 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyTask: an Automated Task and Data Generation Framework for Advancing Sim-to-Real Policy Learning
Dec 19, 2025Generalist robot learning remains constrained by data: large-scale, diverse, and high-quality interaction data are expensive to collect in the real world. While simulation has become a promising way for scaling up data collection, the related tasks, including simulation task design, task-aware scene generation, expert demonstration synthesis, and sim-to-real transfer, still demand substantial human effort. We present AnyTask, an automated framework that pairs massively parallel GPU simulation with foundation models to design diverse manipulation tasks and synthesize robot data. We introduce three AnyTask agents for generating expert demonstrations aiming to solve as many tasks as possible: 1) ViPR, a novel task and motion planning agent with VLM-in-the-loop Parallel Refinement; 2) ViPR-Eureka, a reinforcement learning agent with generated dense rewards and LLM-guided contact sampling; 3) ViPR-RL, a hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards. We train behavior cloning policies on generated data, validate them in simulation, and deploy them directly on real robot hardware. The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks. Our project website is at https://anytask.rai-inst.com .
Sceniris: A Fast Procedural Scene Generation Framework
Dec 18, 2025Synthetic 3D scenes are essential for developing Physical AI and generative models. Existing procedural generation methods often have low output throughput, creating a significant bottleneck in scaling up dataset creation. In this work, we introduce Sceniris, a highly efficient procedural scene generation framework for rapidly generating large-scale, collision-free scene variations. Sceniris also provides an optional robot reachability check, providing manipulation-feasible scenes for robot tasks. Sceniris is designed for maximum efficiency by addressing the primary performance limitations of the prior method, Scene Synthesizer. Leveraging batch sampling and faster collision checking in cuRobo, Sceniris achieves at least 234x speed-up over Scene Synthesizer. Sceniris also expands the object-wise spatial relationships available in prior work to support diverse scene requirements. Our code is available at https://github.com/rai-inst/sceniris
Theia: Distilling Diverse Vision Foundation Models for Robot Learning
Jul 29, 2024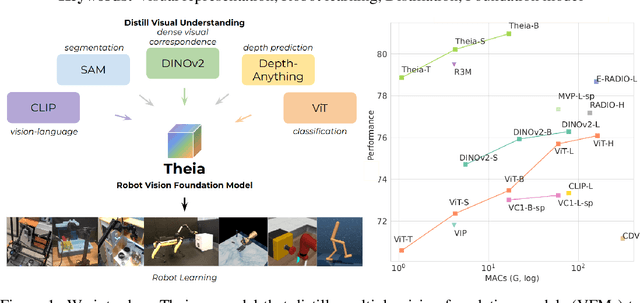



Vision-based robot policy learning, which maps visual inputs to actions, necessitates a holistic understanding of diverse visual tasks beyond single-task needs like classification or segmentation. Inspired by this, we introduce Theia, a vision foundation model for robot learning that distills multiple off-the-shelf vision foundation models trained on varied vision tasks. Theia's rich visual representations encode diverse visual knowledge, enhancing downstream robot learning. Extensive experiments demonstrate that Theia outperforms its teacher models and prior robot learning models using less training data and smaller model sizes. Additionally, we quantify the quality of pre-trained visual representations and hypothesize that higher entropy in feature norm distributions leads to improved robot learning performance. Code and models are available at https://github.com/bdaiinstitute/theia.
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Jun 28, 2024
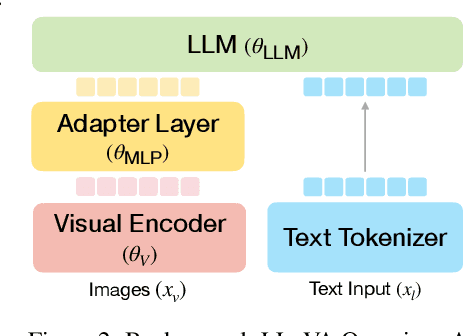
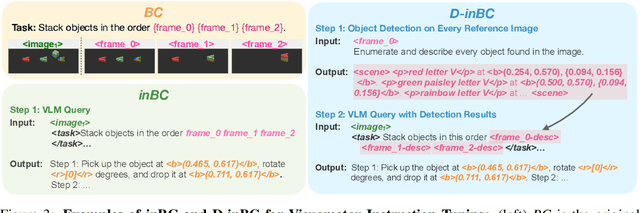

Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
Crossway Diffusion: Improving Diffusion-based Visuomotor Policy via Self-supervised Learning
Jul 04, 2023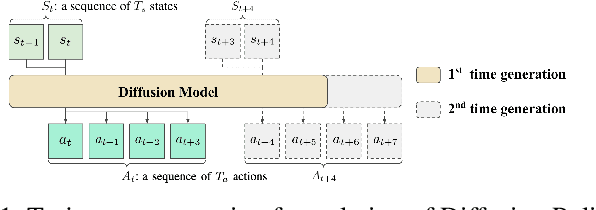

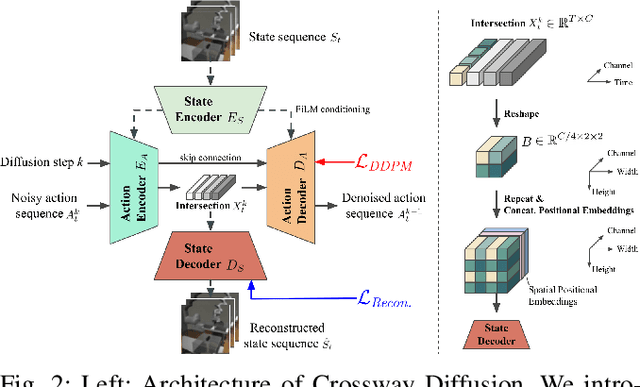

Sequence modeling approaches have shown promising results in robot imitation learning. Recently, diffusion models have been adopted for behavioral cloning, benefiting from their exceptional capabilities in modeling complex data distribution. In this work, we propose Crossway Diffusion, a method to enhance diffusion-based visuomotor policy learning by using an extra self-supervised learning (SSL) objective. The standard diffusion-based policy generates action sequences from random noise conditioned on visual observations and other low-dimensional states. We further extend this by introducing a new decoder that reconstructs raw image pixels (and other state information) from the intermediate representations of the reverse diffusion process, and train the model jointly using the SSL loss. Our experiments demonstrate the effectiveness of Crossway Diffusion in various simulated and real-world robot tasks, confirming its advantages over the standard diffusion-based policy. We demonstrate that such self-supervised reconstruction enables better representation for policy learning, especially when the demonstrations have different proficiencies.
Active Reinforcement Learning under Limited Visual Observability
Jun 01, 2023



In this work, we investigate Active Reinforcement Learning (Active-RL), where an embodied agent simultaneously learns action policy for the task while also controlling its visual observations in partially observable environments. We denote the former as motor policy and the latter as sensory policy. For example, humans solve real world tasks by hand manipulation (motor policy) together with eye movements (sensory policy). Active-RL poses challenges on coordinating two policies given their mutual influence. We propose SUGARL, Sensorimotor Understanding Guided Active Reinforcement Learning, a framework that models motor and sensory policies separately, but jointly learns them using with an intrinsic sensorimotor reward. This learnable reward is assigned by sensorimotor reward module, incentivizes the sensory policy to select observations that are optimal to infer its own motor action, inspired by the sensorimotor stage of humans. Through a series of experiments, we show the effectiveness of our method across a range of observability conditions and its adaptability to existed RL algorithms. The sensory policies learned through our method are observed to exhibit effective active vision strategies.
Neural Neural Textures Make Sim2Real Consistent
Jun 27, 2022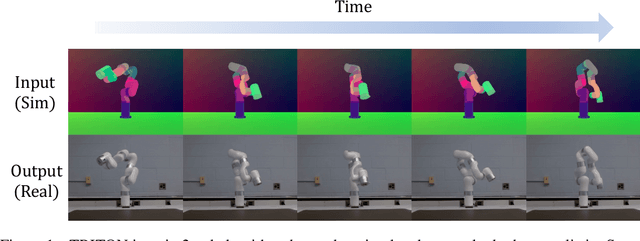
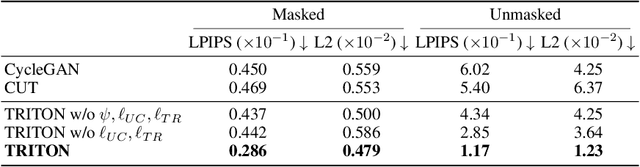


