 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVRA: Improving Visual-Token Relations for Robot Action Policy with Training-Free Hint-Based Guidance
Jan 22, 2026Many Vision-Language-Action (VLA) models flatten image patches into a 1D token sequence, weakening the 2D spatial cues needed for precise manipulation. We introduce IVRA, a lightweight, training-free method that improves spatial understanding by exploiting affinity hints already available in the model's built-in vision encoder, without requiring any external encoder or retraining. IVRA selectively injects these affinity signals into a language-model layer in which instance-level features reside. This inference-time intervention realigns visual-token interactions and better preserves geometric structure while keeping all model parameters fixed. We demonstrate the generality of IVRA by applying it to diverse VLA architectures (LLaRA, OpenVLA, and FLOWER) across simulated benchmarks spanning both 2D and 3D manipulation (VIMA and LIBERO) and on various real-robot tasks. On 2D VIMA, IVRA improves average success by +4.2% over the baseline LLaRA in a low-data regime. On 3D LIBERO, it yields consistent gains over the OpenVLA and FLOWER baselines, including improvements when baseline accuracy is near saturation (96.3% to 97.1%). All code and models will be released publicly. Visualizations are available at: jongwoopark7978.github.io/IVRA
Pixel Motion as Universal Representation for Robot Control
May 12, 2025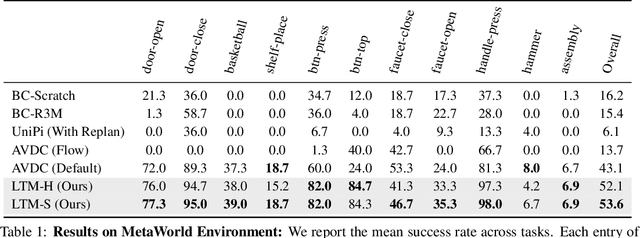
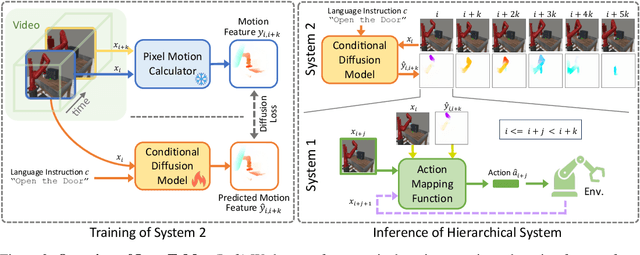
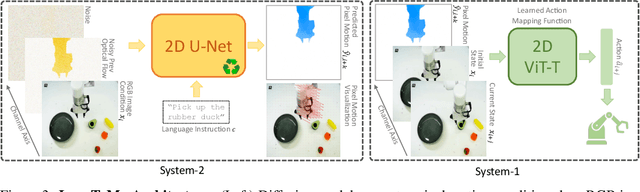
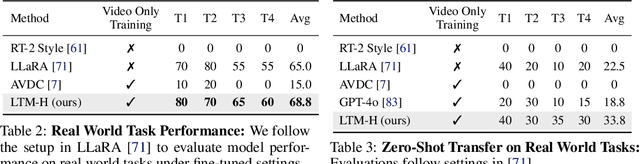
We present LangToMo, a vision-language-action framework structured as a dual-system architecture that uses pixel motion forecasts as intermediate representations. Our high-level System 2, an image diffusion model, generates text-conditioned pixel motion sequences from a single frame to guide robot control. Pixel motion-a universal, interpretable, and motion-centric representation-can be extracted from videos in a self-supervised manner, enabling diffusion model training on web-scale video-caption data. Treating generated pixel motion as learned universal representations, our low level System 1 module translates these into robot actions via motion-to-action mapping functions, which can be either hand-crafted or learned with minimal supervision. System 2 operates as a high-level policy applied at sparse temporal intervals, while System 1 acts as a low-level policy at dense temporal intervals. This hierarchical decoupling enables flexible, scalable, and generalizable robot control under both unsupervised and supervised settings, bridging the gap between language, motion, and action. Checkout https://kahnchana.github.io/LangToMo for visualizations.
ColFigPhotoAttnNet: Reliable Finger Photo Presentation Attack Detection Leveraging Window-Attention on Color Spaces
Mar 07, 2025Finger photo Presentation Attack Detection (PAD) can significantly strengthen smartphone device security. However, these algorithms are trained to detect certain types of attacks. Furthermore, they are designed to operate on images acquired by specific capture devices, leading to poor generalization and a lack of robustness in handling the evolving nature of mobile hardware. The proposed investigation is the first to systematically analyze the performance degradation of existing deep learning PAD systems, convolutional and transformers, in cross-capture device settings. In this paper, we introduce the ColFigPhotoAttnNet architecture designed based on window attention on color channels, followed by the nested residual network as the predictor to achieve a reliable PAD. Extensive experiments using various capture devices, including iPhone13 Pro, GooglePixel 3, Nokia C5, and OnePlusOne, were carried out to evaluate the performance of proposed and existing methods on three publicly available databases. The findings underscore the effectiveness of our approach.
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Jun 28, 2024
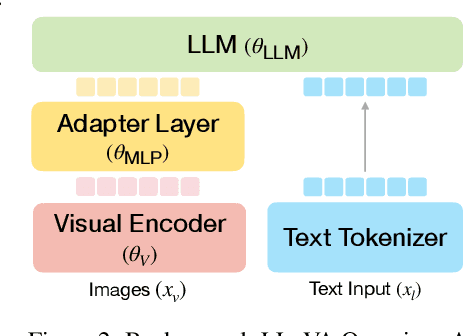
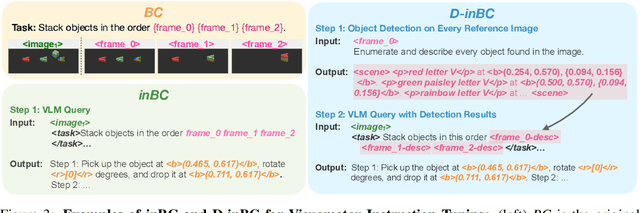

Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jun 17, 2024



Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
Language Repository for Long Video Understanding
Mar 21, 2024



Language has become a prominent modality in computer vision with the rise of multi-modal LLMs. Despite supporting long context-lengths, their effectiveness in handling long-term information gradually declines with input length. This becomes critical, especially in applications such as long-form video understanding. In this paper, we introduce a Language Repository (LangRepo) for LLMs, that maintains concise and structured information as an interpretable (i.e., all-textual) representation. Our repository is updated iteratively based on multi-scale video chunks. We introduce write and read operations that focus on pruning redundancies in text, and extracting information at various temporal scales. The proposed framework is evaluated on zero-shot visual question-answering benchmarks including EgoSchema, NExT-QA, IntentQA and NExT-GQA, showing state-of-the-art performance at its scale. Our code is available at https://github.com/kkahatapitiya/LangRepo.
3M3D: Multi-view, Multi-path, Multi-representation for 3D Object Detection
Feb 16, 2023



3D visual perception tasks based on multi-camera images are essential for autonomous driving systems. Latest work in this field performs 3D object detection by leveraging multi-view images as an input and iteratively enhancing object queries (object proposals) by cross-attending multi-view features. However, individual backbone features are not updated with multi-view features and it stays as a mere collection of the output of the single-image backbone network. Therefore we propose 3M3D: A Multi-view, Multi-path, Multi-representation for 3D Object Detection where we update both multi-view features and query features to enhance the representation of the scene in both fine panoramic view and coarse global view. Firstly, we update multi-view features by multi-view axis self-attention. It will incorporate panoramic information in the multi-view features and enhance understanding of the global scene. Secondly, we update multi-view features by self-attention of the ROI (Region of Interest) windows which encodes local finer details in the features. It will help exchange the information not only along the multi-view axis but also along the other spatial dimension. Lastly, we leverage the fact of multi-representation of queries in different domains to further boost the performance. Here we use sparse floating queries along with dense BEV (Bird's Eye View) queries, which are later post-processed to filter duplicate detections. Moreover, we show performance improvements on nuScenes benchmark dataset on top of our baselines.
Grafting Vision Transformers
Oct 28, 2022



Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.