 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTNT-FIQA: Training-Free Face Image Quality Assessment with Vision Transformers
Jan 09, 2026Face Image Quality Assessment (FIQA) is essential for reliable face recognition systems. Current approaches primarily exploit only final-layer representations, while training-free methods require multiple forward passes or backpropagation. We propose ViTNT-FIQA, a training-free approach that measures the stability of patch embedding evolution across intermediate Vision Transformer (ViT) blocks. We demonstrate that high-quality face images exhibit stable feature refinement trajectories across blocks, while degraded images show erratic transformations. Our method computes Euclidean distances between L2-normalized patch embeddings from consecutive transformer blocks and aggregates them into image-level quality scores. We empirically validate this correlation on a quality-labeled synthetic dataset with controlled degradation levels. Unlike existing training-free approaches, ViTNT-FIQA requires only a single forward pass without backpropagation or architectural modifications. Through extensive evaluation on eight benchmarks (LFW, AgeDB-30, CFP-FP, CALFW, Adience, CPLFW, XQLFW, IJB-C), we show that ViTNT-FIQA achieves competitive performance with state-of-the-art methods while maintaining computational efficiency and immediate applicability to any pre-trained ViT-based face recognition model.
Trustworthy and Explainable Deep Reinforcement Learning for Safe and Energy-Efficient Process Control: A Use Case in Industrial Compressed Air Systems
Dec 20, 2025This paper presents a trustworthy reinforcement learning approach for the control of industrial compressed air systems. We develop a framework that enables safe and energy-efficient operation under realistic boundary conditions and introduce a multi-level explainability pipeline combining input perturbation tests, gradient-based sensitivity analysis, and SHAP (SHapley Additive exPlanations) feature attribution. An empirical evaluation across multiple compressor configurations shows that the learned policy is physically plausible, anticipates future demand, and consistently respects system boundaries. Compared to the installed industrial controller, the proposed approach reduces unnecessary overpressure and achieves energy savings of approximately 4\,\% without relying on explicit physics models. The results further indicate that system pressure and forecast information dominate policy decisions, while compressor-level inputs play a secondary role. Overall, the combination of efficiency gains, predictive behavior, and transparent validation supports the trustworthy deployment of reinforcement learning in industrial energy systems.
