 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMrM: Black-Box Membership Inference Attacks against Multimodal RAG Systems
Jun 09, 2025



Multimodal retrieval-augmented generation (RAG) systems enhance large vision-language models by integrating cross-modal knowledge, enabling their increasing adoption across real-world multimodal tasks. These knowledge databases may contain sensitive information that requires privacy protection. However, multimodal RAG systems inherently grant external users indirect access to such data, making them potentially vulnerable to privacy attacks, particularly membership inference attacks (MIAs). % Existing MIA methods targeting RAG systems predominantly focus on the textual modality, while the visual modality remains relatively underexplored. To bridge this gap, we propose MrM, the first black-box MIA framework targeted at multimodal RAG systems. It utilizes a multi-object data perturbation framework constrained by counterfactual attacks, which can concurrently induce the RAG systems to retrieve the target data and generate information that leaks the membership information. Our method first employs an object-aware data perturbation method to constrain the perturbation to key semantics and ensure successful retrieval. Building on this, we design a counterfact-informed mask selection strategy to prioritize the most informative masked regions, aiming to eliminate the interference of model self-knowledge and amplify attack efficacy. Finally, we perform statistical membership inference by modeling query trials to extract features that reflect the reconstruction of masked semantics from response patterns. Experiments on two visual datasets and eight mainstream commercial visual-language models (e.g., GPT-4o, Gemini-2) demonstrate that MrM achieves consistently strong performance across both sample-level and set-level evaluations, and remains robust under adaptive defenses.
Causal Graph based Event Reasoning using Semantic Relation Experts
Jun 07, 2025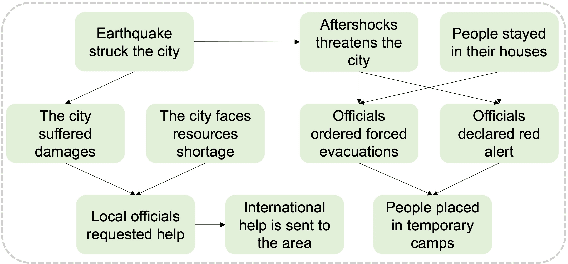
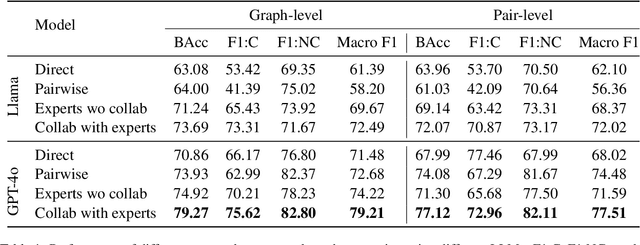
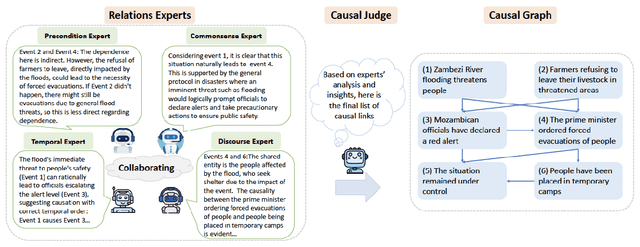
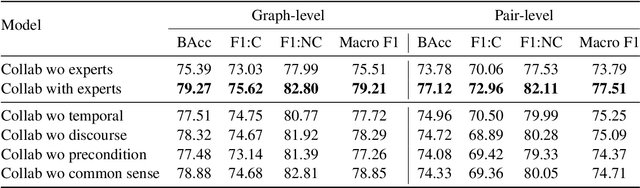
Understanding how events in a scenario causally connect with each other is important for effectively modeling and reasoning about events. But event reasoning remains a difficult challenge, and despite recent advances, Large Language Models (LLMs) still struggle to accurately identify causal connections between events. This struggle leads to poor performance on deeper reasoning tasks like event forecasting and timeline understanding. To address this challenge, we investigate the generation of causal event graphs (e.g., A enables B) as a parallel mechanism to help LLMs explicitly represent causality during inference. This paper evaluates both how to generate correct graphs as well as how graphs can assist reasoning. We propose a collaborative approach to causal graph generation where we use LLMs to simulate experts that focus on specific semantic relations. The experts engage in multiple rounds of discussions which are then consolidated by a final expert. Then, to demonstrate the utility of causal graphs, we use them on multiple downstream applications, and also introduce a new explainable event prediction task that requires a causal chain of events in the explanation. These explanations are more informative and coherent than baseline generations. Finally, our overall approach not finetuned on any downstream task, achieves competitive results with state-of-the-art models on both forecasting and next event prediction tasks.
