 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioNLI: Generating a Biomedical NLI Dataset Using Lexico-semantic Constraints for Adversarial Examples
Oct 26, 2022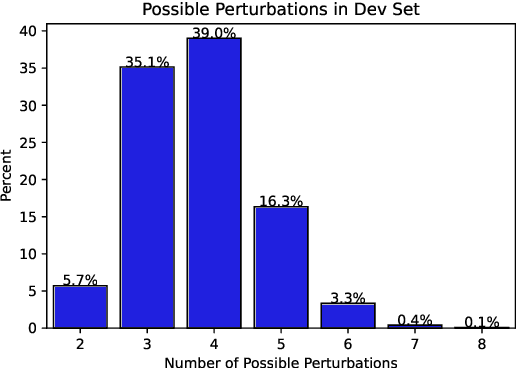
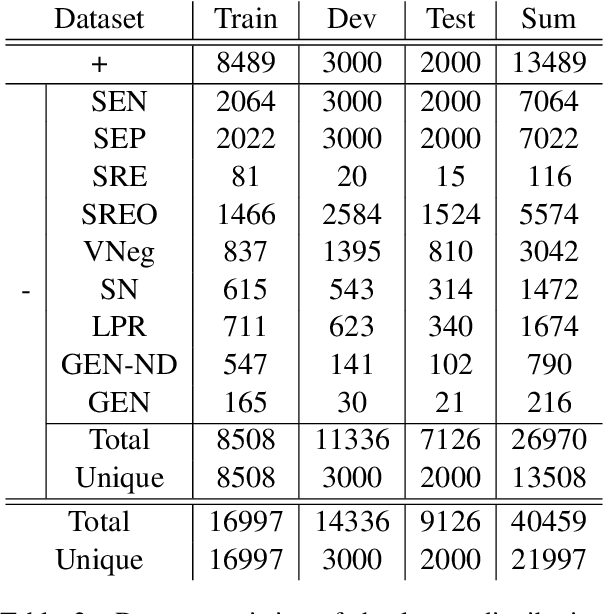
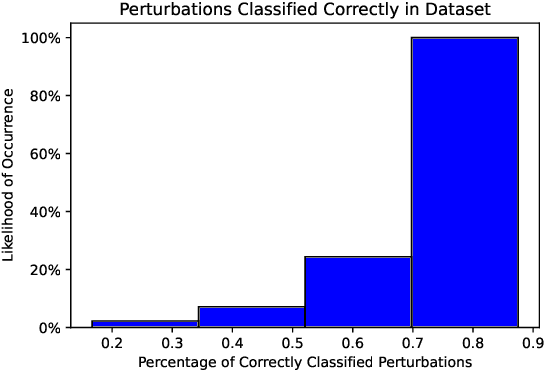
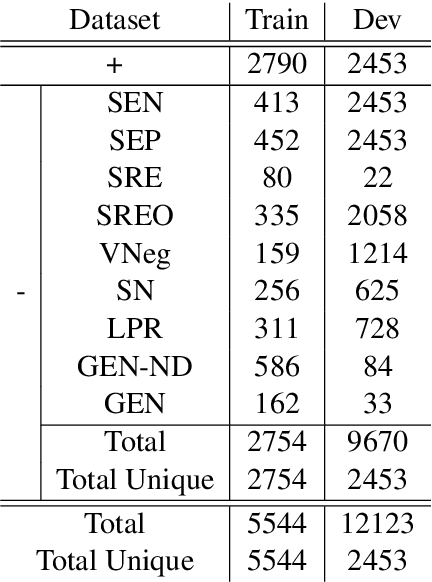
Natural language inference (NLI) is critical for complex decision-making in biomedical domain. One key question, for example, is whether a given biomedical mechanism is supported by experimental evidence. This can be seen as an NLI problem but there are no directly usable datasets to address this. The main challenge is that manually creating informative negative examples for this task is difficult and expensive. We introduce a novel semi-supervised procedure that bootstraps an NLI dataset from existing biomedical dataset that pairs mechanisms with experimental evidence in abstracts. We generate a range of negative examples using nine strategies that manipulate the structure of the underlying mechanisms both with rules, e.g., flip the roles of the entities in the interaction, and, more importantly, as perturbations via logical constraints in a neuro-logical decoding system. We use this procedure to create a novel dataset for NLI in the biomedical domain, called BioNLI and benchmark two state-of-the-art biomedical classifiers. The best result we obtain is around mid 70s in F1, suggesting the difficulty of the task. Critically, the performance on the different classes of negative examples varies widely, from 97% F1 on the simple role change negative examples, to barely better than chance on the negative examples generated using neuro-logic decoding.