Unpaired image translation algorithms can be used for sim2real tasks, but many fail to generate temporally consistent results. We present a new approach that combines differentiable rendering with image translation to achieve temporal consistency over indefinite timescales, using surface consistency losses and \emph{neural neural textures}. We call this algorithm TRITON (Texture Recovering Image Translation Network): an unsupervised, end-to-end, stateless sim2real algorithm that leverages the underlying 3D geometry of input scenes by generating realistic-looking learnable neural textures. By settling on a particular texture for the objects in a scene, we ensure consistency between frames statelessly. Unlike previous algorithms, TRITON is not limited to camera movements -- it can handle the movement of objects as well, making it useful for downstream tasks such as robotic manipulation.
Learning Viewpoint-Agnostic Visual Representations by Recovering Tokens in 3D Space
Jun 23, 2022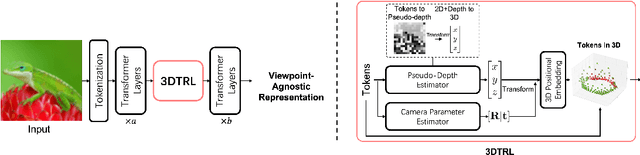
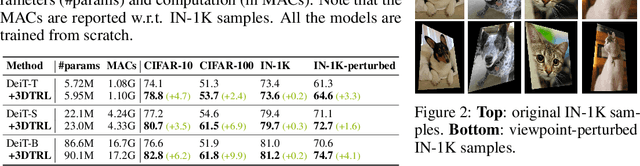


Humans are remarkably flexible in understanding viewpoint changes due to visual cortex supporting the perception of 3D structure. In contrast, most of the computer vision models that learn visual representation from a pool of 2D images often fail to generalize over novel camera viewpoints. Recently, the vision architectures have shifted towards convolution-free architectures, visual Transformers, which operate on tokens derived from image patches. However, neither these Transformers nor 2D convolutional networks perform explicit operations to learn viewpoint-agnostic representation for visual understanding. To this end, we propose a 3D Token Representation Layer (3DTRL) that estimates the 3D positional information of the visual tokens and leverages it for learning viewpoint-agnostic representations. The key elements of 3DTRL include a pseudo-depth estimator and a learned camera matrix to impose geometric transformations on the tokens. These enable 3DTRL to recover the 3D positional information of the tokens from 2D patches. In practice, 3DTRL is easily plugged-in into a Transformer. Our experiments demonstrate the effectiveness of 3DTRL in many vision tasks including image classification, multi-view video alignment, and action recognition. The models with 3DTRL outperform their backbone Transformers in all the tasks with minimal added computation. Our project page is at https://www3.cs.stonybrook.edu/~jishang/3dtrl/3dtrl.html
Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?
Jun 23, 2022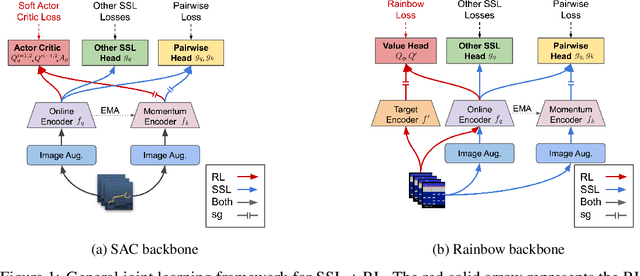