Does RoBERTa Perform Better than BERT in Continual Learning: An Attention Sink Perspective
Oct 08, 2024
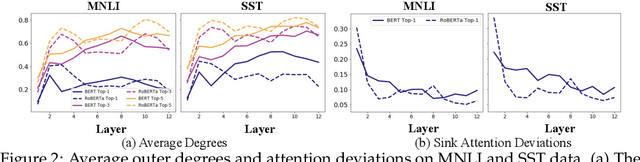


Continual learning (CL) aims to train models that can sequentially learn new tasks without forgetting previous tasks' knowledge. Although previous works observed that pre-training can benefit CL, it remains unclear whether a pre-trained model with higher downstream capacity also performs better in CL. In this paper, we observe that pre-trained models may allocate high attention scores to some 'sink' tokens, such as [SEP] tokens, which are ubiquitous across various tasks. Such attention sinks may lead to models' over-smoothing in single-task learning and interference in sequential tasks' learning, which may compromise the models' CL performance despite their high pre-trained capabilities. To reduce these effects, we propose a pre-scaling mechanism that encourages attention diversity across all tokens. Specifically, it first scales the task's attention to the non-sink tokens in a probing stage, and then fine-tunes the model with scaling. Experiments show that pre-scaling yields substantial improvements in CL without experience replay, or progressively storing parameters from previous tasks.
Learning for Expressive Task-Related Sentence Representations
May 24, 2022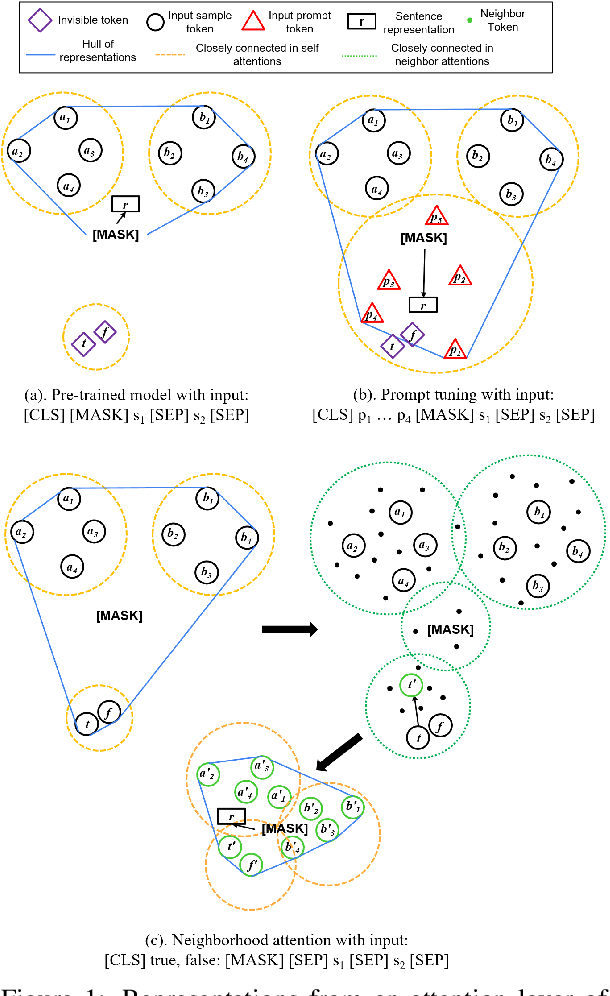



NLP models learn sentence representations for downstream tasks by tuning a model which is pre-trained by masked language modeling. However, after tuning, the learned sentence representations may be skewed heavily toward label space and thus are not expressive enough to represent whole samples, which should contain task-related information of both sentence inputs and labels. In this work, we learn expressive sentence representations for supervised tasks which (1). contain task-related information in the sentence inputs, and (2). enable correct label predictions. To achieve this goal, we first propose a new objective which explicitly points out the label token space in the input, and predicts categories of labels via an added [MASK] token. This objective encourages fusing the semantic information of both the label and sentence. Then we develop a neighbor attention module, added on a frozen pre-trained model, to build connections between label/sentence tokens via their neighbors. The propagation can be further guided by the regularization on neighborhood representations to encourage expressiveness. Experimental results show that, despite tuning only 5% additional parameters over a frozen pre-trained model, our model can achieve classification results comparable to the SOTA while maintaining strong expressiveness as well.