SuMe: A Dataset Towards Summarizing Biomedical Mechanisms
May 10, 2022
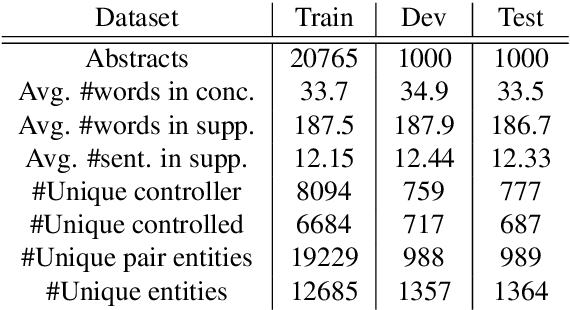


Can language models read biomedical texts and explain the biomedical mechanisms discussed? In this work we introduce a biomedical mechanism summarization task. Biomedical studies often investigate the mechanisms behind how one entity (e.g., a protein or a chemical) affects another in a biological context. The abstracts of these publications often include a focused set of sentences that present relevant supporting statements regarding such relationships, associated experimental evidence, and a concluding sentence that summarizes the mechanism underlying the relationship. We leverage this structure and create a summarization task, where the input is a collection of sentences and the main entities in an abstract, and the output includes the relationship and a sentence that summarizes the mechanism. Using a small amount of manually labeled mechanism sentences, we train a mechanism sentence classifier to filter a large biomedical abstract collection and create a summarization dataset with 22k instances. We also introduce conclusion sentence generation as a pretraining task with 611k instances. We benchmark the performance of large bio-domain language models. We find that while the pretraining task help improves performance, the best model produces acceptable mechanism outputs in only 32% of the instances, which shows the task presents significant challenges in biomedical language understanding and summarization.
A Preordered RNN Layer Boosts Neural Machine Translation in Low Resource Settings
Dec 28, 2021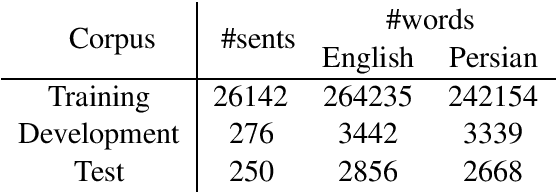

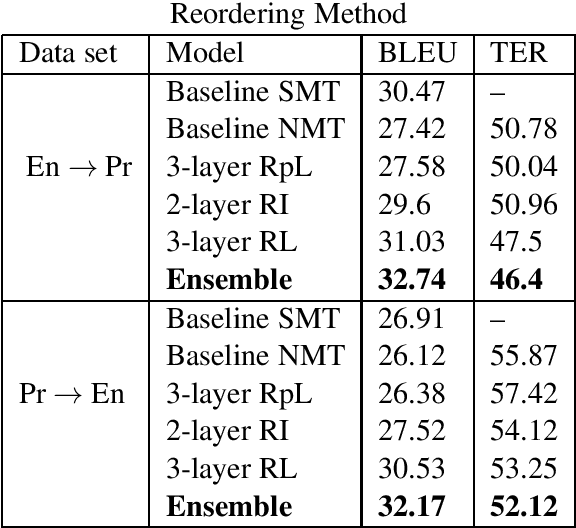
Neural Machine Translation (NMT) models are strong enough to convey semantic and syntactic information from the source language to the target language. However, these models are suffering from the need for a large amount of data to learn the parameters. As a result, for languages with scarce data, these models are at risk of underperforming. We propose to augment attention based neural network with reordering information to alleviate the lack of data. This augmentation improves the translation quality for both English to Persian and Persian to English by up to 6% BLEU absolute over the baseline models.
