 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
How Knowledge Distillation Mitigates the Synthetic Gap in Fair Face Recognition
Aug 30, 2024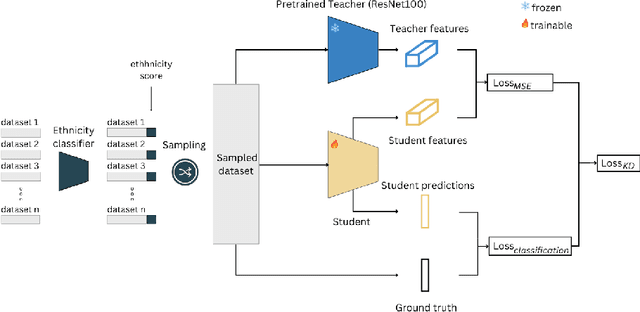
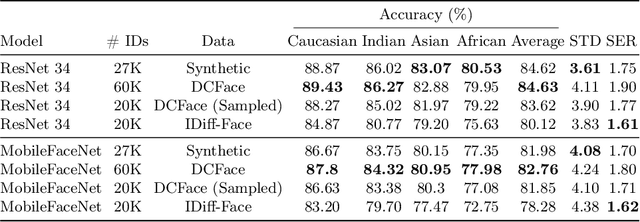

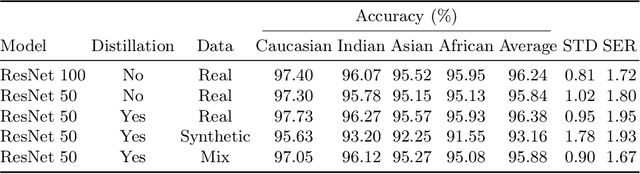
Leveraging the capabilities of Knowledge Distillation (KD) strategies, we devise a strategy to fight the recent retraction of face recognition datasets. Given a pretrained Teacher model trained on a real dataset, we show that carefully utilising synthetic datasets, or a mix between real and synthetic datasets to distil knowledge from this teacher to smaller students can yield surprising results. In this sense, we trained 33 different models with and without KD, on different datasets, with different architectures and losses. And our findings are consistent, using KD leads to performance gains across all ethnicities and decreased bias. In addition, it helps to mitigate the performance gap between real and synthetic datasets. This approach addresses the limitations of synthetic data training, improving both the accuracy and fairness of face recognition models.
MST-KD: Multiple Specialized Teachers Knowledge Distillation for Fair Face Recognition
Aug 29, 2024



As in school, one teacher to cover all subjects is insufficient to distill equally robust information to a student. Hence, each subject is taught by a highly specialised teacher. Following a similar philosophy, we propose a multiple specialized teacher framework to distill knowledge to a student network. In our approach, directed at face recognition use cases, we train four teachers on one specific ethnicity, leading to four highly specialized and biased teachers. Our strategy learns a project of these four teachers into a common space and distill that information to a student network. Our results highlighted increased performance and reduced bias for all our experiments. In addition, we further show that having biased/specialized teachers is crucial by showing that our approach achieves better results than when knowledge is distilled from four teachers trained on balanced datasets. Our approach represents a step forward to the understanding of the importance of ethnicity-specific features.
Fairness Under Cover: Evaluating the Impact of Occlusions on Demographic Bias in Facial Recognition
Aug 19, 2024This study investigates the effects of occlusions on the fairness of face recognition systems, particularly focusing on demographic biases. Using the Racial Faces in the Wild (RFW) dataset and synthetically added realistic occlusions, we evaluate their effect on the performance of face recognition models trained on the BUPT-Balanced and BUPT-GlobalFace datasets. We note increases in the dispersion of FMR, FNMR, and accuracy alongside decreases in fairness according to Equilized Odds, Demographic Parity, STD of Accuracy, and Fairness Discrepancy Rate. Additionally, we utilize a pixel attribution method to understand the importance of occlusions in model predictions, proposing a new metric, Face Occlusion Impact Ratio (FOIR), that quantifies the extent to which occlusions affect model performance across different demographic groups. Our results indicate that occlusions exacerbate existing demographic biases, with models placing higher importance on occlusions in an unequal fashion, particularly affecting African individuals more severely.
