 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContamination Detection for VLMs using Multi-Modal Semantic Perturbation
Nov 05, 2025Recent advances in Vision-Language Models (VLMs) have achieved state-of-the-art performance on numerous benchmark tasks. However, the use of internet-scale, often proprietary, pretraining corpora raises a critical concern for both practitioners and users: inflated performance due to test-set leakage. While prior works have proposed mitigation strategies such as decontamination of pretraining data and benchmark redesign for LLMs, the complementary direction of developing detection methods for contaminated VLMs remains underexplored. To address this gap, we deliberately contaminate open-source VLMs on popular benchmarks and show that existing detection approaches either fail outright or exhibit inconsistent behavior. We then propose a novel simple yet effective detection method based on multi-modal semantic perturbation, demonstrating that contaminated models fail to generalize under controlled perturbations. Finally, we validate our approach across multiple realistic contamination strategies, confirming its robustness and effectiveness. The code and perturbed dataset will be released publicly.
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Jul 27, 2025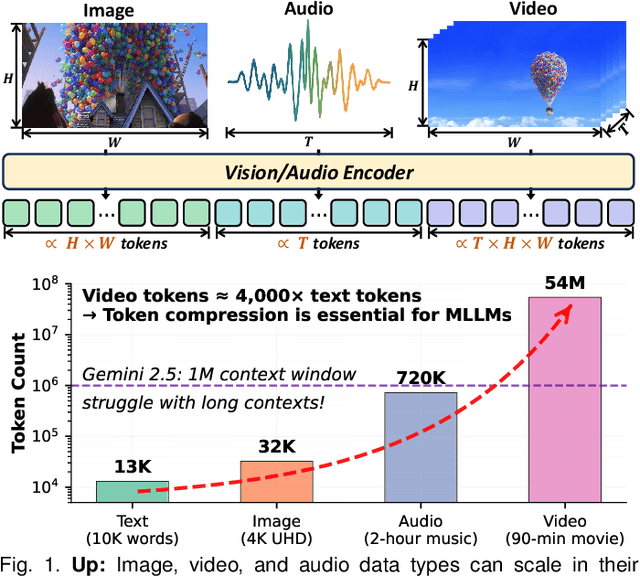
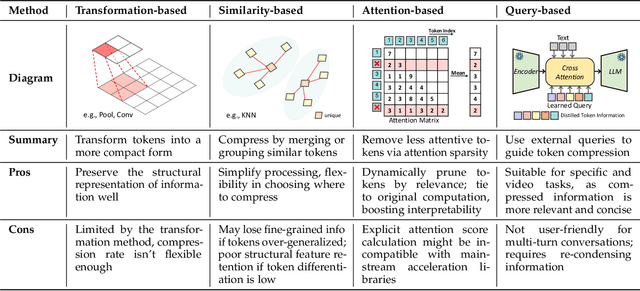
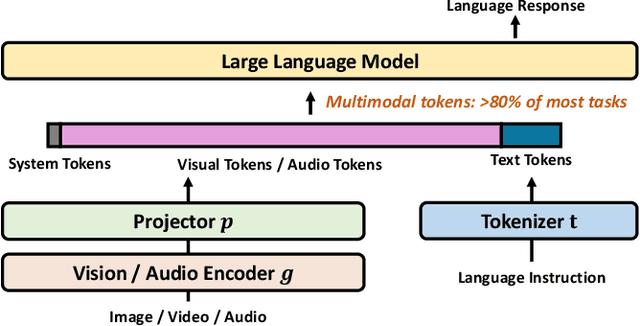
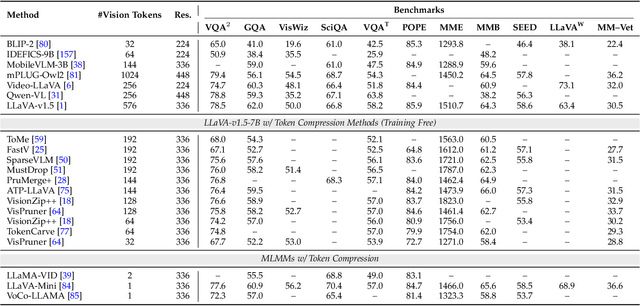
Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
Decomposing Complex Visual Comprehension into Atomic Visual Skills for Vision Language Models
May 26, 2025Recent Vision-Language Models (VLMs) have demonstrated impressive multimodal comprehension and reasoning capabilities, yet they often struggle with trivially simple visual tasks. In this work, we focus on the domain of basic 2D Euclidean geometry and systematically categorize the fundamental, indivisible visual perception skills, which we refer to as atomic visual skills. We then introduce the Atomic Visual Skills Dataset (AVSD) for evaluating VLMs on the atomic visual skills. Using AVSD, we benchmark state-of-the-art VLMs and find that they struggle with these tasks, despite being trivial for adult humans. Our findings highlight the need for purpose-built datasets to train and evaluate VLMs on atomic, rather than composite, visual perception tasks.
Magma: A Foundation Model for Multimodal AI Agents
Feb 18, 2025We present Magma, a foundation model that serves multimodal AI agentic tasks in both the digital and physical worlds. Magma is a significant extension of vision-language (VL) models in that it not only retains the VL understanding ability (verbal intelligence) of the latter, but is also equipped with the ability to plan and act in the visual-spatial world (spatial-temporal intelligence) and complete agentic tasks ranging from UI navigation to robot manipulation. To endow the agentic capabilities, Magma is pretrained on large amounts of heterogeneous datasets spanning from images, videos to robotics data, where the actionable visual objects (e.g., clickable buttons in GUI) in images are labeled by Set-of-Mark (SoM) for action grounding, and the object movements (e.g., the trace of human hands or robotic arms) in videos are labeled by Trace-of-Mark (ToM) for action planning. Extensive experiments show that SoM and ToM reach great synergy and facilitate the acquisition of spatial-temporal intelligence for our Magma model, which is fundamental to a wide range of tasks as shown in Fig.1. In particular, Magma creates new state-of-the-art results on UI navigation and robotic manipulation tasks, outperforming previous models that are specifically tailored to these tasks. On image and video-related multimodal tasks, Magma also compares favorably to popular large multimodal models that are trained on much larger datasets. We make our model and code public for reproducibility at https://microsoft.github.io/Magma.
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Oct 15, 2024