Frequency Matters: Explaining Biases of Face Recognition in the Frequency Domain
Jan 28, 2025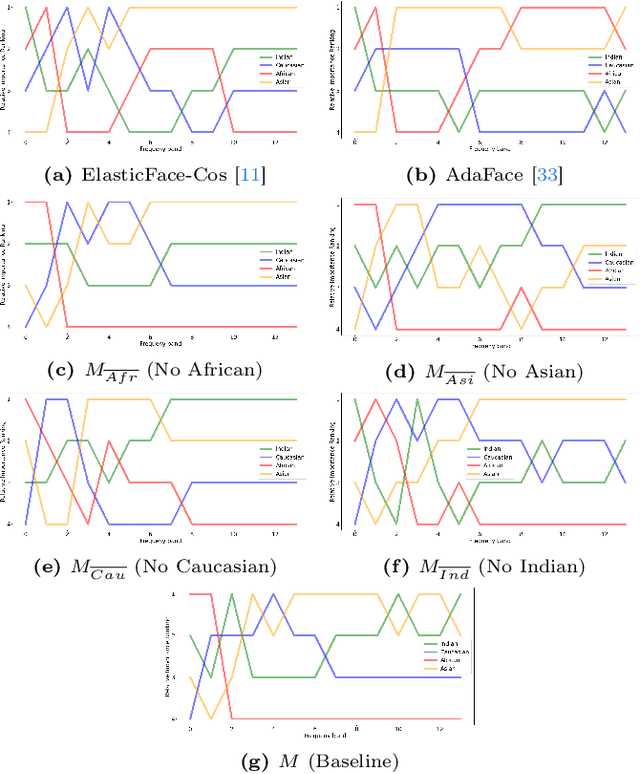
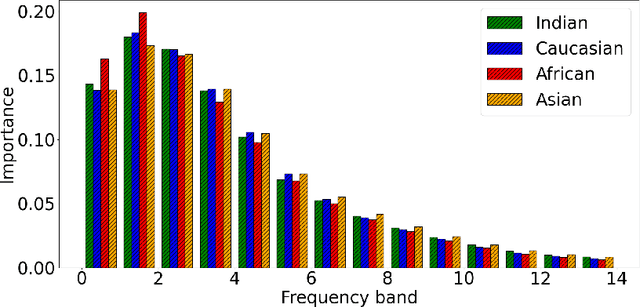
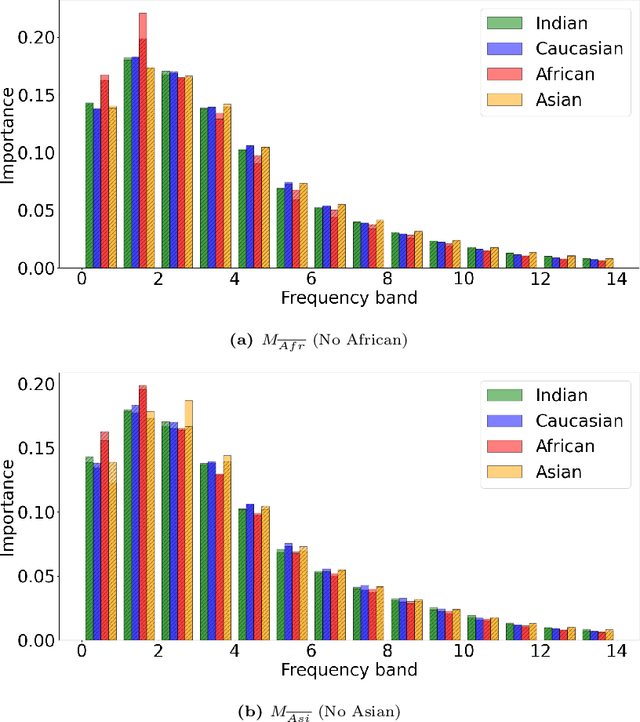
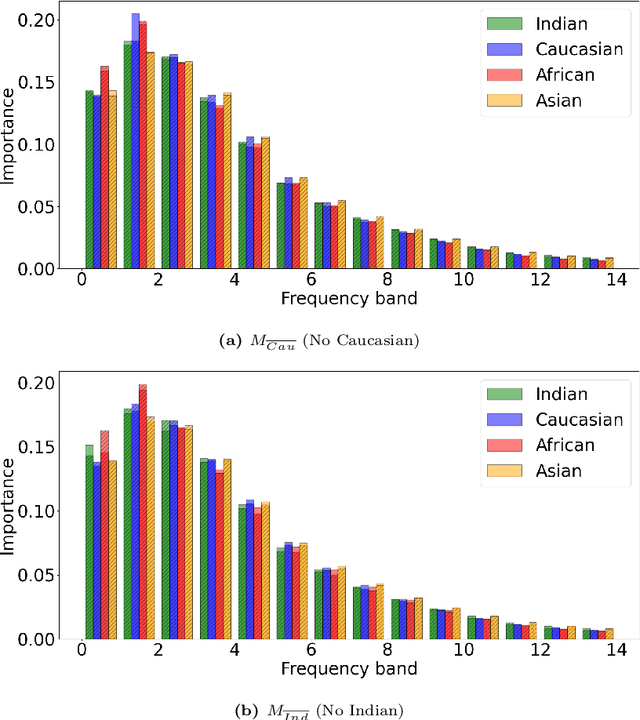
Face recognition (FR) models are vulnerable to performance variations across demographic groups. The causes for these performance differences are unclear due to the highly complex deep learning-based structure of face recognition models. Several works aimed at exploring possible roots of gender and ethnicity bias, identifying semantic reasons such as hairstyle, make-up, or facial hair as possible sources. Motivated by recent discoveries of the importance of frequency patterns in convolutional neural networks, we explain bias in face recognition using state-of-the-art frequency-based explanations. Our extensive results show that different frequencies are important to FR models depending on the ethnicity of the samples.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Beyond Spatial Explanations: Explainable Face Recognition in the Frequency Domain
Jul 16, 2024



The need for more transparent face recognition (FR), along with other visual-based decision-making systems has recently attracted more attention in research, society, and industry. The reasons why two face images are matched or not matched by a deep learning-based face recognition system are not obvious due to the high number of parameters and the complexity of the models. However, it is important for users, operators, and developers to ensure trust and accountability of the system and to analyze drawbacks such as biased behavior. While many previous works use spatial semantic maps to highlight the regions that have a significant influence on the decision of the face recognition system, frequency components which are also considered by CNNs, are neglected. In this work, we take a step forward and investigate explainable face recognition in the unexplored frequency domain. This makes this work the first to propose explainability of verification-based decisions in the frequency domain, thus explaining the relative influence of the frequency components of each input toward the obtained outcome. To achieve this, we manipulate face images in the spatial frequency domain and investigate the impact on verification outcomes. In extensive quantitative experiments, along with investigating two special scenarios cases, cross-resolution FR and morphing attacks (the latter in supplementary material), we observe the applicability of our proposed frequency-based explanations.
