 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackletGPT: A Language-like GPT Framework for White Matter Tract Segmentation
Jan 20, 2026White Matter Tract Segmentation is imperative for studying brain structural connectivity, neurological disorders and neurosurgery. This task remains complex, as tracts differ among themselves, across subjects and conditions, yet have similar 3D structure across hemispheres and subjects. To address these challenges, we propose TrackletGPT, a language-like GPT framework which reintroduces sequential information in tokens using tracklets. TrackletGPT generalises seamlessly across datasets, is fully automatic, and encodes granular sub-streamline segments, Tracklets, scaling and refining GPT models in Tractography Segmentation. Based on our experiments, TrackletGPT outperforms state-of-the-art methods on average DICE, Overlap and Overreach scores on TractoInferno and HCP datasets, even on inter-dataset experiments.
TractRLFusion: A GPT-Based Multi-Critic Policy Fusion Framework for Fiber Tractography
Jan 20, 2026Tractography plays a pivotal role in the non-invasive reconstruction of white matter fiber pathways, providing vital information on brain connectivity and supporting precise neurosurgical planning. Although traditional methods relied mainly on classical deterministic and probabilistic approaches, recent progress has benefited from supervised deep learning (DL) and deep reinforcement learning (DRL) to improve tract reconstruction. A persistent challenge in tractography is accurately reconstructing white matter tracts while minimizing spurious connections. To address this, we propose TractRLFusion, a novel GPT-based policy fusion framework that integrates multiple RL policies through a data-driven fusion strategy. Our method employs a two-stage training data selection process for effective policy fusion, followed by a multi-critic fine-tuning phase to enhance robustness and generalization. Experiments on HCP, ISMRM, and TractoInferno datasets demonstrate that TractRLFusion outperforms individual RL policies as well as state-of-the-art classical and DRL methods in accuracy and anatomical reliability.
EAD: An EEG Adapter for Automated Classification
May 29, 2025While electroencephalography (EEG) has been a popular modality for neural decoding, it often involves task specific acquisition of the EEG data. This poses challenges for the development of a unified pipeline to learn embeddings for various EEG signal classification, which is often involved in various decoding tasks. Traditionally, EEG classification involves the step of signal preprocessing and the use of deep learning techniques, which are highly dependent on the number of EEG channels in each sample. However, the same pipeline cannot be applied even if the EEG data is collected for the same experiment but with different acquisition devices. This necessitates the development of a framework for learning EEG embeddings, which could be highly beneficial for tasks involving multiple EEG samples for the same task but with varying numbers of EEG channels. In this work, we propose EEG Adapter (EAD), a flexible framework compatible with any signal acquisition device. More specifically, we leverage a recent EEG foundational model with significant adaptations to learn robust representations from the EEG data for the classification task. We evaluate EAD on two publicly available datasets achieving state-of-the-art accuracies 99.33% and 92.31% on EEG-ImageNet and BrainLat respectively. This illustrates the effectiveness of the proposed framework across diverse EEG datasets containing two different perception tasks: stimulus and resting-state EEG signals. We also perform zero-shot EEG classification on EEG-ImageNet task to demonstrate the generalization capability of the proposed approach.
TractoGPT: A GPT architecture for White Matter Segmentation
Jan 26, 2025



White matter bundle segmentation is crucial for studying brain structural connectivity, neurosurgical planning, and neurological disorders. White Matter Segmentation remains challenging due to structural similarity in streamlines, subject variability, symmetry in 2 hemispheres, etc. To address these challenges, we propose TractoGPT, a GPT-based architecture trained on streamline, cluster, and fusion data representations separately. TractoGPT is a fully-automatic method that generalizes across datasets and retains shape information of the white matter bundles. Experiments also show that TractoGPT outperforms state-of-the-art methods on average DICE, Overlap and Overreach scores. We use TractoInferno and 105HCP datasets and validate generalization across dataset.
