 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Knowledge Distillation Mitigates the Synthetic Gap in Fair Face Recognition
Aug 30, 2024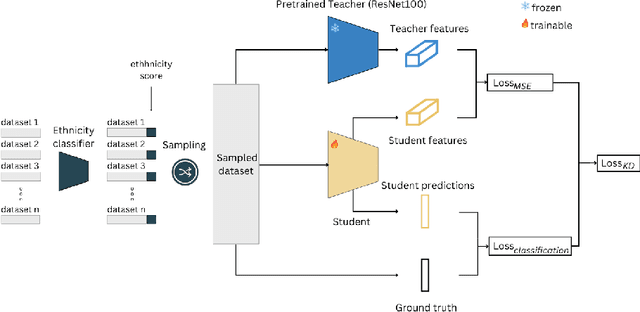
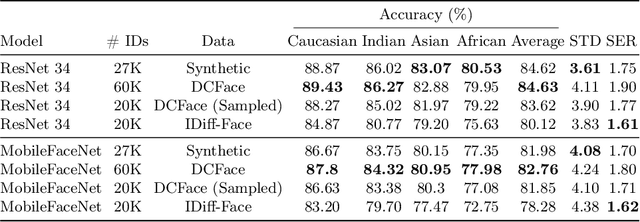

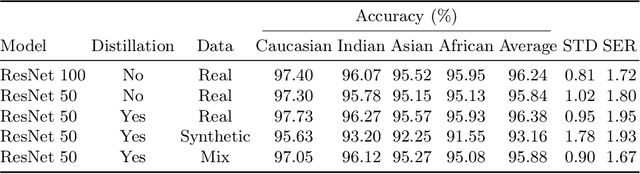
Leveraging the capabilities of Knowledge Distillation (KD) strategies, we devise a strategy to fight the recent retraction of face recognition datasets. Given a pretrained Teacher model trained on a real dataset, we show that carefully utilising synthetic datasets, or a mix between real and synthetic datasets to distil knowledge from this teacher to smaller students can yield surprising results. In this sense, we trained 33 different models with and without KD, on different datasets, with different architectures and losses. And our findings are consistent, using KD leads to performance gains across all ethnicities and decreased bias. In addition, it helps to mitigate the performance gap between real and synthetic datasets. This approach addresses the limitations of synthetic data training, improving both the accuracy and fairness of face recognition models.