 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVRA: Improving Visual-Token Relations for Robot Action Policy with Training-Free Hint-Based Guidance
Jan 22, 2026Many Vision-Language-Action (VLA) models flatten image patches into a 1D token sequence, weakening the 2D spatial cues needed for precise manipulation. We introduce IVRA, a lightweight, training-free method that improves spatial understanding by exploiting affinity hints already available in the model's built-in vision encoder, without requiring any external encoder or retraining. IVRA selectively injects these affinity signals into a language-model layer in which instance-level features reside. This inference-time intervention realigns visual-token interactions and better preserves geometric structure while keeping all model parameters fixed. We demonstrate the generality of IVRA by applying it to diverse VLA architectures (LLaRA, OpenVLA, and FLOWER) across simulated benchmarks spanning both 2D and 3D manipulation (VIMA and LIBERO) and on various real-robot tasks. On 2D VIMA, IVRA improves average success by +4.2% over the baseline LLaRA in a low-data regime. On 3D LIBERO, it yields consistent gains over the OpenVLA and FLOWER baselines, including improvements when baseline accuracy is near saturation (96.3% to 97.1%). All code and models will be released publicly. Visualizations are available at: jongwoopark7978.github.io/IVRA
Future Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
Pixel Motion as Universal Representation for Robot Control
May 12, 2025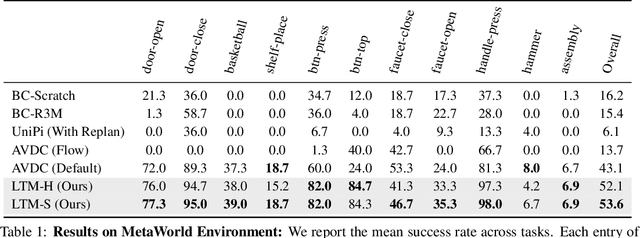
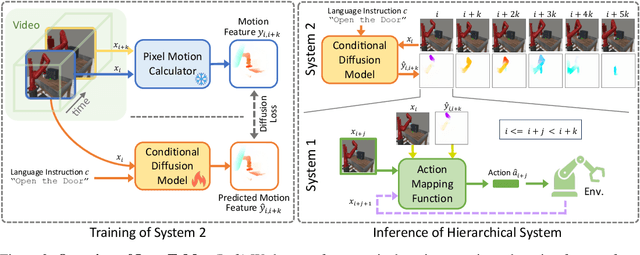
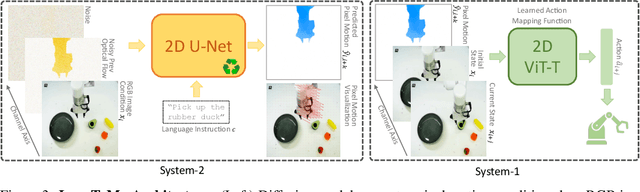
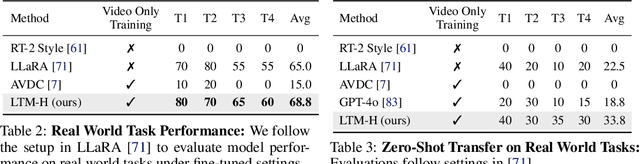
We present LangToMo, a vision-language-action framework structured as a dual-system architecture that uses pixel motion forecasts as intermediate representations. Our high-level System 2, an image diffusion model, generates text-conditioned pixel motion sequences from a single frame to guide robot control. Pixel motion-a universal, interpretable, and motion-centric representation-can be extracted from videos in a self-supervised manner, enabling diffusion model training on web-scale video-caption data. Treating generated pixel motion as learned universal representations, our low level System 1 module translates these into robot actions via motion-to-action mapping functions, which can be either hand-crafted or learned with minimal supervision. System 2 operates as a high-level policy applied at sparse temporal intervals, while System 1 acts as a low-level policy at dense temporal intervals. This hierarchical decoupling enables flexible, scalable, and generalizable robot control under both unsupervised and supervised settings, bridging the gap between language, motion, and action. Checkout https://kahnchana.github.io/LangToMo for visualizations.
LatentCRF: Continuous CRF for Efficient Latent Diffusion
Dec 24, 2024



Latent Diffusion Models (LDMs) produce high-quality, photo-realistic images, however, the latency incurred by multiple costly inference iterations can restrict their applicability. We introduce LatentCRF, a continuous Conditional Random Field (CRF) model, implemented as a neural network layer, that models the spatial and semantic relationships among the latent vectors in the LDM. By replacing some of the computationally-intensive LDM inference iterations with our lightweight LatentCRF, we achieve a superior balance between quality, speed and diversity. We increase inference efficiency by 33% with no loss in image quality or diversity compared to the full LDM. LatentCRF is an easy add-on, which does not require modifying the LDM.
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Aug 16, 2024



This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.