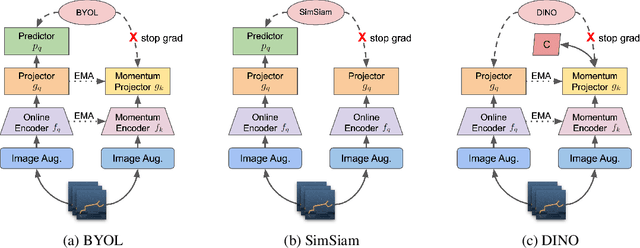

We investigate whether self-supervised learning (SSL) can improve online reinforcement learning (RL) from pixels. We extend the contrastive reinforcement learning framework (e.g., CURL) that jointly optimizes SSL and RL losses and conduct an extensive amount of experiments with various self-supervised losses. Our observations suggest that the existing SSL framework for RL fails to bring meaningful improvement over the baselines only taking advantage of image augmentation when the same amount of data and augmentation is used. We further perform an evolutionary search to find the optimal combination of multiple self-supervised losses for RL, but find that even such a loss combination fails to meaningfully outperform the methods that only utilize carefully designed image augmentations. Often, the use of self-supervised losses under the existing framework lowered RL performances. We evaluate the approach in multiple different environments including a real-world robot environment and confirm that no single self-supervised loss or image augmentation method can dominate all environments and that the current framework for joint optimization of SSL and RL is limited. Finally, we empirically investigate the pretraining framework for SSL + RL and the properties of representations learned with different approaches.
Learning for Expressive Task-Related Sentence Representations
May 24, 2022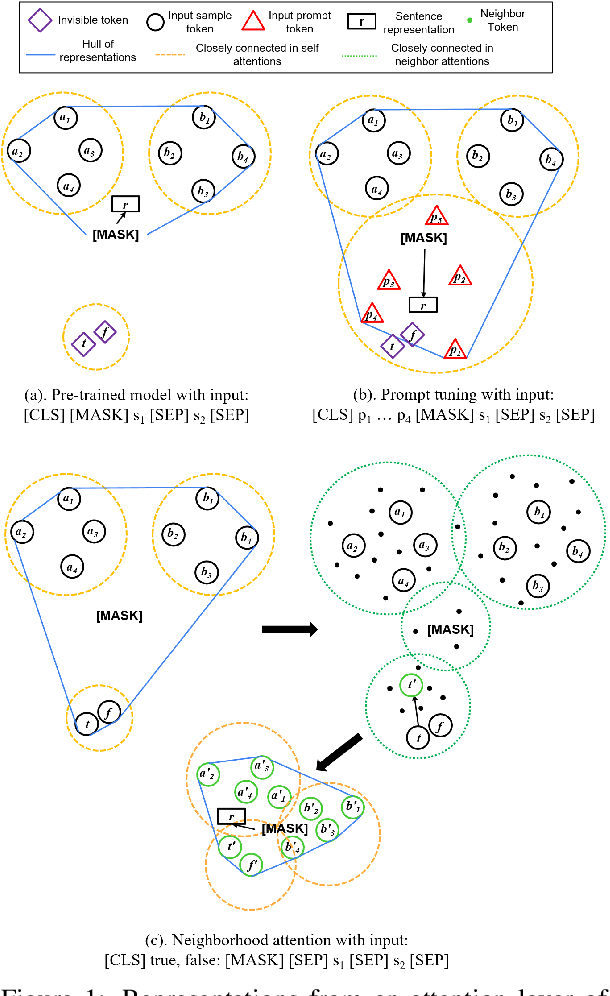



NLP models learn sentence representations for downstream tasks by tuning a model which is pre-trained by masked language modeling. However, after tuning, the learned sentence representations may be skewed heavily toward label space and thus are not expressive enough to represent whole samples, which should contain task-related information of both sentence inputs and labels. In this work, we learn expressive sentence representations for supervised tasks which (1). contain task-related information in the sentence inputs, and (2). enable correct label predictions. To achieve this goal, we first propose a new objective which explicitly points out the label token space in the input, and predicts categories of labels via an added [MASK] token. This objective encourages fusing the semantic information of both the label and sentence. Then we develop a neighbor attention module, added on a frozen pre-trained model, to build connections between label/sentence tokens via their neighbors. The propagation can be further guided by the regularization on neighborhood representations to encourage expressiveness. Experimental results show that, despite tuning only 5% additional parameters over a frozen pre-trained model, our model can achieve classification results comparable to the SOTA while maintaining strong expressiveness as well.