 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Integrated Language Transformers for Next Action Prediction in Complex Phone Calls
Apr 11, 2024



Current Conversational AI systems employ different machine learning pipelines, as well as external knowledge sources and business logic to predict the next action. Maintaining various components in dialogue managers' pipeline adds complexity in expansion and updates, increases processing time, and causes additive noise through the pipeline that can lead to incorrect next action prediction. This paper investigates graph integration into language transformers to improve understanding the relationships between humans' utterances, previous, and next actions without the dependency on external sources or components. Experimental analyses on real calls indicate that the proposed Graph Integrated Language Transformer models can achieve higher performance compared to other production level conversational AI systems in driving interactive calls with human users in real-world settings.
Multimodal Contextual Dialogue Breakdown Detection for Conversational AI Models
Apr 11, 2024Detecting dialogue breakdown in real time is critical for conversational AI systems, because it enables taking corrective action to successfully complete a task. In spoken dialog systems, this breakdown can be caused by a variety of unexpected situations including high levels of background noise, causing STT mistranscriptions, or unexpected user flows. In particular, industry settings like healthcare, require high precision and high flexibility to navigate differently based on the conversation history and dialogue states. This makes it both more challenging and more critical to accurately detect dialog breakdown. To accurately detect breakdown, we found it requires processing audio inputs along with downstream NLP model inferences on transcribed text in real time. In this paper, we introduce a Multimodal Contextual Dialogue Breakdown (MultConDB) model. This model significantly outperforms other known best models by achieving an F1 of 69.27.
Discourse Relation Embeddings: Representing the Relations between Discourse Segments in Social Media
May 04, 2021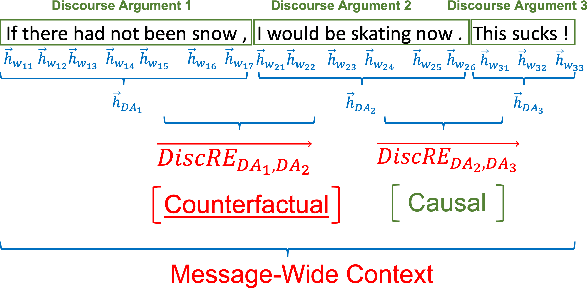
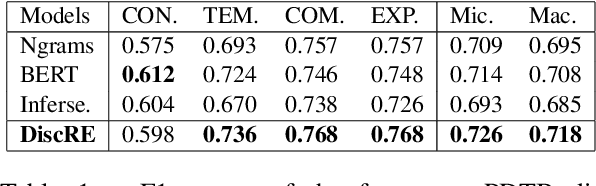
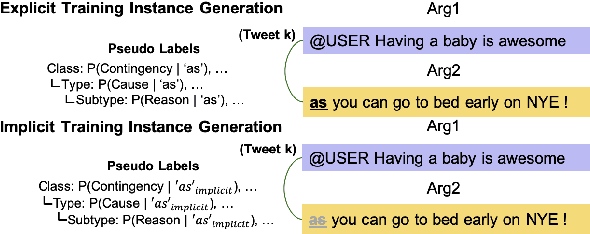
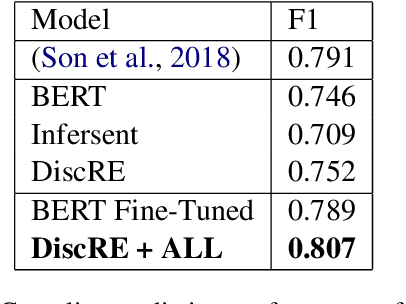
Discourse relations are typically modeled as a discrete class that characterizes the relation between segments of text (e.g. causal explanations, expansions). However, such predefined discrete classes limits the universe of potential relationships and their nuanced differences. Analogous to contextual word embeddings, we propose representing discourse relations as points in high dimensional continuous space. However, unlike words, discourse relations often have no surface form (relations are between two segments, often with no word or phrase in that gap) which presents a challenge for existing embedding techniques. We present a novel method for automatically creating discourse relation embeddings (DiscRE), addressing the embedding challenge through a weakly supervised, multitask approach to learn diverse and nuanced relations between discourse segments in social media. Results show DiscRE can: (1) obtain the best performance on Twitter discourse relation classification task (macro F1=0.76) (2) improve the state of the art in social media causality prediction (from F1=.79 to .81), (3) perform beyond modern sentence and contextual word embeddings at traditional discourse relation classification, and (4) capture novel nuanced relations (e.g. relations semantically at the intersection of causal explanations and counterfactuals).
World Trade Center responders in their own words: Predicting PTSD symptom trajectories with AI-based language analyses of interviews
Nov 12, 2020

