 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthor's Sentiment Prediction
Nov 12, 2020

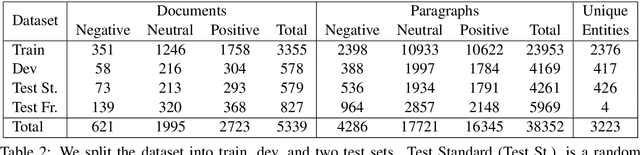
We introduce PerSenT, a dataset of crowd-sourced annotations of the sentiment expressed by the authors towards the main entities in news articles. The dataset also includes paragraph-level sentiment annotations to provide more fine-grained supervision for the task. Our benchmarks of multiple strong baselines show that this is a difficult classification task. The results also suggest that simply fine-tuning document-level representations from BERT isn't adequate for this task. Making paragraph-level decisions and aggregating them over the entire document is also ineffective. We present empirical and qualitative analyses that illustrate the specific challenges posed by this dataset. We release this dataset with 5.3k documents and 38k paragraphs covering 3.2k unique entities as a challenge in entity sentiment analysis.