 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Really Need to Approach the Entire Pareto Front in Many-Objective Bayesian Optimisation?
Apr 10, 2026Many-objective optimisation, a subset of multi-objective optimisation, involves optimisation problems with more than three objectives. As the number of objectives increases, the number of solutions needed to adequately represent the entire Pareto front typically grows substantially. This makes it challenging, if not infeasible, to design a search algorithm capable of effectively exploring the entire Pareto front. This difficulty is particularly acute in the Bayesian optimisation paradigm, where sample efficiency is critical and only a limited number of solutions (often a few hundred) are evaluated. Moreover, after the optimisation process, the decision-maker eventually selects just one solution for deployment, regardless of how many high-quality, diverse solutions are available. In light of this, we argue an idea that under a very limited evaluation budget, it may be more useful to focus on finding a single solution of the highest possible quality for the decision-maker, rather than aiming to approximate the entire Pareto front as existing many-/multi-objective Bayesian optimisation methods typically do. Bearing this idea in mind, this paper proposes a \underline{s}ingle \underline{p}oint-based \underline{m}ulti-\underline{o}bjective search framework (SPMO) that aims to improve the quality of solutions along a direction that leads to a good tradeoff between objectives. Within SPMO, we present a simple acquisition function, called expected single-point improvement (ESPI), working under both noiseless and noisy scenarios. We show that ESPI can be optimised effectively with gradient-based methods via the sample average approximation (SAA) approach and theoretically prove its convergence guarantees under the SAA. We also empirically demonstrate that the proposed SPMO is computationally tractable and outperforms state-of-the-arts on a wide range of benchmark and real-world problems.
Revealing Domain-Spatiality Patterns for Configuration Tuning: Domain Knowledge Meets Fitness Landscapes
Mar 23, 2026Configuration tuning for better performance is crucial in quality assurance. Yet, there has long been a mystery on tuners' effectiveness, due to the black-box nature of configurable systems. Prior efforts predominantly adopt static domain analysis (e.g., static taint analysis), which often lacks generalizability, or dynamic data analysis (e.g., benchmarking performance analysis), limiting explainability. In this work, we embrace Fitness Landscape Analysis (FLA) as a bridge between domain knowledge and difficulty of the tuning. We propose Domland, a two-pronged methodology that synergizes the spatial information obtained from FLA and domain-driven analysis to systematically capture the hidden characteristics of configuration tuning cases, explaining how and why a tuner might succeed or fail. This helps to better interpret and contextualize the behavior of tuners and inform tuner design. To evaluate Domland, we conduct a case study of nine software systems and 93 workloads, from which we reveal several key findings: (1) configuration landscapes are inherently system-specific, with no single domain factor (e.g., system area, programming language, or resource intensity) consistently shaping their structure; (2) the core options (e.g., pic-struct of x264), which control the main functional flows, exert a stronger influence on landscape ruggedness (i.e. the difficulty of tuning) compared to resource options (e.g., cpu-independent of x264); (3) Workload effects on landscape structure are not uniformly tied to type or scale. Both contribute to landscape variations, but their impact is system-dependent.
KDCM: Reducing Hallucination in LLMs through Explicit Reasoning Structures
Jan 07, 2026To mitigate hallucinations in large language models (LLMs), we propose a framework that focuses on errors induced by prompts. Our method extends a chain-style knowledge distillation approach by incorporating a programmable module that guides knowledge graph exploration. This module is embedded as executable code within the reasoning prompt, allowing the model to leverage external structured knowledge during inference. Based on this design, we develop an enhanced distillation-based reasoning framework that explicitly regulates intermediate reasoning steps, resulting in more reliable predictions. We evaluate the proposed approach on multiple public benchmarks using GPT-4 and LLaMA-3.3. Experimental results show that code-guided reasoning significantly improves contextual modeling and reduces prompt-induced hallucinations. Specifically, HIT@1, HIT@3, and HIT@5 increase by 15.64%, 13.38%, and 13.28%, respectively, with scores exceeding 95% across several evaluation settings. These findings indicate that the proposed method effectively constrains erroneous reasoning while improving both accuracy and interpretability.