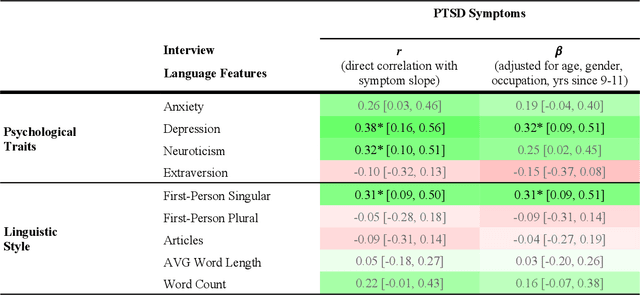

Background: Oral histories from 9/11 responders to the World Trade Center (WTC) attacks provide rich narratives about distress and resilience. Artificial Intelligence (AI) models promise to detect psychopathology in natural language, but they have been evaluated primarily in non-clinical settings using social media. This study sought to test the ability of AI-based language assessments to predict PTSD symptom trajectories among responders. Methods: Participants were 124 responders whose health was monitored at the Stony Brook WTC Health and Wellness Program who completed oral history interviews about their initial WTC experiences. PTSD symptom severity was measured longitudinally using the PTSD Checklist (PCL) for up to 7 years post-interview. AI-based indicators were computed for depression, anxiety, neuroticism, and extraversion along with dictionary-based measures of linguistic and interpersonal style. Linear regression and multilevel models estimated associations of AI indicators with concurrent and subsequent PTSD symptom severity (significance adjusted by false discovery rate). Results: Cross-sectionally, greater depressive language (beta=0.32; p=0.043) and first-person singular usage (beta=0.31; p=0.044) were associated with increased symptom severity. Longitudinally, anxious language predicted future worsening in PCL scores (beta=0.31; p=0.031), whereas first-person plural usage (beta=-0.37; p=0.007) and longer words usage (beta=-0.36; p=0.007) predicted improvement. Conclusions: This is the first study to demonstrate the value of AI in understanding PTSD in a vulnerable population. Future studies should extend this application to other trauma exposures and to other demographic groups, especially under-represented minorities.
Author's Sentiment Prediction
Nov 12, 2020

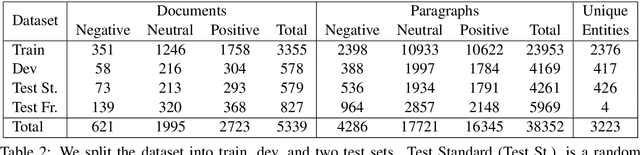
We introduce PerSenT, a dataset of crowd-sourced annotations of the sentiment expressed by the authors towards the main entities in news articles. The dataset also includes paragraph-level sentiment annotations to provide more fine-grained supervision for the task. Our benchmarks of multiple strong baselines show that this is a difficult classification task. The results also suggest that simply fine-tuning document-level representations from BERT isn't adequate for this task. Making paragraph-level decisions and aggregating them over the entire document is also ineffective. We present empirical and qualitative analyses that illustrate the specific challenges posed by this dataset. We release this dataset with 5.3k documents and 38k paragraphs covering 3.2k unique entities as a challenge in entity sentiment analysis.
Causal Explanation Analysis on Social Media
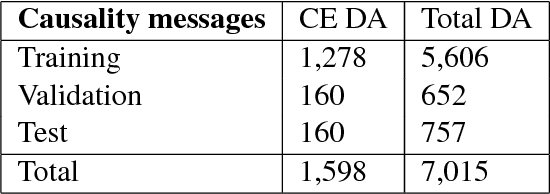
Oct 18, 2018


Understanding causal explanations - reasons given for happenings in one's life - has been found to be an important psychological factor linked to physical and mental health. Causal explanations are often studied through manual identification of phrases over limited samples of personal writing. Automatic identification of causal explanations in social media, while challenging in relying on contextual and sequential cues, offers a larger-scale alternative to expensive manual ratings and opens the door for new applications (e.g. studying prevailing beliefs about causes, such as climate change). Here, we explore automating causal explanation analysis, building on discourse parsing, and presenting two novel subtasks: causality detection (determining whether a causal explanation exists at all) and causal explanation identification (identifying the specific phrase that is the explanation). We achieve strong accuracies for both tasks but find different approaches best: an SVM for causality prediction (F1 = 0.791) and a hierarchy of Bidirectional LSTMs for causal explanation identification (F1 = 0.853). Finally, we explore applications of our complete pipeline (F1 = 0.868), showing demographic differences in mentions of causal explanation and that the association between a word and sentiment can change when it is used within a causal explanation.