 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCMorph: Face Morphing via Dual-Stream Cross-Attention Diffusion
Apr 23, 2026Advancing face morphing attack techniques is crucial to anticipate evolving threats and develop robust defensive mechanisms for identity verification systems. This work introduces DCMorph, a dual-stream diffusion-based morphing framework that simultaneously operates at both identity conditioning and latent space levels. Unlike image-level methods suffering from blending artifacts or GAN-based approaches with limited reconstruction fidelity, DCMorph leverages identity-conditioned latent diffusion models through two mechanisms: (1) decoupled cross-attention interpolation that injects identity-specific features from both source faces into the denoising process, enabling explicit dual-identity conditioning absent in existing diffusion-based methods, and (2) DDIM inversion with spherical interpolation between inverted latent representations from both source faces, providing geometrically consistent initial latent representation that preserves structural attributes. Vulnerability analyses across four state-of-the-art face recognition systems demonstrate that DCMorph achieves the highest attack success rates compared to existing methods at both operational thresholds, while remaining challenging to detect by current morphing attack detection solutions.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
LoRA-Enhanced Vision Transformer for Single Image based Morphing Attack Detection via Knowledge Distillation from EfficientNet
Nov 16, 2025Face Recognition Systems (FRS) are critical for security but remain vulnerable to morphing attacks, where synthetic images blend biometric features from multiple individuals. We propose a novel Single-Image Morphing Attack Detection (S-MAD) approach using a teacher-student framework, where a CNN-based teacher model refines a ViT-based student model. To improve efficiency, we integrate Low-Rank Adaptation (LoRA) for fine-tuning, reducing computational costs while maintaining high detection accuracy. Extensive experiments are conducted on a morphing dataset built from three publicly available face datasets, incorporating ten different morphing generation algorithms to assess robustness. The proposed method is benchmarked against six state-of-the-art S-MAD techniques, demonstrating superior detection performance and computational efficiency.
StableMorph: High-Quality Face Morph Generation with Stable Diffusion
Nov 11, 2025Face morphing attacks threaten the integrity of biometric identity systems by enabling multiple individuals to share a single identity. To develop and evaluate effective morphing attack detection (MAD) systems, we need access to high-quality, realistic morphed images that reflect the challenges posed in real-world scenarios. However, existing morph generation methods often produce images that are blurry, riddled with artifacts, or poorly constructed making them easy to detect and not representative of the most dangerous attacks. In this work, we introduce StableMorph, a novel approach that generates highly realistic, artifact-free morphed face images using modern diffusion-based image synthesis. Unlike prior methods, StableMorph produces full-head images with sharp details, avoids common visual flaws, and offers unmatched control over visual attributes. Through extensive evaluation, we show that StableMorph images not only rival or exceed the quality of genuine face images but also maintain a strong ability to fool face recognition systems posing a greater challenge to existing MAD solutions and setting a new standard for morph quality in research and operational testing. StableMorph improves the evaluation of biometric security by creating more realistic and effective attacks and supports the development of more robust detection systems.
Introducing Nylon Face Mask Attacks: A Dataset for Evaluating Generalised Face Presentation Attack Detection
Nov 11, 2025Face recognition systems are increasingly deployed across a wide range of applications, including smartphone authentication, access control, and border security. However, these systems remain vulnerable to presentation attacks (PAs), which can significantly compromise their reliability. In this work, we introduce a new dataset focused on a novel and realistic presentation attack instrument called Nylon Face Masks (NFMs), designed to simulate advanced 3D spoofing scenarios. NFMs are particularly concerning due to their elastic structure and photorealistic appearance, which enable them to closely mimic the victim's facial geometry when worn by an attacker. To reflect real-world smartphone-based usage conditions, we collected the dataset using an iPhone 11 Pro, capturing 3,760 bona fide samples from 100 subjects and 51,281 NFM attack samples across four distinct presentation scenarios involving both humans and mannequins. We benchmark the dataset using five state-of-the-art PAD methods to evaluate their robustness under unseen attack conditions. The results demonstrate significant performance variability across methods, highlighting the challenges posed by NFMs and underscoring the importance of developing PAD techniques that generalise effectively to emerging spoofing threats.