Author's Sentiment Prediction
Nov 12, 2020

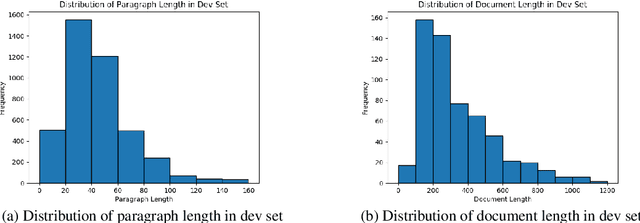
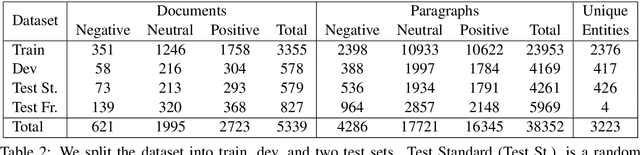
We introduce PerSenT, a dataset of crowd-sourced annotations of the sentiment expressed by the authors towards the main entities in news articles. The dataset also includes paragraph-level sentiment annotations to provide more fine-grained supervision for the task. Our benchmarks of multiple strong baselines show that this is a difficult classification task. The results also suggest that simply fine-tuning document-level representations from BERT isn't adequate for this task. Making paragraph-level decisions and aggregating them over the entire document is also ineffective. We present empirical and qualitative analyses that illustrate the specific challenges posed by this dataset. We release this dataset with 5.3k documents and 38k paragraphs covering 3.2k unique entities as a challenge in entity sentiment analysis.
Modeling Label Semantics for Predicting Emotional Reactions
Jun 28, 2020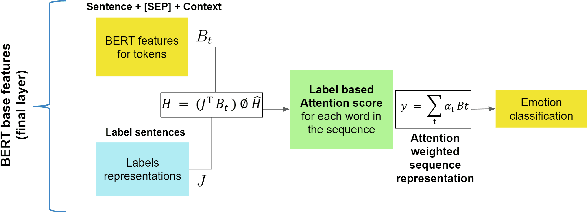
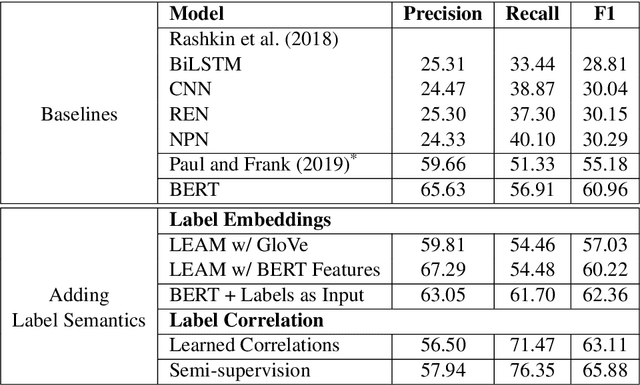
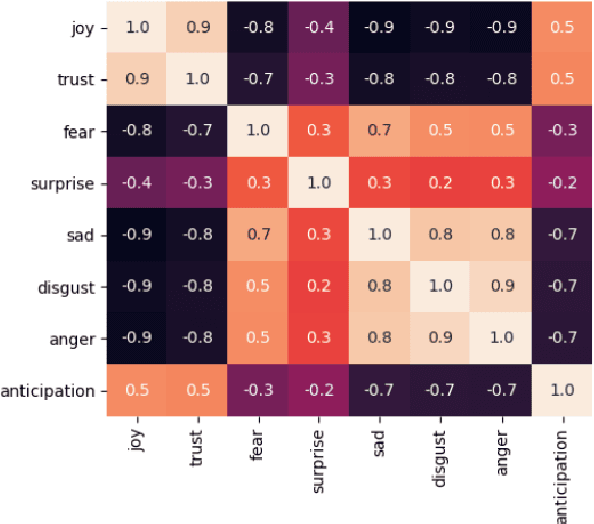
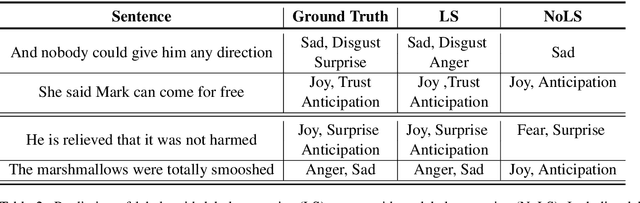
Predicting how events induce emotions in the characters of a story is typically seen as a standard multi-label classification task, which usually treats labels as anonymous classes to predict. They ignore information that may be conveyed by the emotion labels themselves. We propose that the semantics of emotion labels can guide a model's attention when representing the input story. Further, we observe that the emotions evoked by an event are often related: an event that evokes joy is unlikely to also evoke sadness. In this work, we explicitly model label classes via label embeddings, and add mechanisms that track label-label correlations both during training and inference. We also introduce a new semi-supervision strategy that regularizes for the correlations on unlabeled data. Our empirical evaluations show that modeling label semantics yields consistent benefits, and we advance the state-of-the-art on an emotion inference task.
