 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes RoBERTa Perform Better than BERT in Continual Learning: An Attention Sink Perspective
Paper and Code

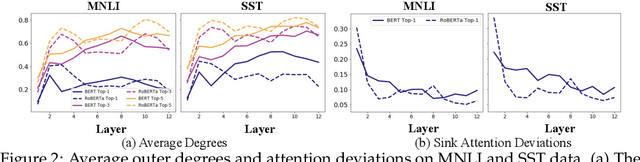


Continual learning (CL) aims to train models that can sequentially learn new tasks without forgetting previous tasks' knowledge. Although previous works observed that pre-training can benefit CL, it remains unclear whether a pre-trained model with higher downstream capacity also performs better in CL. In this paper, we observe that pre-trained models may allocate high attention scores to some 'sink' tokens, such as [SEP] tokens, which are ubiquitous across various tasks. Such attention sinks may lead to models' over-smoothing in single-task learning and interference in sequential tasks' learning, which may compromise the models' CL performance despite their high pre-trained capabilities. To reduce these effects, we propose a pre-scaling mechanism that encourages attention diversity across all tokens. Specifically, it first scales the task's attention to the non-sink tokens in a probing stage, and then fine-tunes the model with scaling. Experiments show that pre-scaling yields substantial improvements in CL without experience replay, or progressively storing parameters from previous tasks.