Model-Based Reinforcement Learning with Adversarial Training for Online Recommendation
Nov 13, 2019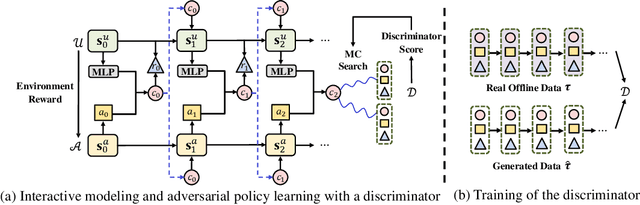

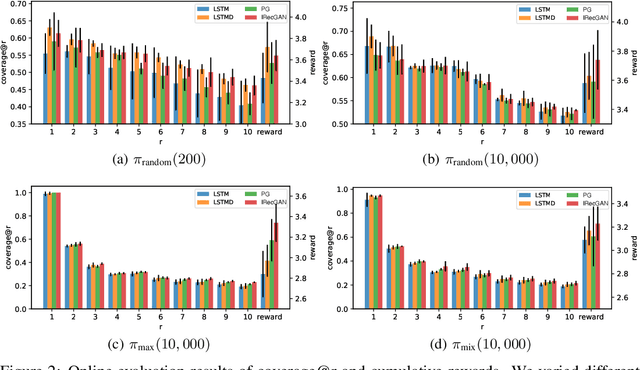
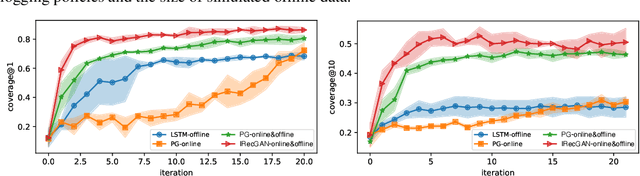
Reinforcement learning is effective in optimizing policies for recommender systems. Current solutions mostly focus on model-free approaches, which require frequent interactions with a real environment, and thus are expensive in model learning. Offline evaluation methods, such as importance sampling, can alleviate such limitations, but usually request a large amount of logged data and do not work well when the action space is large. In this work, we propose a model-based reinforcement learning solution which models the user-agent interaction for offline policy learning via a generative adversarial network. To reduce bias in the learnt policy, we use the discriminator to evaluate the quality of generated sequences and rescale the generated rewards. Our theoretical analysis and empirical evaluations demonstrate the effectiveness of our solution in identifying patterns from given offline data and learning policies based on the offline and generated data.
Learning Robust, Transferable Sentence Representations for Text Classification
Sep 28, 2018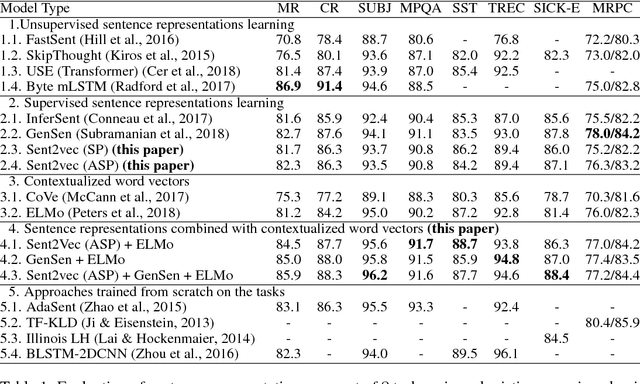
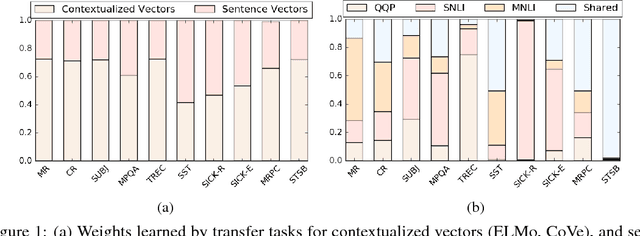

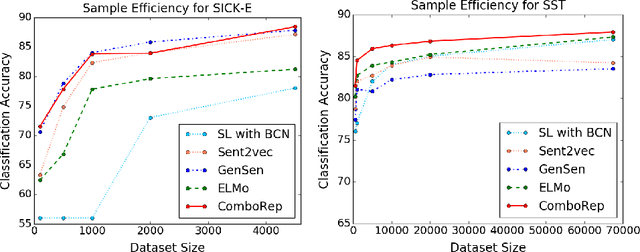
Despite deep recurrent neural networks (RNNs) demonstrate strong performance in text classification, training RNN models are often expensive and requires an extensive collection of annotated data which may not be available. To overcome the data limitation issue, existing approaches leverage either pre-trained word embedding or sentence representation to lift the burden of training RNNs from scratch. In this paper, we show that jointly learning sentence representations from multiple text classification tasks and combining them with pre-trained word-level and sentence level encoders result in robust sentence representations that are useful for transfer learning. Extensive experiments and analyses using a wide range of transfer and linguistic tasks endorse the effectiveness of our approach.