Neural Machine Translation on Scarce-Resource Condition: A case-study on Persian-English
Jan 07, 2017
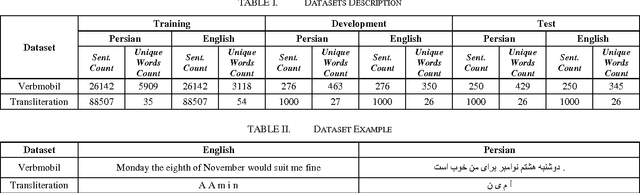
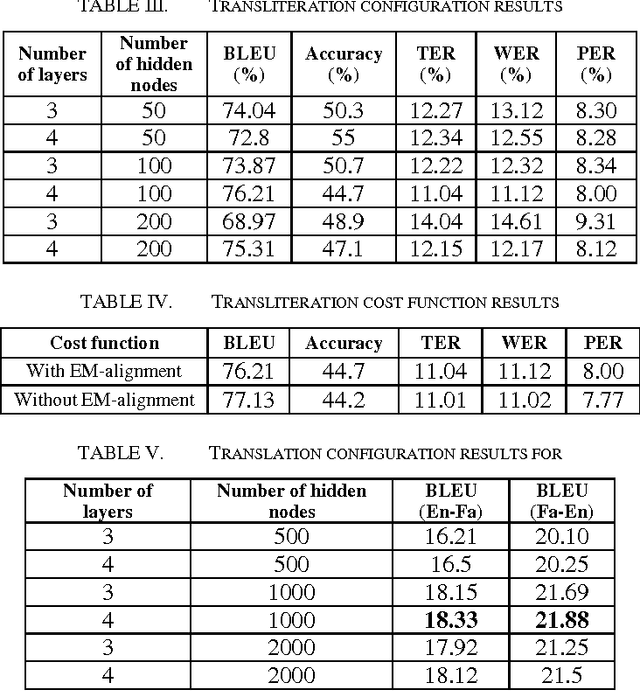
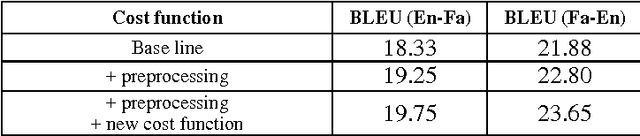
Neural Machine Translation (NMT) is a new approach for Machine Translation (MT), and due to its success, it has absorbed the attention of many researchers in the field. In this paper, we study NMT model on Persian-English language pairs, to analyze the model and investigate the appropriateness of the model for scarce-resourced scenarios, the situation that exists for Persian-centered translation systems. We adjust the model for the Persian language and find the best parameters and hyper parameters for two tasks: translation and transliteration. We also apply some preprocessing task on the Persian dataset which yields to increase for about one point in terms of BLEU score. Also, we have modified the loss function to enhance the word alignment of the model. This new loss function yields a total of 1.87 point improvements in terms of BLEU score in the translation quality.