 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph based Event Reasoning using Semantic Relation Experts
Jun 07, 2025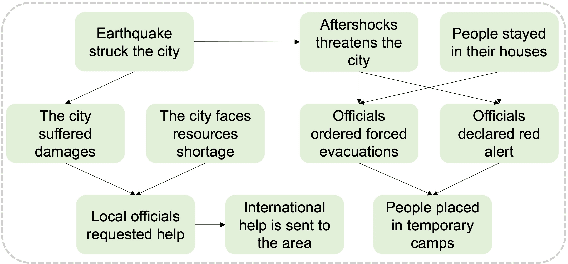
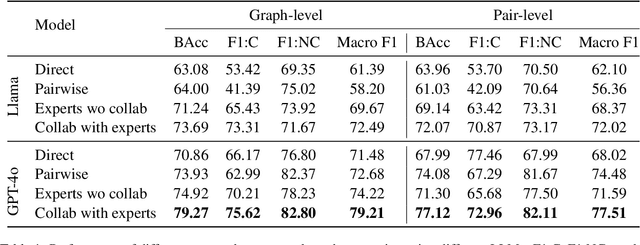
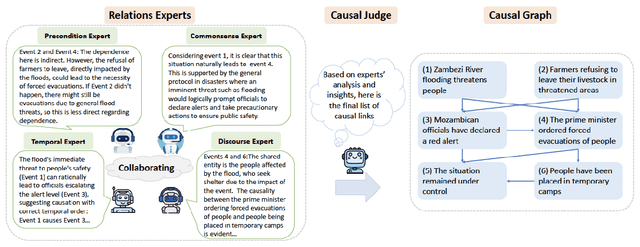
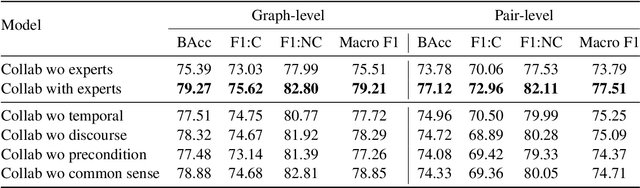
Understanding how events in a scenario causally connect with each other is important for effectively modeling and reasoning about events. But event reasoning remains a difficult challenge, and despite recent advances, Large Language Models (LLMs) still struggle to accurately identify causal connections between events. This struggle leads to poor performance on deeper reasoning tasks like event forecasting and timeline understanding. To address this challenge, we investigate the generation of causal event graphs (e.g., A enables B) as a parallel mechanism to help LLMs explicitly represent causality during inference. This paper evaluates both how to generate correct graphs as well as how graphs can assist reasoning. We propose a collaborative approach to causal graph generation where we use LLMs to simulate experts that focus on specific semantic relations. The experts engage in multiple rounds of discussions which are then consolidated by a final expert. Then, to demonstrate the utility of causal graphs, we use them on multiple downstream applications, and also introduce a new explainable event prediction task that requires a causal chain of events in the explanation. These explanations are more informative and coherent than baseline generations. Finally, our overall approach not finetuned on any downstream task, achieves competitive results with state-of-the-art models on both forecasting and next event prediction tasks.
MuSciClaims: Multimodal Scientific Claim Verification
Jun 05, 2025



Assessing scientific claims requires identifying, extracting, and reasoning with multimodal data expressed in information-rich figures in scientific literature. Despite the large body of work in scientific QA, figure captioning, and other multimodal reasoning tasks over chart-based data, there are no readily usable multimodal benchmarks that directly test claim verification abilities. To remedy this gap, we introduce a new benchmark MuSciClaims accompanied by diagnostics tasks. We automatically extract supported claims from scientific articles, which we manually perturb to produce contradicted claims. The perturbations are designed to test for a specific set of claim verification capabilities. We also introduce a suite of diagnostic tasks that help understand model failures. Our results show most vision-language models are poor (~0.3-0.5 F1), with even the best model only achieving 0.77 F1. They are also biased towards judging claims as supported, likely misunderstanding nuanced perturbations within the claims. Our diagnostics show models are bad at localizing correct evidence within figures, struggle with aggregating information across modalities, and often fail to understand basic components of the figure.