Massively Annotated Datasets for Assessment of Synthetic and Real Data in Face Recognition
Apr 23, 2024


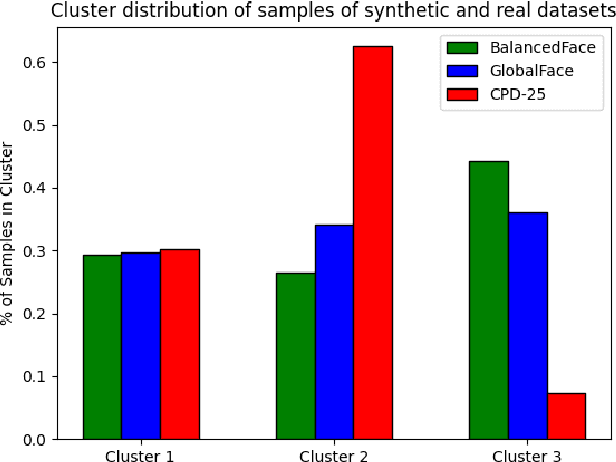
Face recognition applications have grown in parallel with the size of datasets, complexity of deep learning models and computational power. However, while deep learning models evolve to become more capable and computational power keeps increasing, the datasets available are being retracted and removed from public access. Privacy and ethical concerns are relevant topics within these domains. Through generative artificial intelligence, researchers have put efforts into the development of completely synthetic datasets that can be used to train face recognition systems. Nonetheless, the recent advances have not been sufficient to achieve performance comparable to the state-of-the-art models trained on real data. To study the drift between the performance of models trained on real and synthetic datasets, we leverage a massive attribute classifier (MAC) to create annotations for four datasets: two real and two synthetic. From these annotations, we conduct studies on the distribution of each attribute within all four datasets. Additionally, we further inspect the differences between real and synthetic datasets on the attribute set. When comparing through the Kullback-Leibler divergence we have found differences between real and synthetic samples. Interestingly enough, we have verified that while real samples suffice to explain the synthetic distribution, the opposite could not be further from being true.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Model Compression Techniques in Biometrics Applications: A Survey
Jan 18, 2024
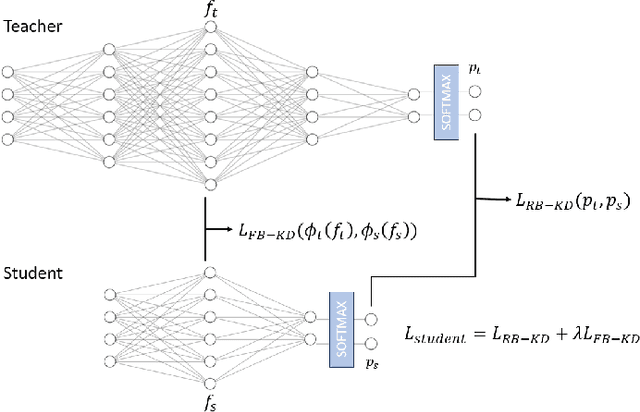
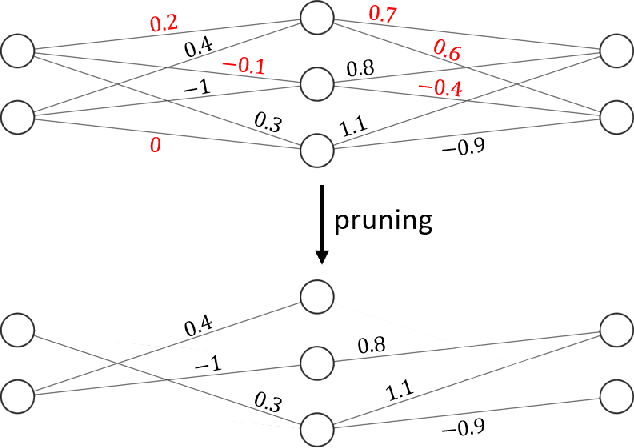
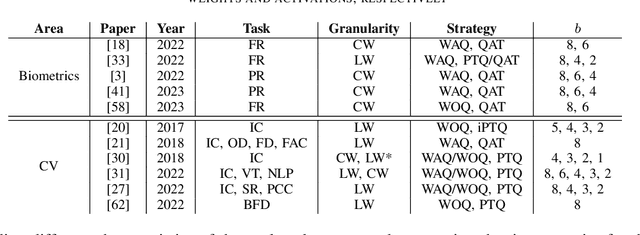
The development of deep learning algorithms has extensively empowered humanity's task automatization capacity. However, the huge improvement in the performance of these models is highly correlated with their increasing level of complexity, limiting their usefulness in human-oriented applications, which are usually deployed in resource-constrained devices. This led to the development of compression techniques that drastically reduce the computational and memory costs of deep learning models without significant performance degradation. This paper aims to systematize the current literature on this topic by presenting a comprehensive survey of model compression techniques in biometrics applications, namely quantization, knowledge distillation and pruning. We conduct a critical analysis of the comparative value of these techniques, focusing on their advantages and disadvantages and presenting suggestions for future work directions that can potentially improve the current methods. Additionally, we discuss and analyze the link between model bias and model compression, highlighting the need to direct compression research toward model fairness in future works.