Mitigating Prompt-Induced Hallucinations in Large Language Models via Structured Reasoning
Jan 06, 2026To address hallucination issues in large language models (LLMs), this paper proposes a method for mitigating prompt-induced hallucinations. Building on a knowledge distillation chain-style model, we introduce a code module to guide knowledge-graph exploration and incorporate code as part of the chain-of-thought prompt, forming an external knowledge input that provides more accurate and structured information to the model. Based on this design, we develop an improved knowledge distillation chain-style model and leverage it to analyze and constrain the reasoning process of LLMs, thereby improving inference accuracy. We empirically evaluate the proposed approach using GPT-4 and LLaMA-3.3 on multiple public datasets. Experimental results demonstrate that incorporating code modules significantly enhances the model's ability to capture contextual information and effectively mitigates prompt-induced hallucinations. Specifically, HIT@1, HIT@3, and HIT@5 improve by 15.64%, 13.38%, and 13.28%, respectively. Moreover, the proposed method achieves HIT@1, HIT@3, and HIT@5 scores exceeding 95% across several evaluation settings. These results indicate that the proposed approach substantially reduces hallucination behavior while improving the accuracy and verifiability of large language models.
MedReadMe: A Systematic Study for Fine-grained Sentence Readability in Medical Domain
May 03, 2024Medical texts are notoriously challenging to read. Properly measuring their readability is the first step towards making them more accessible. In this paper, we present a systematic study on fine-grained readability measurements in the medical domain at both sentence-level and span-level. We introduce a new dataset MedReadMe, which consists of manually annotated readability ratings and fine-grained complex span annotation for 4,520 sentences, featuring two novel "Google-Easy" and "Google-Hard" categories. It supports our quantitative analysis, which covers 650 linguistic features and automatic complex word and jargon identification. Enabled by our high-quality annotation, we benchmark and improve several state-of-the-art sentence-level readability metrics for the medical domain specifically, which include unsupervised, supervised, and prompting-based methods using recently developed large language models (LLMs). Informed by our fine-grained complex span annotation, we find that adding a single feature, capturing the number of jargon spans, into existing readability formulas can significantly improve their correlation with human judgments. We will publicly release the dataset and code.
Successfully Applying Lottery Ticket Hypothesis to Diffusion Model
Oct 28, 2023



Despite the success of diffusion models, the training and inference of diffusion models are notoriously expensive due to the long chain of the reverse process. In parallel, the Lottery Ticket Hypothesis (LTH) claims that there exists winning tickets (i.e., aproperly pruned sub-network together with original weight initialization) that can achieve performance competitive to the original dense neural network when trained in isolation. In this work, we for the first time apply LTH to diffusion models. We empirically find subnetworks at sparsity 90%-99% without compromising performance for denoising diffusion probabilistic models on benchmarks (CIFAR-10, CIFAR-100, MNIST). Moreover, existing LTH works identify the subnetworks with a unified sparsity along different layers. We observe that the similarity between two winning tickets of a model varies from block to block. Specifically, the upstream layers from two winning tickets for a model tend to be more similar than the downstream layers. Therefore, we propose to find the winning ticket with varying sparsity along different layers in the model. Experimental results demonstrate that our method can find sparser sub-models that require less memory for storage and reduce the necessary number of FLOPs. Codes are available at https://github.com/osier0524/Lottery-Ticket-to-DDPM.