LatentPrintFormer: A Hybrid CNN-Transformer with Spatial Attention for Latent Fingerprint identification
Nov 11, 2025Latent fingerprint identification remains a challenging task due to low image quality, background noise, and partial impressions. In this work, we propose a novel identification approach called LatentPrintFormer. The proposed model integrates a CNN backbone (EfficientNet-B0) and a Transformer backbone (Swin Tiny) to extract both local and global features from latent fingerprints. A spatial attention module is employed to emphasize high-quality ridge regions while suppressing background noise. The extracted features are fused and projected into a unified 512-dimensional embedding, and matching is performed using cosine similarity in a closed-set identification setting. Extensive experiments on two publicly available datasets demonstrate that LatentPrintFormer consistently outperforms three state-of-the-art latent fingerprint recognition techniques, achieving higher identification rates across Rank-10.
Empowering Morphing Attack Detection using Interpretable Image-Text Foundation Model
Aug 13, 2025Morphing attack detection has become an essential component of face recognition systems for ensuring a reliable verification scenario. In this paper, we present a multimodal learning approach that can provide a textual description of morphing attack detection. We first show that zero-shot evaluation of the proposed framework using Contrastive Language-Image Pretraining (CLIP) can yield not only generalizable morphing attack detection, but also predict the most relevant text snippet. We present an extensive analysis of ten different textual prompts that include both short and long textual prompts. These prompts are engineered by considering the human understandable textual snippet. Extensive experiments were performed on a face morphing dataset that was developed using a publicly available face biometric dataset. We present an evaluation of SOTA pre-trained neural networks together with the proposed framework in the zero-shot evaluation of five different morphing generation techniques that are captured in three different mediums.
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
Towards Zero-Shot Differential Morphing Attack Detection with Multimodal Large Language Models
May 21, 2025
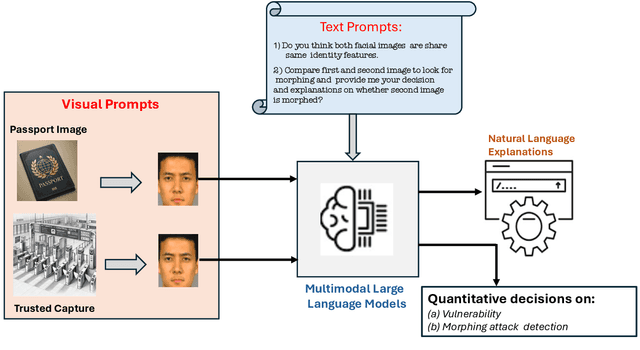

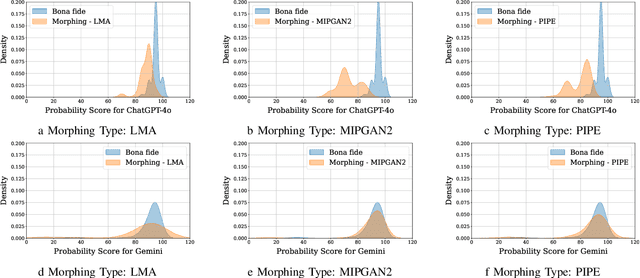
Leveraging the power of multimodal large language models (LLMs) offers a promising approach to enhancing the accuracy and interpretability of morphing attack detection (MAD), especially in real-world biometric applications. This work introduces the use of LLMs for differential morphing attack detection (D-MAD). To the best of our knowledge, this is the first study to employ multimodal LLMs to D-MAD using real biometric data. To effectively utilize these models, we design Chain-of-Thought (CoT)-based prompts to reduce failure-to-answer rates and enhance the reasoning behind decisions. Our contributions include: (1) the first application of multimodal LLMs for D-MAD using real data subjects, (2) CoT-based prompt engineering to improve response reliability and explainability, (3) comprehensive qualitative and quantitative benchmarking of LLM performance using data from 54 individuals captured in passport enrollment scenarios, and (4) comparative analysis of two multimodal LLMs: ChatGPT-4o and Gemini providing insights into their morphing attack detection accuracy and decision transparency. Experimental results show that ChatGPT-4o outperforms Gemini in detection accuracy, especially against GAN-based morphs, though both models struggle under challenging conditions. While Gemini offers more consistent explanations, ChatGPT-4o is more resilient but prone to a higher failure-to-answer rate.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.