 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
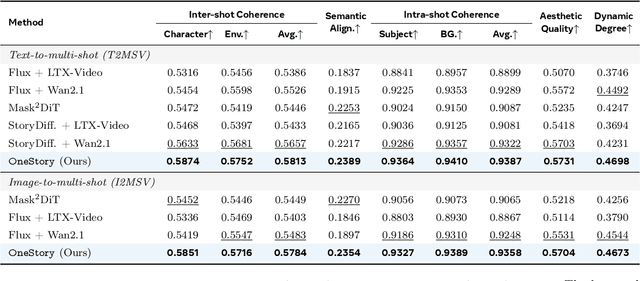
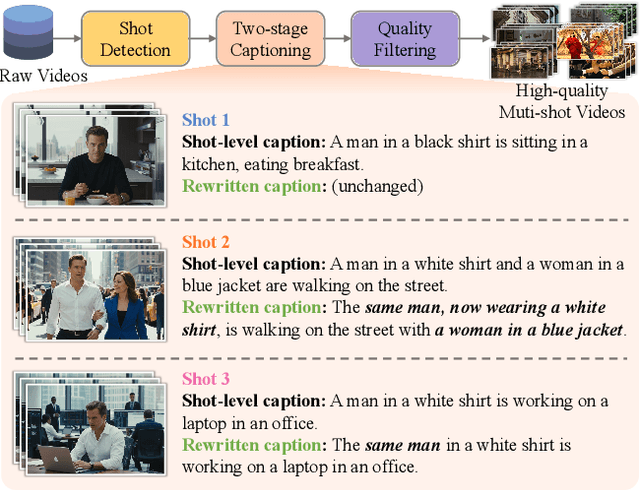

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Adaptive Caching for Faster Video Generation with Diffusion Transformers
Nov 04, 2024



Generating temporally-consistent high-fidelity videos can be computationally expensive, especially over longer temporal spans. More-recent Diffusion Transformers (DiTs) -- despite making significant headway in this context -- have only heightened such challenges as they rely on larger models and heavier attention mechanisms, resulting in slower inference speeds. In this paper, we introduce a training-free method to accelerate video DiTs, termed Adaptive Caching (AdaCache), which is motivated by the fact that "not all videos are created equal": meaning, some videos require fewer denoising steps to attain a reasonable quality than others. Building on this, we not only cache computations through the diffusion process, but also devise a caching schedule tailored to each video generation, maximizing the quality-latency trade-off. We further introduce a Motion Regularization (MoReg) scheme to utilize video information within AdaCache, essentially controlling the compute allocation based on motion content. Altogether, our plug-and-play contributions grant significant inference speedups (e.g. up to 4.7x on Open-Sora 720p - 2s video generation) without sacrificing the generation quality, across multiple video DiT baselines.
MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
Oct 26, 2024



We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini's MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Jun 28, 2024
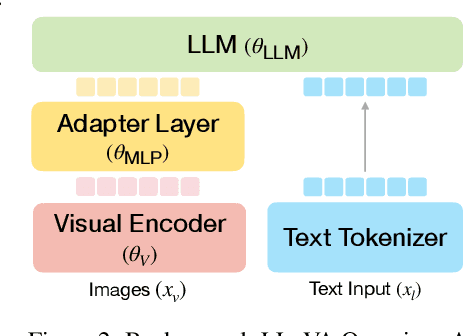
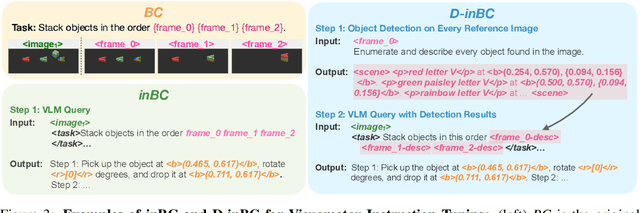

Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jun 17, 2024



Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
Understanding Long Videos in One Multimodal Language Model Pass
Mar 25, 2024