Frustratingly Easy Label Projection for Cross-lingual Transfer
Dec 04, 2022
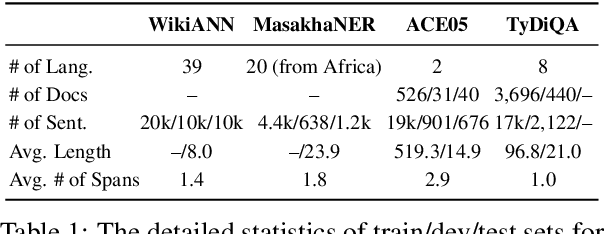
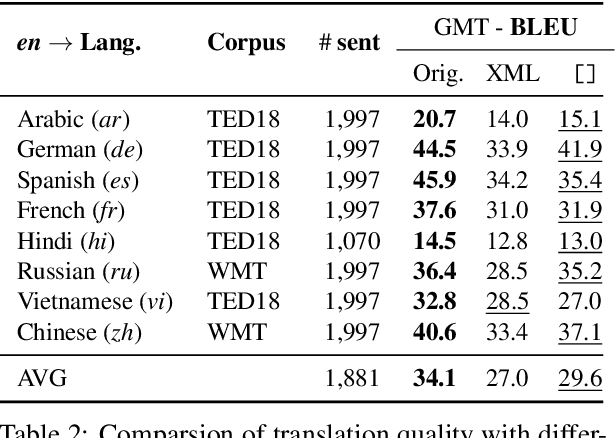
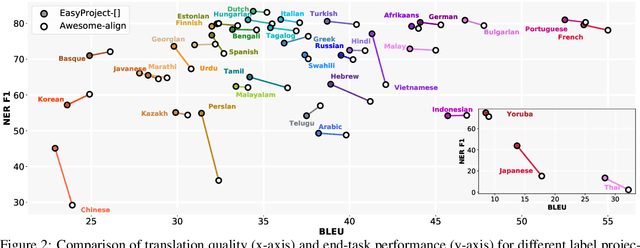
Translating training data into many languages has emerged as a practical solution for improving cross-lingual transfer. For tasks that involve span-level annotations, such as information extraction or question answering, an additional label projection step is required to map annotated spans onto the translated texts. Recently, a few efforts have utilized a simple mark-then-translate method to jointly perform translation and projection by inserting special markers around the labeled spans in the original sentence. However, as far as we are aware, no empirical analysis has been conducted on how this approach compares to traditional annotation projection based on word alignment. In this paper, we present an extensive empirical study across 42 languages and three tasks (QA, NER, and Event Extraction) to evaluate the effectiveness and limitations of both methods, filling an important gap in the literature. Experimental results show that our optimized version of mark-then-translate, which we call EasyProject, is easily applied to many languages and works surprisingly well, outperforming the more complex word alignment-based methods. We analyze several key factors that affect end-task performance, and show EasyProject works well because it can accurately preserve label span boundaries after translation. We will publicly release all our code and data.
arXivEdits: Understanding the Human Revision Process in Scientific Writing
Oct 31, 2022Scientific publications are the primary means to communicate research discoveries, where the writing quality is of crucial importance. However, prior work studying the human editing process in this domain mainly focused on the abstract or introduction sections, resulting in an incomplete picture. In this work, we provide a complete computational framework for studying text revision in scientific writing. We first introduce arXivEdits, a new annotated corpus of 751 full papers from arXiv with gold