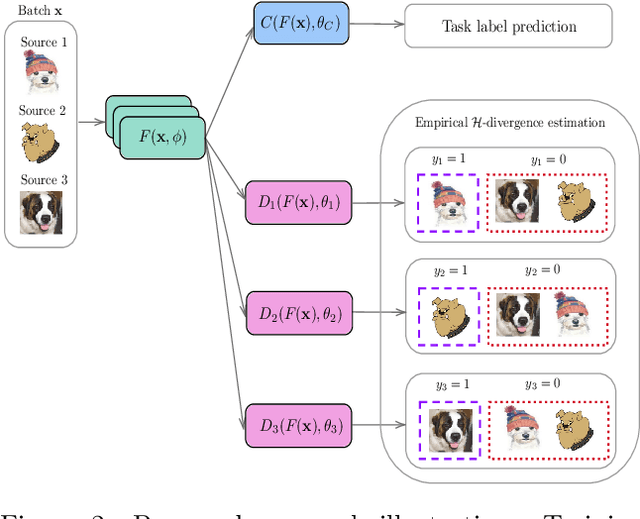
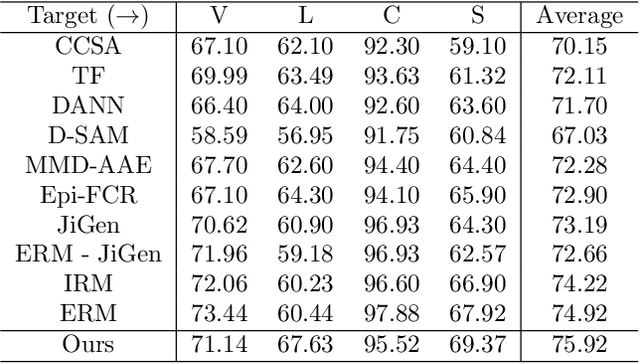
In many applications of machine learning, the training and test set data come from different distributions, or domains. A number of domain generalization strategies have been introduced with the goal of achieving good performance on out-of-distribution data. In this paper, we propose an adversarial approach to the problem. We propose a process that enforces pair-wise domain invariance while training a feature extractor over a diverse set of domains. We show that this process ensures invariance to any distribution that can be expressed as a mixture of the training domains. Following this insight, we then introduce an adversarial approach in which pair-wise divergences are estimated and minimized. Experiments on two domain generalization benchmarks for object recognition (i.e., PACS and VLCS) show that the proposed method yields higher average accuracy on the target domains in comparison to previously introduced adversarial strategies, as well as recently proposed methods based on learning invariant representations.