Multi-task Learning for Universal Sentence Embeddings: A Thorough Evaluation using Transfer and Auxiliary Tasks
Aug 16, 2018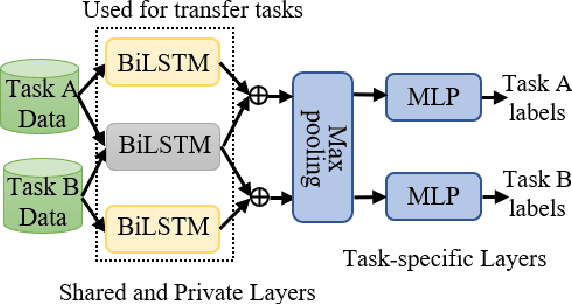

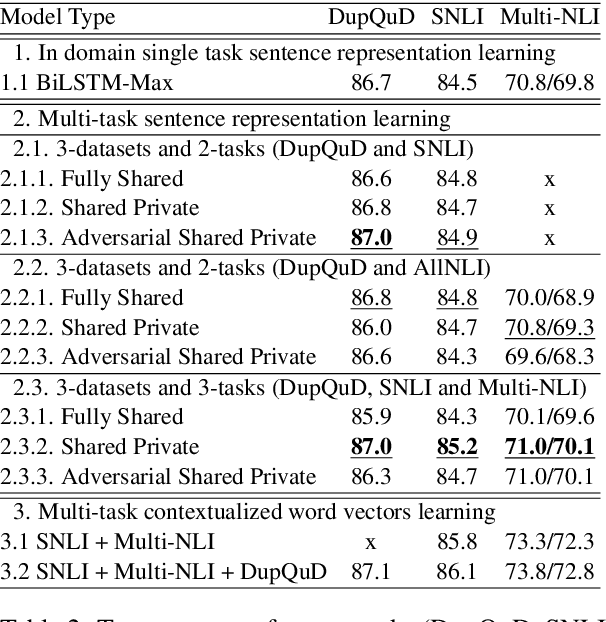
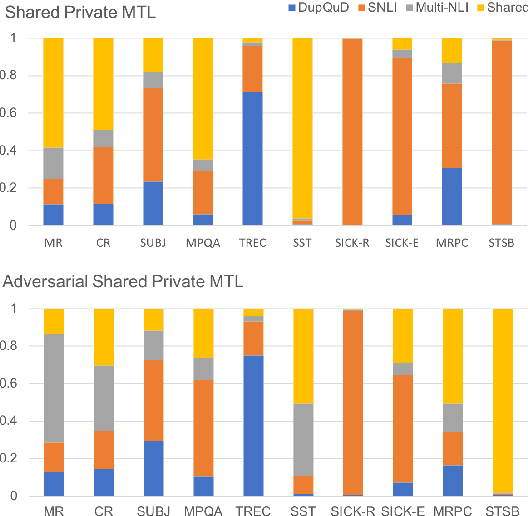
Learning distributed sentence representations is one of the key challenges in natural language processing. Previous work demonstrated that a recurrent neural network (RNNs) based sentence encoder trained on a large collection of annotated natural language inference data, is efficient in the transfer learning to facilitate other related tasks. In this paper, we show that joint learning of multiple tasks results in better generalizable sentence representations by conducting extensive experiments and analysis comparing the multi-task and single-task learned sentence encoders. The quantitative analysis using auxiliary tasks show that multi-task learning helps to embed better semantic information in the sentence representations compared to single-task learning. In addition, we compare multi-task sentence encoders with contextualized word representations and show that combining both of them can further boost the performance of transfer learning.