Generating Realistic Forehead-Creases for User Verification via Conditioned Piecewise Polynomial Curves
Jan 23, 2025We propose a trait-specific image generation method that models forehead creases geometrically using B-spline and B\'ezier curves. This approach ensures the realistic generation of both principal creases and non-prominent crease patterns, effectively constructing detailed and authentic forehead-crease images. These geometrically rendered images serve as visual prompts for a diffusion-based Edge-to-Image translation model, which generates corresponding mated samples. The resulting novel synthetic identities are then used to train a forehead-crease verification network. To enhance intra-subject diversity in the generated samples, we employ two strategies: (a) perturbing the control points of B-splines under defined constraints to maintain label consistency, and (b) applying image-level augmentations to the geometric visual prompts, such as dropout and elastic transformations, specifically tailored to crease patterns. By integrating the proposed synthetic dataset with real-world data, our method significantly improves the performance of forehead-crease verification systems under a cross-database verification protocol.
Impact of Iris Pigmentation on Performance Bias in Visible Iris Verification Systems: A Comparative Study
Nov 13, 2024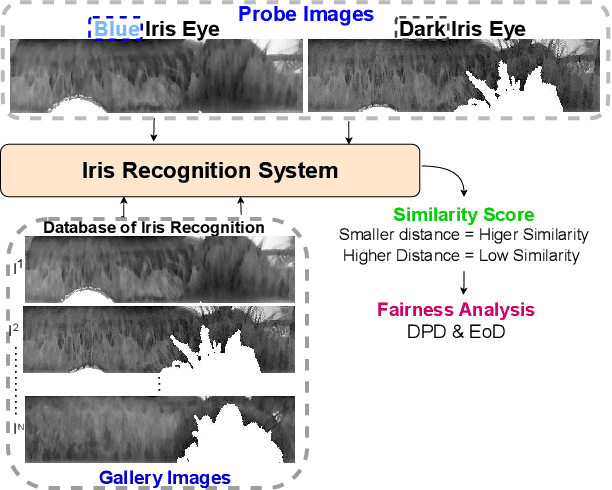



Iris recognition technology plays a critical role in biometric identification systems, but their performance can be affected by variations in iris pigmentation. In this work, we investigate the impact of iris pigmentation on the efficacy of biometric recognition systems, focusing on a comparative analysis of blue and dark irises. Data sets were collected using multiple devices, including P1, P2, and P3 smartphones [4], to assess the robustness of the systems in different capture environments [19]. Both traditional machine learning techniques and deep learning models were used, namely Open-Iris, ViT-b, and ResNet50, to evaluate performance metrics such as Equal Error Rate (EER) and True Match Rate (TMR). Our results indicate that iris recognition systems generally exhibit higher accuracy for blue irises compared to dark irises. Furthermore, we examined the generalization capabilities of these systems across different iris colors and devices, finding that while training on diverse datasets enhances recognition performance, the degree of improvement is contingent on the specific model and device used. Our analysis also identifies inherent biases in recognition performance related to iris color and cross-device variability. These findings underscore the need for more inclusive dataset collection and model refinement to reduce bias and promote equitable biometric recognition across varying iris pigmentation and device configurations.