$\texttt{DIAMONDs}$: A Dataset for $\mathbb{D}$ynamic $\mathbb{I}$nformation $\mathbb{A}$nd $\mathbb{M}$ental modeling $\mathbb{O}$f $\mathbb{N}$umeric $\mathbb{D}$iscussions
May 19, 2025Understanding multiparty conversations demands robust Theory of Mind (ToM) capabilities, including the ability to track dynamic information, manage knowledge asymmetries, and distinguish relevant information across extended exchanges. To advance ToM evaluation in such settings, we present a carefully designed scalable methodology for generating high-quality benchmark conversation-question pairs with these characteristics. Using this methodology, we create $\texttt{DIAMONDs}$, a new conversational QA dataset covering common business, financial or other group interactions. In these goal-oriented conversations, participants often have to track certain numerical quantities (say $\textit{expected profit}$) of interest that can be derived from other variable quantities (like $\textit{marketing expenses, expected sales, salary}$, etc.), whose values also change over the course of the conversation. $\texttt{DIAMONDs}$ questions pose simple numerical reasoning problems over such quantities of interest (e.g., $\textit{funds required for charity events, expected company profit next quarter}$, etc.) in the context of the information exchanged in conversations. This allows for precisely evaluating ToM capabilities for carefully tracking and reasoning over participants' knowledge states. Our evaluation of state-of-the-art language models reveals significant challenges in handling participant-centric reasoning, specifically in situations where participants have false beliefs. Models also struggle with conversations containing distractors and show limited ability to identify scenarios with insufficient information. These findings highlight current models' ToM limitations in handling real-world multi-party conversations.
Faithful, Unfaithful or Ambiguous? Multi-Agent Debate with Initial Stance for Summary Evaluation
Feb 12, 2025Faithfulness evaluators based on large language models (LLMs) are often fooled by the fluency of the text and struggle with identifying errors in the summaries. We propose an approach to summary faithfulness evaluation in which multiple LLM-based agents are assigned initial stances (regardless of what their belief might be) and forced to come up with a reason to justify the imposed belief, thus engaging in a multi-round debate to reach an agreement. The uniformly distributed initial assignments result in a greater diversity of stances leading to more meaningful debates and ultimately more errors identified. Furthermore, by analyzing the recent faithfulness evaluation datasets, we observe that naturally, it is not always the case for a summary to be either faithful to the source document or not. We therefore introduce a new dimension, ambiguity, and a detailed taxonomy to identify such special cases. Experiments demonstrate our approach can help identify ambiguities, and have even a stronger performance on non-ambiguous summaries.
Modeling Complex Event Scenarios via Simple Entity-focused Questions
Feb 14, 2023



Event scenarios are often complex and involve multiple event sequences connected through different entity participants. Exploring such complex scenarios requires an ability to branch through different sequences, something that is difficult to achieve with standard event language modeling. To address this, we propose a question-guided generation framework that models events in complex scenarios as answers to questions about participants. At any step in the generation process, the framework uses the previously generated events as context, but generates the next event as an answer to one of three questions: what else a participant did, what else happened to a participant, or what else happened. The participants and the questions themselves can be sampled or be provided as input from a user, allowing for controllable exploration. Our empirical evaluation shows that this question-guided generation provides better coverage of participants, diverse events within a domain, comparable perplexities for modeling event sequences, and more effective control for interactive schema generation.