Large Language Models (LLMs), known to contain a strong awareness of world knowledge, have allowed recent approaches to achieve excellent performance on Long-Video Understanding benchmarks, but at high inference costs. In this work, we first propose Likelihood Selection, a simple technique that unlocks faster inference in autoregressive LLMs for multiple-choice tasks common in long-video benchmarks. In addition to faster inference, we discover the resulting models to yield surprisingly good accuracy on long-video tasks, even with no video specific information. Building on this, we inject video-specific object-centric information extracted from off-the-shelf pre-trained models and utilize natural language as a medium for information fusion. Our resulting Multimodal Video Understanding (MVU) framework demonstrates state-of-the-art performance across long-video and fine-grained action recognition benchmarks. Code available at: https://github.com/kahnchana/mvu
Language Repository for Long Video Understanding
Mar 21, 2024



Language has become a prominent modality in computer vision with the rise of multi-modal LLMs. Despite supporting long context-lengths, their effectiveness in handling long-term information gradually declines with input length. This becomes critical, especially in applications such as long-form video understanding. In this paper, we introduce a Language Repository (LangRepo) for LLMs, that maintains concise and structured information as an interpretable (i.e., all-textual) representation. Our repository is updated iteratively based on multi-scale video chunks. We introduce write and read operations that focus on pruning redundancies in text, and extracting information at various temporal scales. The proposed framework is evaluated on zero-shot visual question-answering benchmarks including EgoSchema, NExT-QA, IntentQA and NExT-GQA, showing state-of-the-art performance at its scale. Our code is available at https://github.com/kkahatapitiya/LangRepo.
Object-Centric Diffusion for Efficient Video Editing
Jan 11, 2024



Diffusion-based video editing have reached impressive quality and can transform either the global style, local structure, and attributes of given video inputs, following textual edit prompts. However, such solutions typically incur heavy memory and computational costs to generate temporally-coherent frames, either in the form of diffusion inversion and/or cross-frame attention. In this paper, we conduct an analysis of such inefficiencies, and suggest simple yet effective modifications that allow significant speed-ups whilst maintaining quality. Moreover, we introduce Object-Centric Diffusion, coined as OCD, to further reduce latency by allocating computations more towards foreground edited regions that are arguably more important for perceptual quality. We achieve this by two novel proposals: i) Object-Centric Sampling, decoupling the diffusion steps spent on salient regions or background, allocating most of the model capacity to the former, and ii) Object-Centric 3D Token Merging, which reduces cost of cross-frame attention by fusing redundant tokens in unimportant background regions. Both techniques are readily applicable to a given video editing model \textit{without} retraining, and can drastically reduce its memory and computational cost. We evaluate our proposals on inversion-based and control-signal-based editing pipelines, and show a latency reduction up to 10x for a comparable synthesis quality.
VicTR: Video-conditioned Text Representations for Activity Recognition
Apr 05, 2023Vision-Language models have shown strong performance in the image-domain -- even in zero-shot settings, thanks to the availability of large amount of pretraining data (i.e., paired image-text examples). However for videos, such paired data is not as abundant. Thus, video-text models are usually designed by adapting pretrained image-text models to video-domain, instead of training from scratch. All such recipes rely on augmenting visual embeddings with temporal information (i.e., image -> video), often keeping text embeddings unchanged or even being discarded. In this paper, we argue that such adapted video-text models can benefit more by augmenting text rather than visual information. We propose VicTR, which jointly-optimizes text and video tokens, generating 'Video-conditioned Text' embeddings. Our method can further make use of freely-available semantic information, in the form of visually-grounded auxiliary text (e.g., object or scene information). We conduct experiments on multiple benchmarks including supervised (Kinetics-400, Charades), zero-shot and few-shot (HMDB-51, UCF-101) settings, showing competitive performance on activity recognition based on video-text models.
Token Turing Machines
Nov 16, 2022



We propose Token Turing Machines (TTM), a sequential, autoregressive Transformer model with memory for real-world sequential visual understanding. Our model is inspired by the seminal Neural Turing Machine, and has an external memory consisting of a set of tokens which summarise the previous history (i.e., frames). This memory is efficiently addressed, read and written using a Transformer as the processing unit/controller at each step. The model's memory module ensures that a new observation will only be processed with the contents of the memory (and not the entire history), meaning that it can efficiently process long sequences with a bounded computational cost at each step. We show that TTM outperforms other alternatives, such as other Transformer models designed for long sequences and recurrent neural networks, on two real-world sequential visual understanding tasks: online temporal activity detection from videos and vision-based robot action policy learning.