Classification Metrics for Image Explanations: Towards Building Reliable XAI-Evaluations
Jun 07, 2024



Decision processes of computer vision models - especially deep neural networks - are opaque in nature, meaning that these decisions cannot be understood by humans. Thus, over the last years, many methods to provide human-understandable explanations have been proposed. For image classification, the most common group are saliency methods, which provide (super-)pixelwise feature attribution scores for input images. But their evaluation still poses a problem, as their results cannot be simply compared to the unknown ground truth. To overcome this, a slew of different proxy metrics have been defined, which are - as the explainability methods themselves - often built on intuition and thus, are possibly unreliable. In this paper, new evaluation metrics for saliency methods are developed and common saliency methods are benchmarked on ImageNet. In addition, a scheme for reliability evaluation of such metrics is proposed that is based on concepts from psychometric testing. The used code can be found at https://github.com/lelo204/ClassificationMetricsForImageExplanations .
How should AI decisions be explained? Requirements for Explanations from the Perspective of European Law
Apr 19, 2024This paper investigates the relationship between law and eXplainable Artificial Intelligence (XAI). While there is much discussion about the AI Act, for which the trilogue of the European Parliament, Council and Commission recently concluded, other areas of law seem underexplored. This paper focuses on European (and in part German) law, although with international concepts and regulations such as fiduciary plausibility checks, the General Data Protection Regulation (GDPR), and product safety and liability. Based on XAI-taxonomies, requirements for XAI-methods are derived from each of the legal bases, resulting in the conclusion that each legal basis requires different XAI properties and that the current state of the art does not fulfill these to full satisfaction, especially regarding the correctness (sometimes called fidelity) and confidence estimates of XAI-methods.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Model Compression Techniques in Biometrics Applications: A Survey
Jan 18, 2024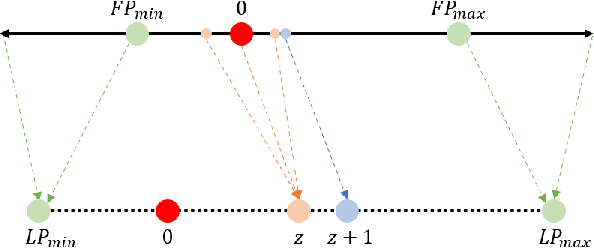