Compressed Models Decompress Race Biases: What Quantized Models Forget for Fair Face Recognition
Aug 23, 2023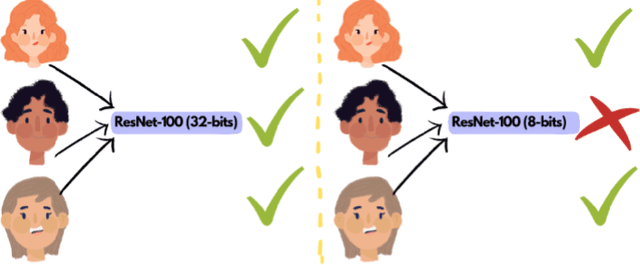
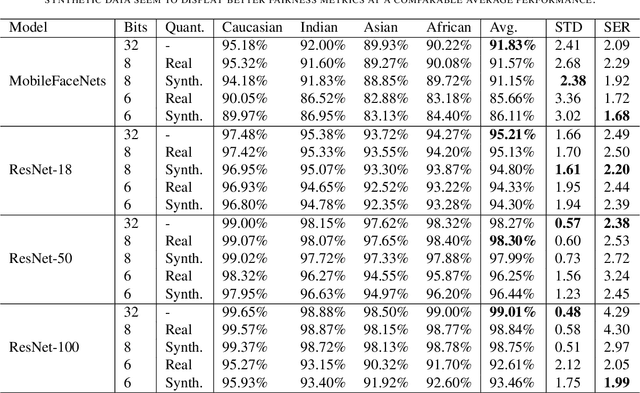
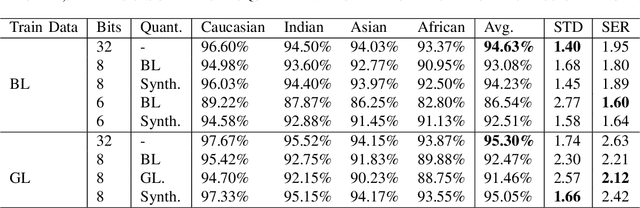
With the ever-growing complexity of deep learning models for face recognition, it becomes hard to deploy these systems in real life. Researchers have two options: 1) use smaller models; 2) compress their current models. Since the usage of smaller models might lead to concerning biases, compression gains relevance. However, compressing might be also responsible for an increase in the bias of the final model. We investigate the overall performance, the performance on each ethnicity subgroup and the racial bias of a State-of-the-Art quantization approach when used with synthetic and real data. This analysis provides a few more details on potential benefits of performing quantization with synthetic data, for instance, the reduction of biases on the majority of test scenarios. We tested five distinct architectures and three different training datasets. The models were evaluated on a fourth dataset which was collected to infer and compare the performance of face recognition models on different ethnicity.
Unveiling the Two-Faced Truth: Disentangling Morphed Identities for Face Morphing Detection
Jun 05, 2023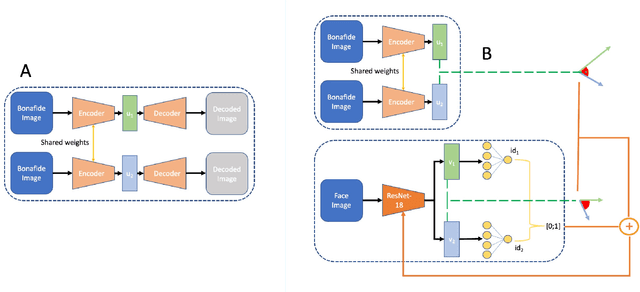

Morphing attacks keep threatening biometric systems, especially face recognition systems. Over time they have become simpler to perform and more realistic, as such, the usage of deep learning systems to detect these attacks has grown. At the same time, there is a constant concern regarding the lack of interpretability of deep learning models. Balancing performance and interpretability has been a difficult task for scientists. However, by leveraging domain information and proving some constraints, we have been able to develop IDistill, an interpretable method with state-of-the-art performance that provides information on both the identity separation on morph samples and their contribution to the final prediction. The domain information is learnt by an autoencoder and distilled to a classifier system in order to teach it to separate identity information. When compared to other methods in the literature it outperforms them in three out of five databases and is competitive in the remaining.
A CAD System for Colorectal Cancer from WSI: A Clinically Validated Interpretable ML-based Prototype
Jan 06, 2023The integration of Artificial Intelligence (AI) and Digital Pathology has been increasing over the past years. Nowadays, applications of deep learning (DL) methods to diagnose cancer from whole-slide images (WSI) are, more than ever, a reality within different research groups. Nonetheless, the development of these systems was limited by a myriad of constraints regarding the lack of training samples, the scaling difficulties, the opaqueness of DL methods, and, more importantly, the lack of clinical validation. As such, we propose a system designed specifically for the diagnosis of colorectal samples. The construction of such a system consisted of four stages: (1) a careful data collection and annotation process, which resulted in one of the largest WSI colorectal samples datasets; (2) the design of an interpretable mixed-supervision scheme to leverage the domain knowledge introduced by pathologists through spatial annotations; (3) the development of an effective sampling approach based on the expected severeness of each tile, which decreased the computation cost by a factor of almost 6x; (4) the creation of a prototype that integrates the full set of features of the model to be evaluated in clinical practice. During these stages, the proposed method was evaluated in four separate test sets, two of them are external and completely independent. On the largest of those sets, the proposed approach achieved an accuracy of 93.44%. DL for colorectal samples is a few steps closer to stop being research exclusive and to become fully integrated in clinical practice.