Understanding fine-grained temporal dynamics is crucial for multimodal video comprehension and generation. Due to the lack of fine-grained temporal annotations, existing video benchmarks mostly resemble static image benchmarks and are incompetent at evaluating models for temporal understanding. In this paper, we introduce TemporalBench, a new benchmark dedicated to evaluating fine-grained temporal understanding in videos. TemporalBench consists of ~10K video question-answer pairs, derived from ~2K high-quality human annotations detailing the temporal dynamics in video clips. As a result, our benchmark provides a unique testbed for evaluating various temporal understanding and reasoning abilities such as action frequency, motion magnitude, event order, etc. Moreover, it enables evaluations on various tasks like both video question answering and captioning, both short and long video understanding, as well as different models such as multimodal video embedding models and text generation models. Results show that state-of-the-art models like GPT-4o achieve only 38.5% question answering accuracy on TemporalBench, demonstrating a significant gap (~30%) between humans and AI in temporal understanding. Furthermore, we notice a critical pitfall for multi-choice QA where LLMs can detect the subtle changes in negative captions and find a centralized description as a cue for its prediction, where we propose Multiple Binary Accuracy (MBA) to correct such bias. We hope that TemporalBench can foster research on improving models' temporal reasoning capabilities. Both dataset and evaluation code will be made available.
Vinoground: Scrutinizing LMMs over Dense Temporal Reasoning with Short Videos
Oct 03, 2024



There has been growing sentiment recently that modern large multimodal models (LMMs) have addressed most of the key challenges related to short video comprehension. As a result, both academia and industry are gradually shifting their attention towards the more complex challenges posed by understanding long-form videos. However, is this really the case? Our studies indicate that LMMs still lack many fundamental reasoning capabilities even when dealing with short videos. We introduce Vinoground, a temporal counterfactual LMM evaluation benchmark encompassing 1000 short and natural video-caption pairs. We demonstrate that existing LMMs severely struggle to distinguish temporal differences between different actions and object transformations. For example, the best model GPT-4o only obtains ~50% on our text and video scores, showing a large gap compared to the human baseline of ~90%. All open-source multimodal models and CLIP-based models perform much worse, producing mostly random chance performance. Through this work, we shed light onto the fact that temporal reasoning in short videos is a problem yet to be fully solved. The dataset and evaluation code are available at https://vinoground.github.io.
Removing Distributional Discrepancies in Captions Improves Image-Text Alignment
Oct 01, 2024