PASTA: A Dataset for Modeling Participant States in Narratives
Jul 31, 2022
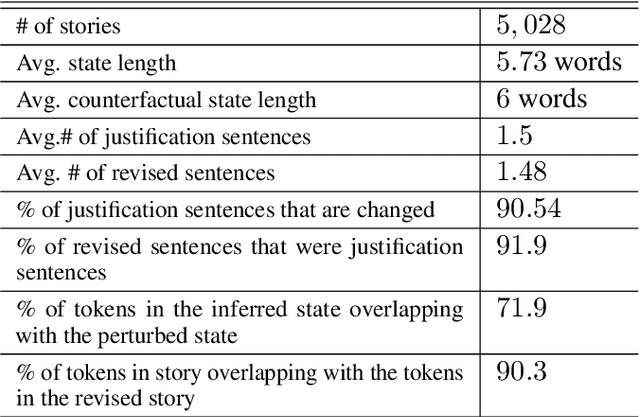
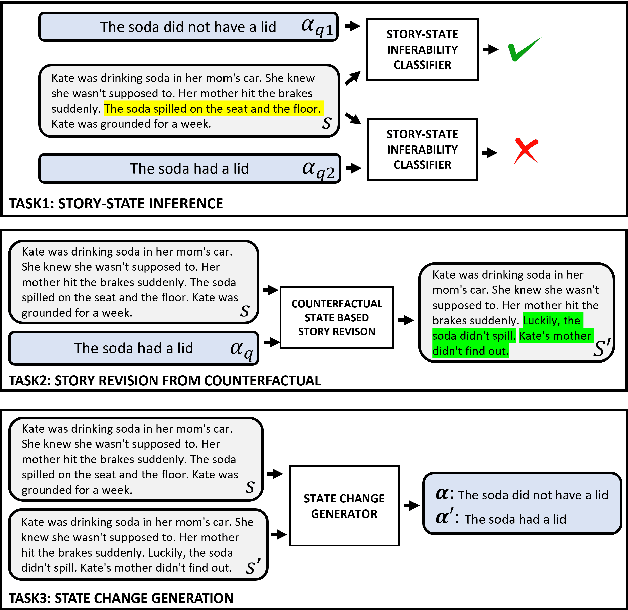
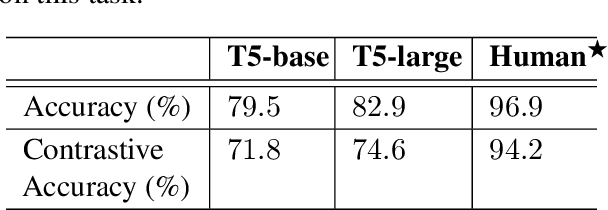
The events in a narrative can be understood as a coherent whole via the underlying states of its participants. Often, these participant states are not explicitly mentioned in the narrative, left to be filled in via common-sense or inference. A model that understands narratives should be able to infer these implicit participant states and reason about the impact of changes to these states on the narrative. To facilitate this goal, we introduce a new crowdsourced Participants States dataset, PASTA. This dataset contains valid, inferable participant states; a counterfactual perturbation to the state; and the changes to the story that would be necessary if the counterfactual was true. We introduce three state-based reasoning tasks that test for the ability to infer when a state is entailed by a story, revise a story for a counterfactual state, and to explain the most likely state change given a revised story. Our benchmarking experiments show that while today's LLMs are able to reason about states to some degree, there is a large room for improvement, suggesting potential avenues for future research.
Author's Sentiment Prediction
Nov 12, 2020

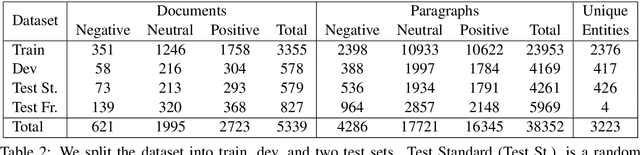
We introduce PerSenT, a dataset of crowd-sourced annotations of the sentiment expressed by the authors towards the main entities in news articles. The dataset also includes paragraph-level sentiment annotations to provide more fine-grained supervision for the task. Our benchmarks of multiple strong baselines show that this is a difficult classification task. The results also suggest that simply fine-tuning document-level representations from BERT isn't adequate for this task. Making paragraph-level decisions and aggregating them over the entire document is also ineffective. We present empirical and qualitative analyses that illustrate the specific challenges posed by this dataset. We release this dataset with 5.3k documents and 38k paragraphs covering 3.2k unique entities as a challenge in entity sentiment analysis.