sentence alignment across their multiple versions of revision, as well as fine-grained span-level edits and their underlying intentions for 1,000 sentence pairs. It supports our data-driven analysis to unveil the common strategies practiced by researchers for revising their papers. To scale up the analysis, we also develop automatic methods to extract revision at document-, sentence-, and word-levels. A neural CRF sentence alignment model trained on our corpus achieves 93.8 F1, enabling the reliable matching of sentences between different versions. We formulate the edit extraction task as a span alignment problem, and our proposed method extracts more fine-grained and explainable edits, compared to the commonly used diff algorithm. An intention classifier trained on our dataset achieves 78.9 F1 on the fine-grained intent classification task. Our data and system are released at tiny.one/arxivedits.
Improving Large-scale Paraphrase Acquisition and Generation
Oct 06, 2022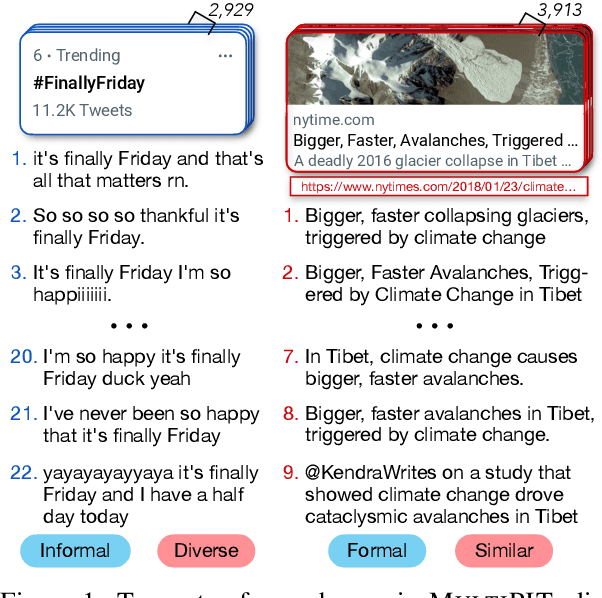
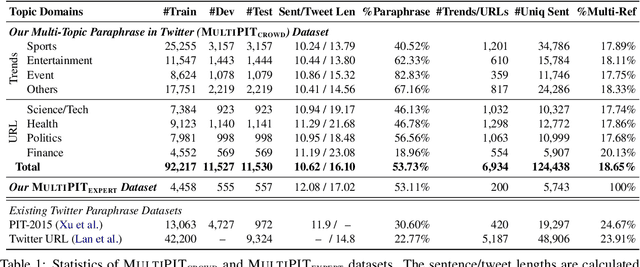
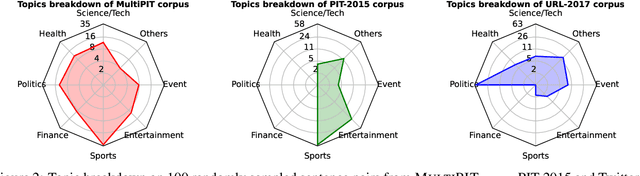
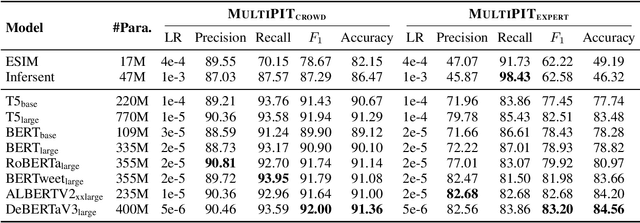
This paper addresses the quality issues in existing Twitter-based paraphrase datasets, and discusses the necessity of using two separate definitions of paraphrase for identification and generation tasks. We present a new Multi-Topic Paraphrase in Twitter (MultiPIT) corpus that consists of a total of 130k sentence pairs with crowdsoursing (MultiPIT_crowd) and expert (MultiPIT_expert) annotations using two different paraphrase definitions for paraphrase identification, in addition to a multi-reference test set (MultiPIT_NMR) and a large automatically constructed training set (MultiPIT_Auto) for paraphrase generation. With improved data annotation quality and task-specific paraphrase definition, the best pre-trained language model fine-tuned on our dataset achieves the state-of-the-art performance of 84.2 F1 for automatic paraphrase identification. Furthermore, our empirical results also demonstrate that the paraphrase generation models trained on MultiPIT_Auto generate more diverse and high-quality paraphrases compared to their counterparts fine-tuned on other corpora such as Quora, MSCOCO, and ParaNMT.