TractoEmbed: Modular Multi-level Embedding framework for white matter tract segmentation
Nov 12, 2024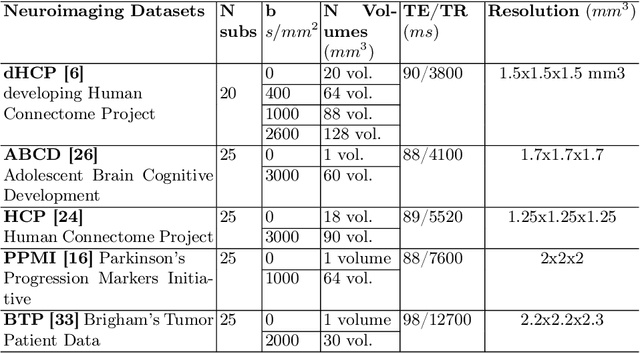
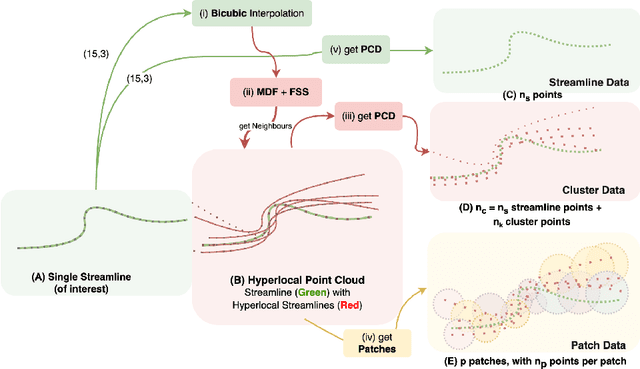
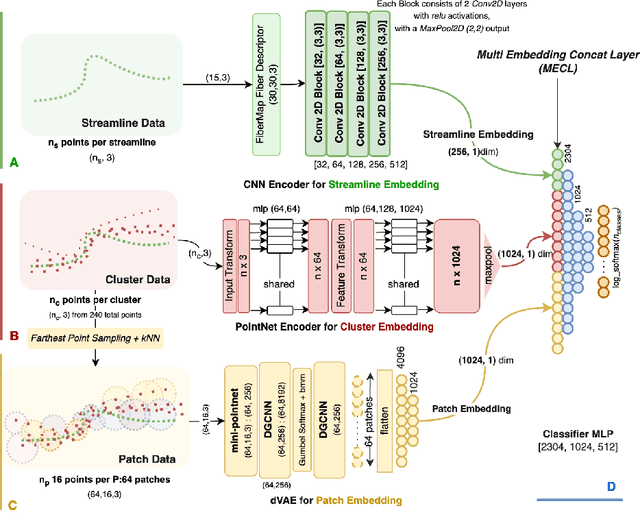

White matter tract segmentation is crucial for studying brain structural connectivity and neurosurgical planning. However, segmentation remains challenging due to issues like class imbalance between major and minor tracts, structural similarity, subject variability, symmetric streamlines between hemispheres etc. To address these challenges, we propose TractoEmbed, a modular multi-level embedding framework, that encodes localized representations through learning tasks in respective encoders. In this paper, TractoEmbed introduces a novel hierarchical streamline data representation that captures maximum spatial information at each level i.e. individual streamlines, clusters, and patches. Experiments show that TractoEmbed outperforms state-of-the-art methods in white matter tract segmentation across different datasets, and spanning various age groups. The modular framework directly allows the integration of additional embeddings in future works.
Tract-RLFormer: A Tract-Specific RL policy based Decoder-only Transformer Network
Nov 08, 2024Fiber tractography is a cornerstone of neuroimaging, enabling the detailed mapping of the brain's white matter pathways through diffusion MRI. This is crucial for understanding brain connectivity and function, making it a valuable tool in neurological applications. Despite its importance, tractography faces challenges due to its complexity and susceptibility to false positives, misrepresenting vital pathways. To address these issues, recent strategies have shifted towards deep learning, utilizing supervised learning, which depends on precise ground truth, or reinforcement learning, which operates without it. In this work, we propose Tract-RLFormer, a network utilizing both supervised and reinforcement learning, in a two-stage policy refinement process that markedly improves the accuracy and generalizability across various data-sets. By employing a tract-specific approach, our network directly delineates the tracts of interest, bypassing the traditional segmentation process. Through rigorous validation on datasets such as TractoInferno, HCP, and ISMRM-2015, our methodology demonstrates a leap forward in tractography, showcasing its ability to accurately map the brain's white matter tracts.