Modeling Preconditions in Text with a Crowd-sourced Dataset
Oct 14, 2020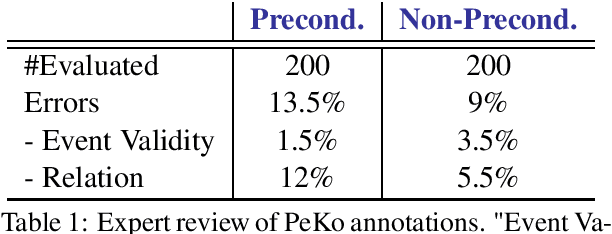

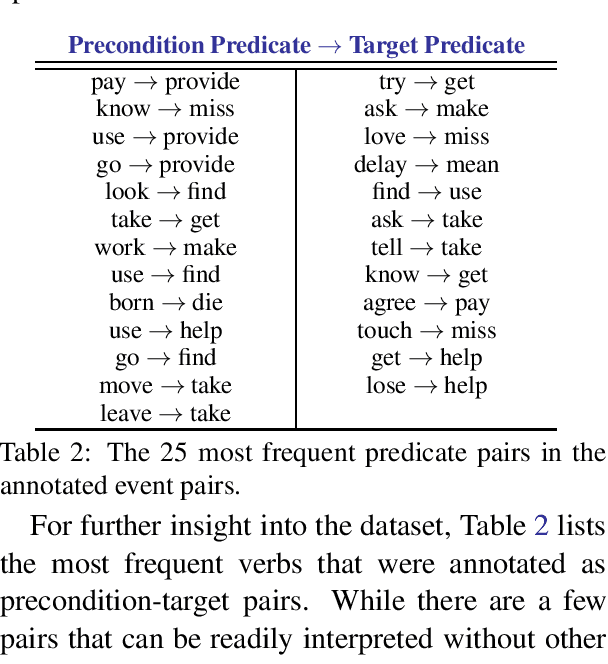
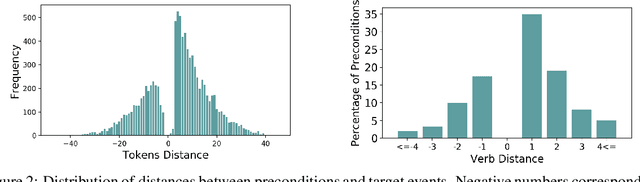
Preconditions provide a form of logical connection between events that explains why some events occur together and information that is complementary to the more widely studied relations such as causation, temporal ordering, entailment, and discourse relations. Modeling preconditions in text has been hampered in part due to the lack of large scale labeled data grounded in text. This paper introduces PeKo, a crowd-sourced annotation of preconditions between event pairs in newswire, an order of magnitude larger than prior text annotations. To complement this new corpus, we also introduce two challenge tasks aimed at modeling preconditions: (i) Precondition Identification -- a standard classification task defined over pairs of event mentions, and (ii) Precondition Generation -- a generative task aimed at testing a more general ability to reason about a given event. Evaluation on both tasks shows that modeling preconditions is challenging even for today's large language models (LM). This suggests that precondition knowledge is not easily accessible in LM-derived representations alone. Our generation results show that fine-tuning an LM on PeKo yields better conditional relations than when trained on raw text or temporally-ordered corpora.
WikiHow: A Large Scale Text Summarization Dataset
Oct 18, 2018


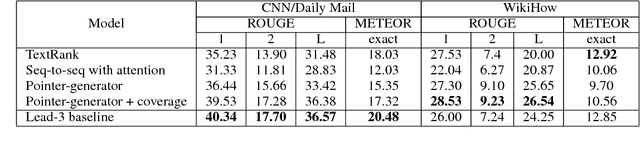
Sequence-to-sequence models have recently gained the state of the art performance in summarization. However, not too many large-scale high-quality datasets are available and almost all the available ones are mainly news articles with specific writing style. Moreover, abstractive human-style systems involving description of the content at a deeper level require data with higher levels of abstraction. In this paper, we present WikiHow, a dataset of more than 230,000 article and summary pairs extracted and constructed from an online knowledge base written by different human authors. The articles span a wide range of topics and therefore represent high diversity styles. We evaluate the performance of the existing methods on WikiHow to present its challenges and set some baselines to further improve it.
Analyzing and Interpreting Convolutional Neural Networks in NLP
Oct 18, 2018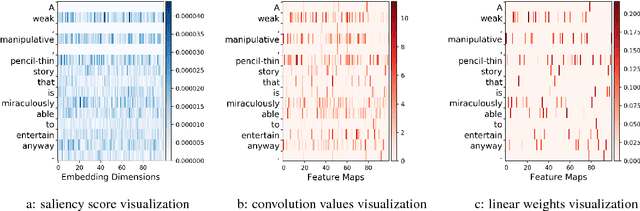


Convolutional neural networks have been successfully applied to various NLP tasks. However, it is not obvious whether they model different linguistic patterns such as negation, intensification, and clause compositionality to help the decision-making process. In this paper, we apply visualization techniques to observe how the model can capture different linguistic features and how these features can affect the performance of the model. Later on, we try to identify the model errors and their sources. We believe that interpreting CNNs is the first step to understand the underlying semantic features which can raise awareness to further improve the performance and explainability of CNN models.