A New Adaptive Noise Covariance Matrices Estimation and Filtering Method: Application to Multi-Object Tracking
Dec 20, 2021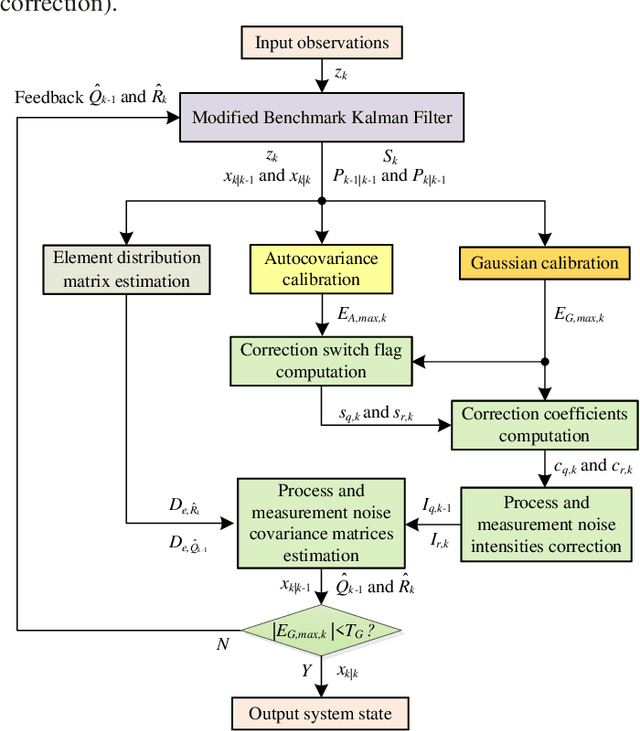
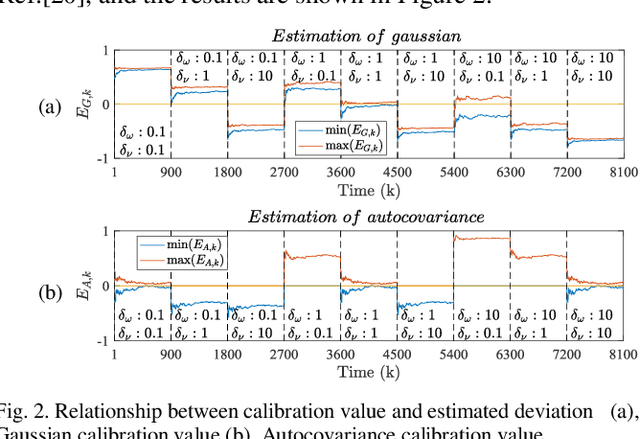
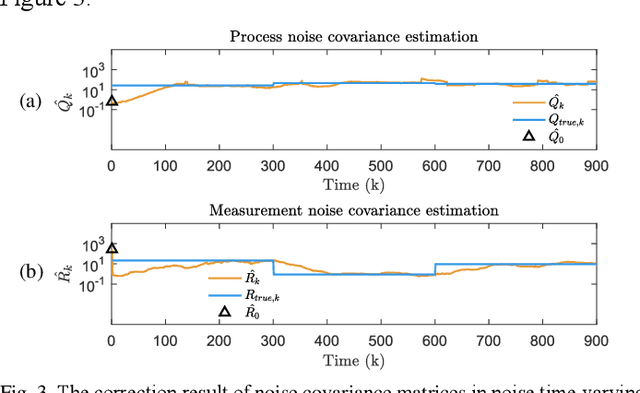
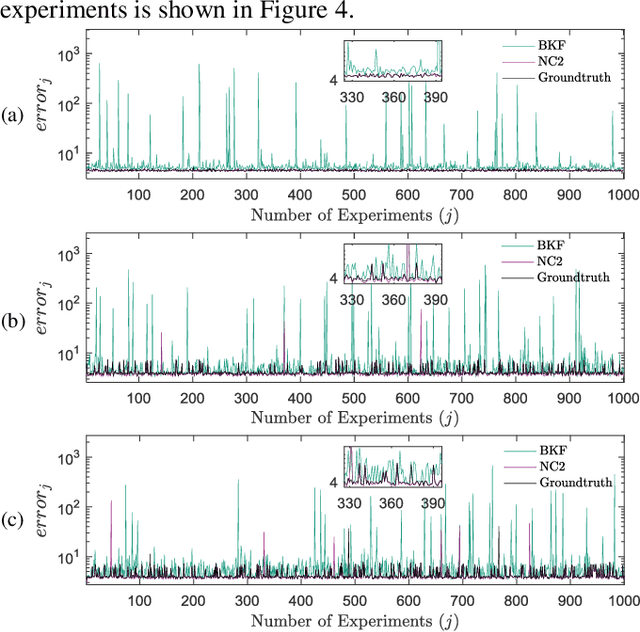
Kalman filters are widely used for object tracking, where process and measurement noise are usually considered accurately known and constant. However, the exact known and constant assumptions do not always hold in practice. For example, when lidar is used to track noncooperative targets, the measurement noise is different under different distances and weather conditions. In addition, the process noise changes with the object's motion state, especially when the tracking object is a pedestrian, and the process noise changes more frequently. This paper proposes a new estimation-calibration-correction closed-loop estimation method to estimate the Kalman filter process and measurement noise covariance matrices online. First, we decompose the noise covariance matrix into an element distribution matrix and noise intensity and improve the Sage filter to estimate the element distribution matrix. Second, we propose a calibration method to accurately diagnose the noise intensity deviation. We then propose a correct method to adaptively correct the noise intensity online. Third, under the assumption that the system is detectable, the unbiased and convergence of the proposed method is mathematically proven. Simulation results prove the effectiveness and reliability of the proposed method. Finally, we apply the proposed method to multiobject tracking of lidar and evaluate it on the official KITTI server. The proposed method on the KITTI pedestrian multiobject tracking leaderboard (http://www.cvlibs.net/datasets /kitti/eval_tracking.php) surpasses all existing methods using lidar, proving the feasibility of the method in practical applications. This work provides a new way to improve the performance of the Kalman filter and multiobject tracking.