 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVRA: Improving Visual-Token Relations for Robot Action Policy with Training-Free Hint-Based Guidance
Jan 22, 2026Many Vision-Language-Action (VLA) models flatten image patches into a 1D token sequence, weakening the 2D spatial cues needed for precise manipulation. We introduce IVRA, a lightweight, training-free method that improves spatial understanding by exploiting affinity hints already available in the model's built-in vision encoder, without requiring any external encoder or retraining. IVRA selectively injects these affinity signals into a language-model layer in which instance-level features reside. This inference-time intervention realigns visual-token interactions and better preserves geometric structure while keeping all model parameters fixed. We demonstrate the generality of IVRA by applying it to diverse VLA architectures (LLaRA, OpenVLA, and FLOWER) across simulated benchmarks spanning both 2D and 3D manipulation (VIMA and LIBERO) and on various real-robot tasks. On 2D VIMA, IVRA improves average success by +4.2% over the baseline LLaRA in a low-data regime. On 3D LIBERO, it yields consistent gains over the OpenVLA and FLOWER baselines, including improvements when baseline accuracy is near saturation (96.3% to 97.1%). All code and models will be released publicly. Visualizations are available at: jongwoopark7978.github.io/IVRA
Pixel Motion as Universal Representation for Robot Control
May 12, 2025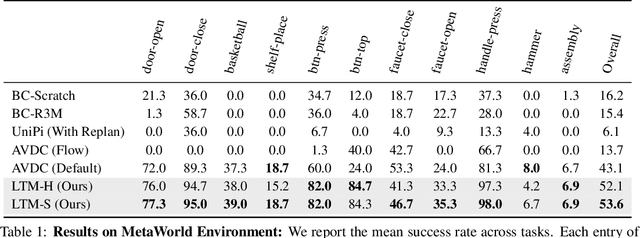
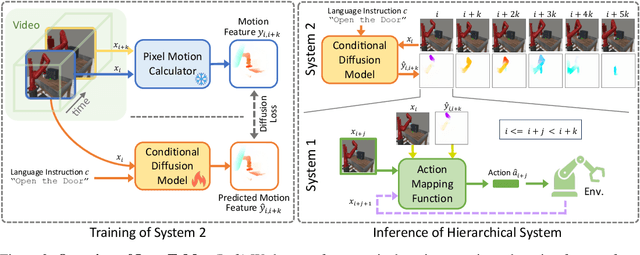
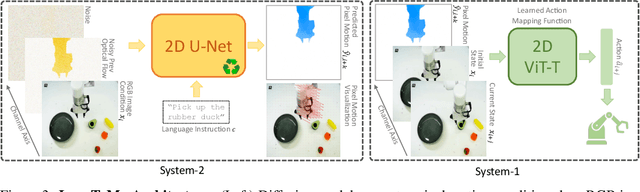
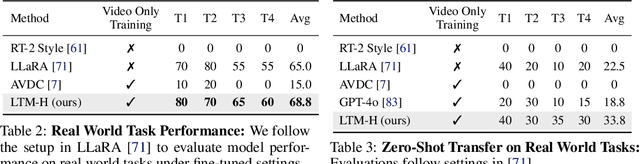
We present LangToMo, a vision-language-action framework structured as a dual-system architecture that uses pixel motion forecasts as intermediate representations. Our high-level System 2, an image diffusion model, generates text-conditioned pixel motion sequences from a single frame to guide robot control. Pixel motion-a universal, interpretable, and motion-centric representation-can be extracted from videos in a self-supervised manner, enabling diffusion model training on web-scale video-caption data. Treating generated pixel motion as learned universal representations, our low level System 1 module translates these into robot actions via motion-to-action mapping functions, which can be either hand-crafted or learned with minimal supervision. System 2 operates as a high-level policy applied at sparse temporal intervals, while System 1 acts as a low-level policy at dense temporal intervals. This hierarchical decoupling enables flexible, scalable, and generalizable robot control under both unsupervised and supervised settings, bridging the gap between language, motion, and action. Checkout https://kahnchana.github.io/LangToMo for visualizations.
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Jun 28, 2024

Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
StandardSim: A Synthetic Dataset For Retail Environments
Feb 04, 2022



Autonomous checkout systems rely on visual and sensory inputs to carry out fine-grained scene understanding in retail environments. Retail environments present unique challenges compared to typical indoor scenes owing to the vast number of densely packed, unique yet similar objects. The problem becomes even more difficult when only RGB input is available, especially for data-hungry tasks such as instance segmentation. To address the lack of datasets for retail, we present StandardSim, a large-scale photorealistic synthetic dataset featuring annotations for semantic segmentation, instance segmentation, depth estimation, and object detection. Our dataset provides multiple views per scene, enabling multi-view representation learning. Further, we introduce a novel task central to autonomous checkout called change detection, requiring pixel-level classification of takes, puts and shifts in objects over time. We benchmark widely-used models for segmentation and depth estimation on our dataset, show that our test set constitutes a difficult benchmark compared to current smaller-scale datasets and that our training set provides models with crucial information for autonomous checkout tasks.
Complex Relations in a Deep Structured Prediction Model for Fine Image Segmentation
May 24, 2018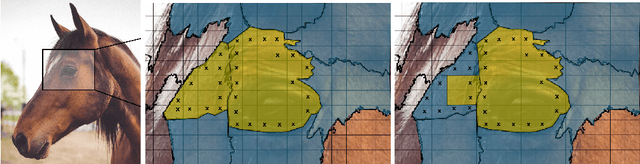
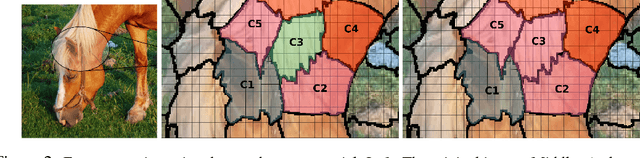
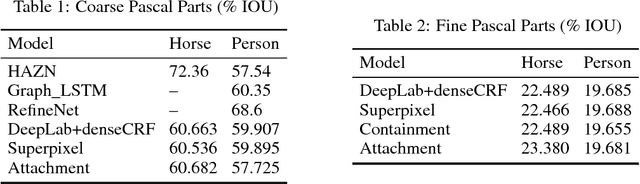

Many deep learning architectures for semantic segmentation involve a Fully Convolutional Neural Network (FCN) followed by a Conditional Random Field (CRF) to carry out inference over an image. These models typically involve unary potentials based on local appearance features computed by FCNs, and binary potentials based on the displacement between pixels. We show that while current methods succeed in segmenting whole objects, they perform poorly in situations involving a large number of object parts. We therefore suggest incorporating into the inference algorithm additional higher-order potentials inspired by the way humans identify and localize parts. We incorporate two relations that were shown to be useful to human object identification - containment and attachment - into the energy term of the CRF and evaluate their performance on the Pascal VOC Parts dataset. Our experimental results show that the segmentation of fine parts is positively affected by the addition of these two relations, and that the segmentation of fine parts can be further influenced by complex structural features.