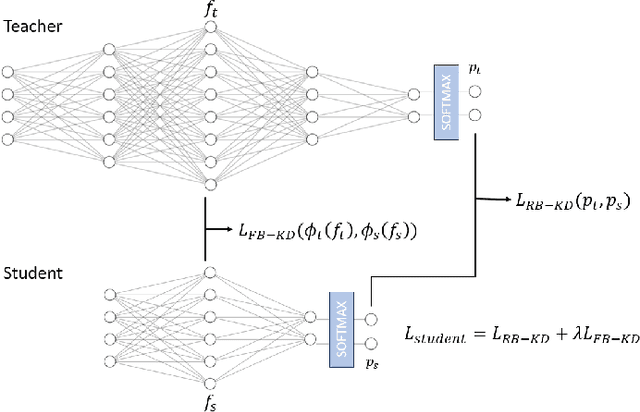
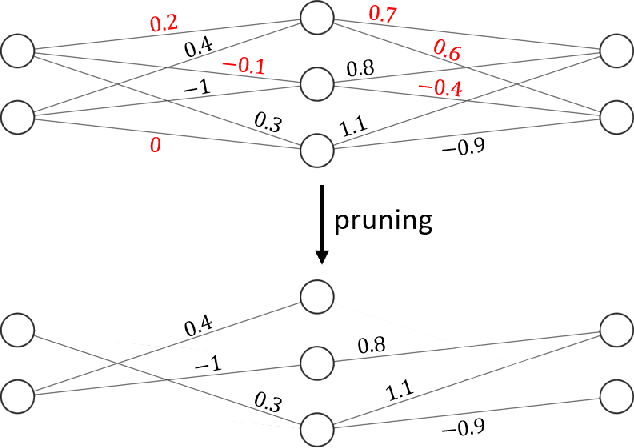
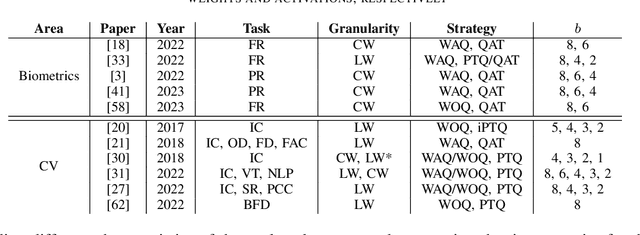
The development of deep learning algorithms has extensively empowered humanity's task automatization capacity. However, the huge improvement in the performance of these models is highly correlated with their increasing level of complexity, limiting their usefulness in human-oriented applications, which are usually deployed in resource-constrained devices. This led to the development of compression techniques that drastically reduce the computational and memory costs of deep learning models without significant performance degradation. This paper aims to systematize the current literature on this topic by presenting a comprehensive survey of model compression techniques in biometrics applications, namely quantization, knowledge distillation and pruning. We conduct a critical analysis of the comparative value of these techniques, focusing on their advantages and disadvantages and presenting suggestions for future work directions that can potentially improve the current methods. Additionally, we discuss and analyze the link between model bias and model compression, highlighting the need to direct compression research toward model fairness in future works.
SynFacePAD 2023: Competition on Face Presentation Attack Detection Based on Privacy-aware Synthetic Training Data
Nov 09, 2023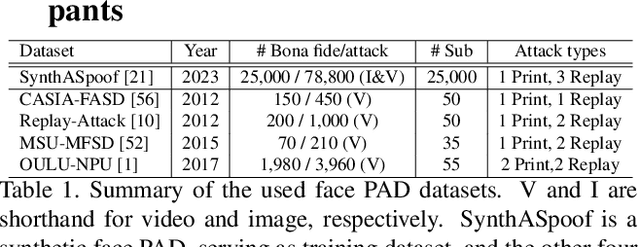

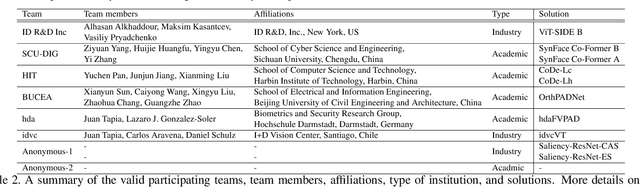
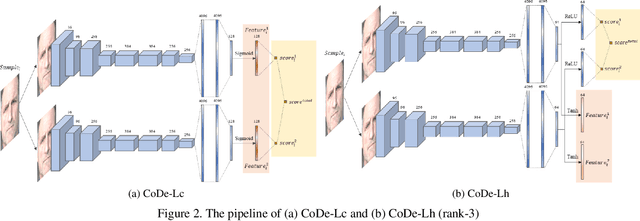
This paper presents a summary of the Competition on Face Presentation Attack Detection Based on Privacy-aware Synthetic Training Data (SynFacePAD 2023) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition attracted a total of 8 participating teams with valid submissions from academia and industry. The competition aimed to motivate and attract solutions that target detecting face presentation attacks while considering synthetic-based training data motivated by privacy, legal and ethical concerns associated with personal data. To achieve that, the training data used by the participants was limited to synthetic data provided by the organizers. The submitted solutions presented innovations and novel approaches that led to outperforming the considered baseline in the investigated benchmarks.