In this paper, we introduce a model designed to improve the prediction of image-text alignment, targeting the challenge of compositional understanding in current visual-language models. Our approach focuses on generating high-quality training datasets for the alignment task by producing mixed-type negative captions derived from positive ones. Critically, we address the distribution imbalance between positive and negative captions to ensure that the alignment model does not depend solely on textual information but also considers the associated images for predicting alignment accurately. By creating this enhanced training data, we fine-tune an existing leading visual-language model to boost its capability in understanding alignment. Our model significantly outperforms current top-performing methods across various datasets. We also demonstrate the applicability of our model by ranking the images generated by text-to-image models based on text alignment. Project page: \url{https://yuheng-li.github.io/LLaVA-score/}
Cross-Modal Self-Supervised Learning with Effective Contrastive Units for LiDAR Point Clouds
Sep 10, 2024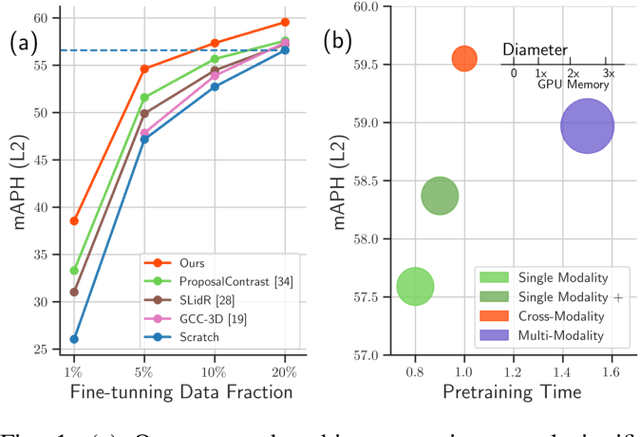
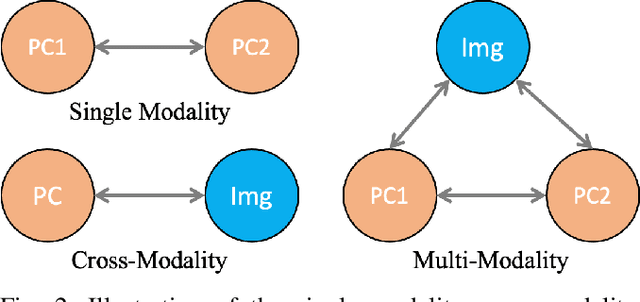
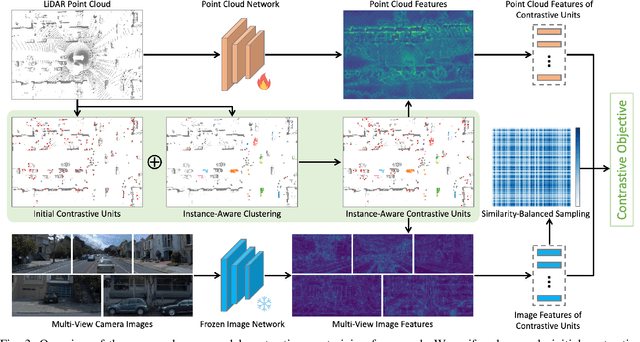

3D perception in LiDAR point clouds is crucial for a self-driving vehicle to properly act in 3D environment. However, manually labeling point clouds is hard and costly. There has been a growing interest in self-supervised pre-training of 3D perception models. Following the success of contrastive learning in images, current methods mostly conduct contrastive pre-training on point clouds only. Yet an autonomous driving vehicle is typically supplied with multiple sensors including cameras and LiDAR. In this context, we systematically study single modality, cross-modality, and multi-modality for contrastive learning of point clouds, and show that cross-modality wins over other alternatives. In addition, considering the huge difference between the training sources in 2D images and 3D point clouds, it remains unclear how to design more effective contrastive units for LiDAR. We therefore propose the instance-aware and similarity-balanced contrastive units that are tailored for self-driving point clouds. Extensive experiments reveal that our approach achieves remarkable performance gains over various point cloud models across the downstream perception tasks of LiDAR based 3D object detection and 3D semantic segmentation on the four popular benchmarks including Waymo Open Dataset, nuScenes, SemanticKITTI and ONCE.
VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation
Jul 15, 2024In the realm of vision models, the primary mode of representation is using pixels to rasterize the visual world. Yet this is not always the best or unique way to represent visual content, especially for designers and artists who depict the world using geometry primitives such as polygons. Vector graphics (VG), on the other hand, offer a textual representation of visual content, which can be more concise and powerful for content like cartoons or sketches. Recent studies have shown promising results on processing vector graphics with capable Large Language Models (LLMs). However, such works focus solely on qualitative results, understanding, or a specific type of vector graphics. We propose VGBench, a comprehensive benchmark for LLMs on handling vector graphics through diverse aspects, including (a) both visual understanding and generation, (b) evaluation of various vector graphics formats, (c) diverse question types, (d) wide range of prompting techniques, (e) under multiple LLMs. Evaluating on our collected 4279 understanding and 5845 generation samples, we find that LLMs show strong capability on both aspects while exhibiting less desirable performance on low-level formats (SVG). Both data and evaluation pipeline will be open-sourced at https://vgbench.github.io.
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Jun 28, 2024
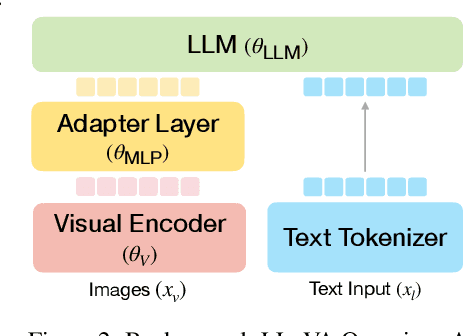
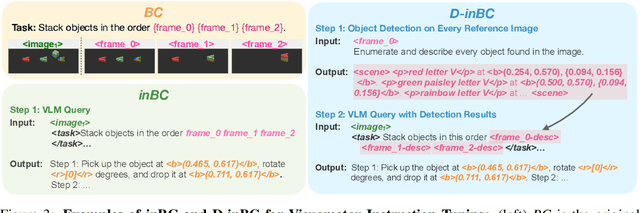

Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.