 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning for Expressive Task-Related Sentence Representations
Paper and Code
May 24, 2022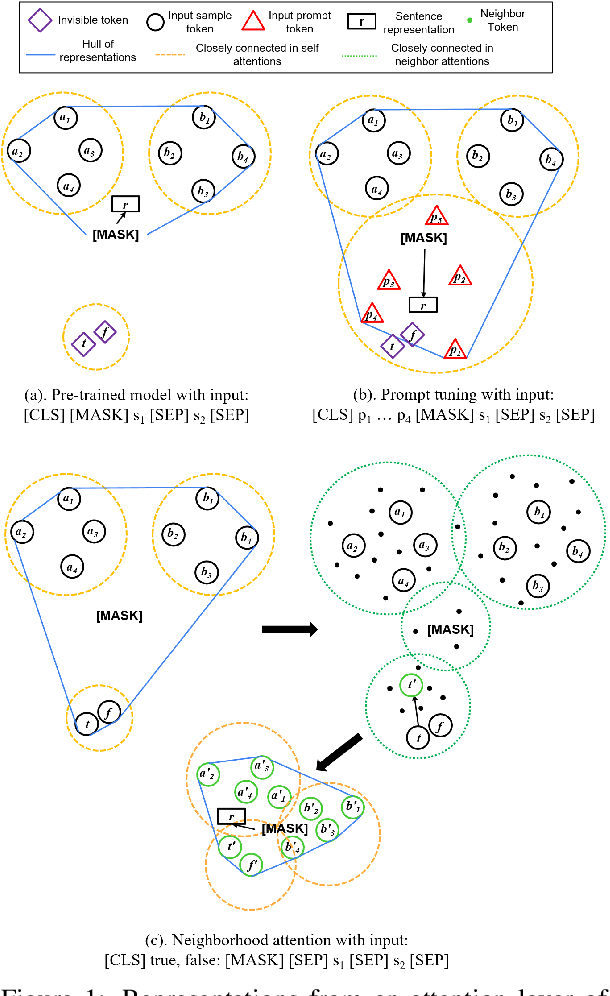



NLP models learn sentence representations for downstream tasks by tuning a model which is pre-trained by masked language modeling. However, after tuning, the learned sentence representations may be skewed heavily toward label space and thus are not expressive enough to represent whole samples, which should contain task-related information of both sentence inputs and labels. In this work, we learn expressive sentence representations for supervised tasks which (1). contain task-related information in the sentence inputs, and (2). enable correct label predictions. To achieve this goal, we first propose a new objective which explicitly points out the label token space in the input, and predicts categories of labels via an added [MASK] token. This objective encourages fusing the semantic information of both the label and sentence. Then we develop a neighbor attention module, added on a frozen pre-trained model, to build connections between label/sentence tokens via their neighbors. The propagation can be further guided by the regularization on neighborhood representations to encourage expressiveness. Experimental results show that, despite tuning only 5% additional parameters over a frozen pre-trained model, our model can achieve classification results comparable to the SOTA while maintaining strong expressiveness as well.