Synthetic Forehead-creases Biometric Generation for Reliable User Verification
Aug 28, 2024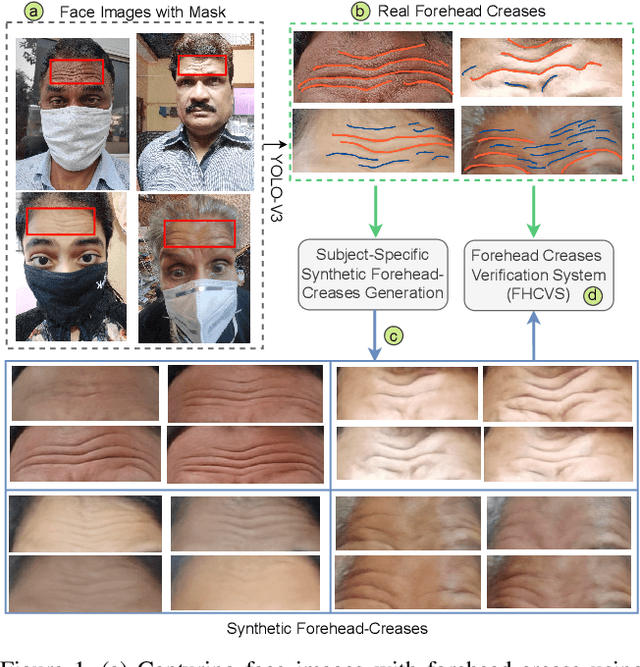



Recent studies have emphasized the potential of forehead-crease patterns as an alternative for face, iris, and periocular recognition, presenting contactless and convenient solutions, particularly in situations where faces are covered by surgical masks. However, collecting forehead data presents challenges, including cost and time constraints, as developing and optimizing forehead verification methods requires a substantial number of high-quality images. To tackle these challenges, the generation of synthetic biometric data has gained traction due to its ability to protect privacy while enabling effective training of deep learning-based biometric verification methods. In this paper, we present a new framework to synthesize forehead-crease image data while maintaining important features, such as uniqueness and realism. The proposed framework consists of two main modules: a Subject-Specific Generation Module (SSGM), based on an image-to-image Brownian Bridge Diffusion Model (BBDM), which learns a one-to-many mapping between image pairs to generate identity-aware synthetic forehead creases corresponding to real subjects, and a Subject-Agnostic Generation Module (SAGM), which samples new synthetic identities with assistance from the SSGM. We evaluate the diversity and realism of the generated forehead-crease images primarily using the Fr\'echet Inception Distance (FID) and the Structural Similarity Index Measure (SSIM). In addition, we assess the utility of synthetically generated forehead-crease images using a forehead-crease verification system (FHCVS). The results indicate an improvement in the verification accuracy of the FHCVS by utilizing synthetic data.
FH-SSTNet: Forehead Creases based User Verification using Spatio-Spatial Temporal Network
Mar 24, 2024
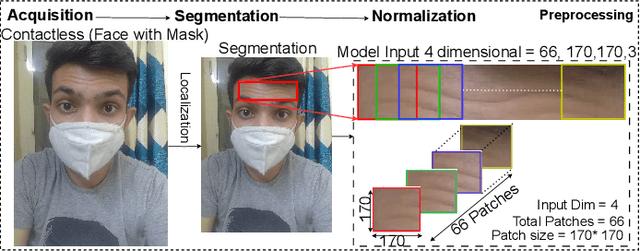
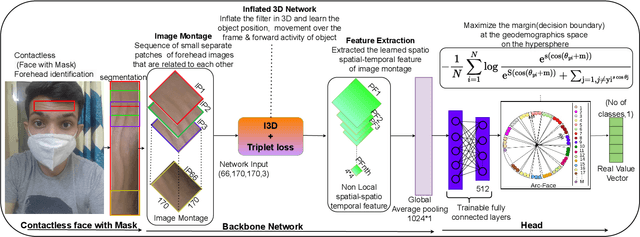
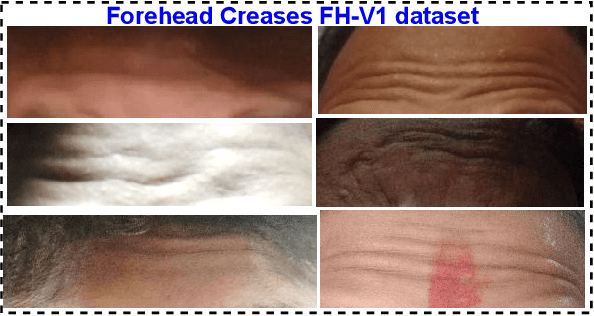
Biometric authentication, which utilizes contactless features, such as forehead patterns, has become increasingly important for identity verification and access management. The proposed method is based on learning a 3D spatio-spatial temporal convolution to create detailed pictures of forehead patterns. We introduce a new CNN model called the Forehead Spatio-Spatial Temporal Network (FH-SSTNet), which utilizes a 3D CNN architecture with triplet loss to capture distinguishing features. We enhance the model's discrimination capability using Arcloss in the network's head. Experimentation on the Forehead Creases version 1 (FH-V1) dataset, containing 247 unique subjects, demonstrates the superior performance of FH-SSTNet compared to existing methods and pre-trained CNNs like ResNet50, especially for forehead-based user verification. The results demonstrate the superior performance of FH-SSTNet for forehead-based user verification, confirming its effectiveness in identity authentication.