Hybrid Random Features
Oct 13, 2021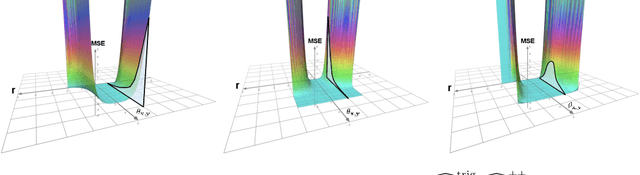
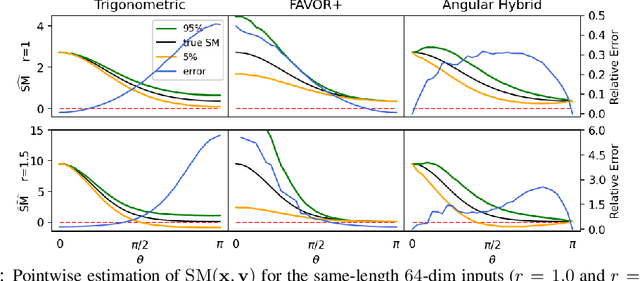
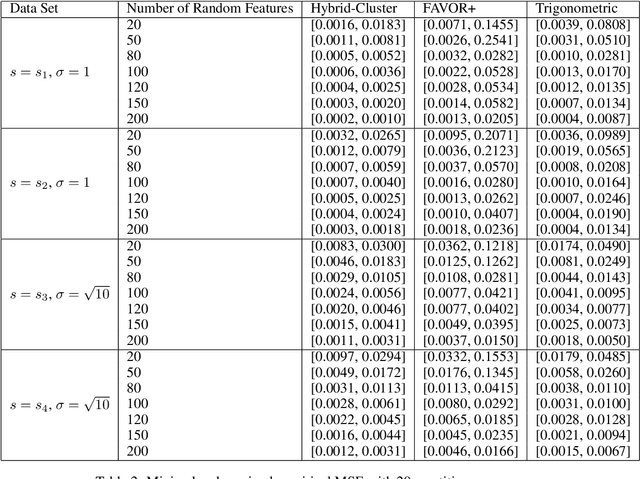
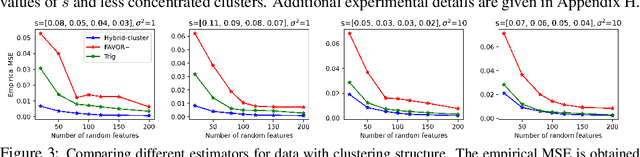
We propose a new class of random feature methods for linearizing softmax and Gaussian kernels called hybrid random features (HRFs) that automatically adapt the quality of kernel estimation to provide most accurate approximation in the defined regions of interest. Special instantiations of HRFs lead to well-known methods such as trigonometric (Rahimi and Recht, 2007) or (recently introduced in the context of linear-attention Transformers) positive random features (Choromanski et al., 2021). By generalizing Bochner's Theorem for softmax/Gaussian kernels and leveraging random features for compositional kernels, the HRF-mechanism provides strong theoretical guarantees - unbiased approximation and strictly smaller worst-case relative errors than its counterparts. We conduct exhaustive empirical evaluation of HRF ranging from pointwise kernel estimation experiments, through tests on data admitting clustering structure to benchmarking implicit-attention Transformers (also for downstream Robotics applications), demonstrating its quality in a wide spectrum of machine learning problems.
Joint Person Segmentation and Identification in Synchronized First- and Third-person Videos
Jul 25, 2018
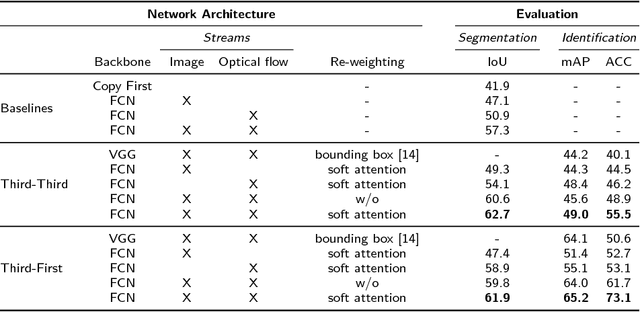
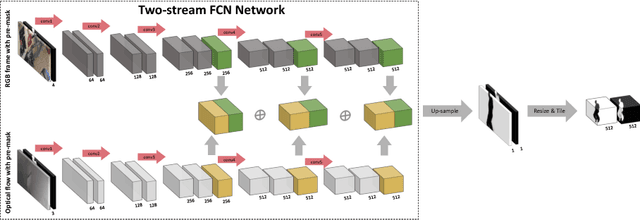
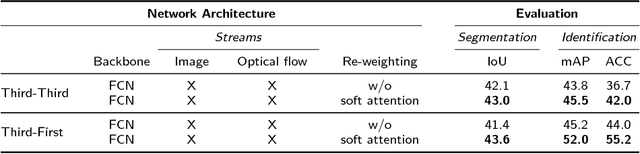
In a world of pervasive cameras, public spaces are often captured from multiple perspectives by cameras of different types, both fixed and mobile. An important problem is to organize these heterogeneous collections of videos by finding connections between them, such as identifying correspondences between the people appearing in the videos and the people holding or wearing the cameras. In this paper, we wish to solve two specific problems: (1) given two or more synchronized third-person videos of a scene, produce a pixel-level segmentation of each visible person and identify corresponding people across different views (i.e., determine who in camera A corresponds with whom in camera B), and (2) given one or more synchronized third-person videos as well as a first-person video taken by a mobile or wearable camera, segment and identify the camera wearer in the third-person videos. Unlike previous work which requires ground truth bounding boxes to estimate the correspondences, we perform person segmentation and identification jointly. We find that solving these two problems simultaneously is mutually beneficial, because better fine-grained segmentation allows us to better perform matching across views, and information from multiple views helps us perform more accurate segmentation. We evaluate our approach on two challenging datasets of interacting people captured from multiple wearable cameras, and show that our proposed method performs significantly better than the state-of-the-art on both person segmentation and identification.