 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Regularized Adversarial Training using Layers Sustainability Analysis (LSA) framework
Feb 15, 2022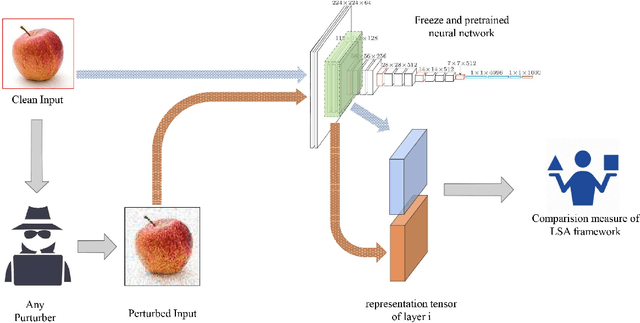


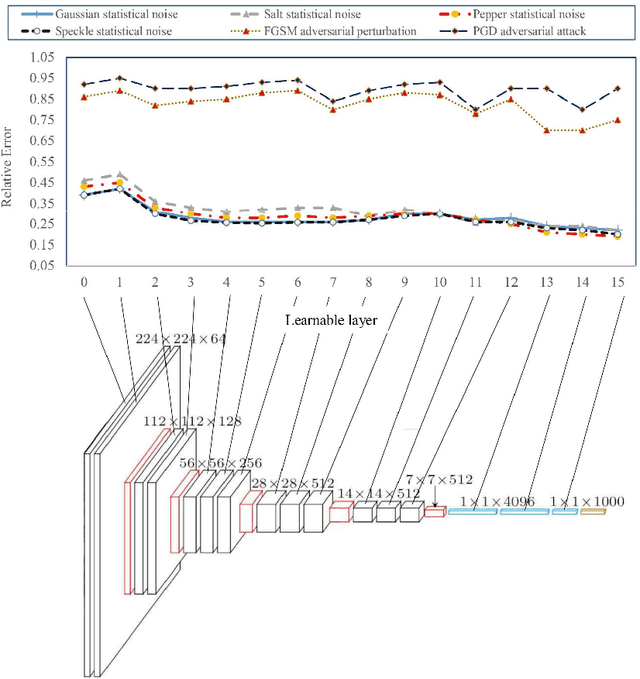
Deep neural network models are used today in various applications of artificial intelligence, the strengthening of which, in the face of adversarial attacks is of particular importance. An appropriate solution to adversarial attacks is adversarial training, which reaches a trade-off between robustness and generalization. This paper introduces a novel framework (Layer Sustainability Analysis (LSA)) for the analysis of layer vulnerability in an arbitrary neural network in the scenario of adversarial attacks. LSA can be a helpful toolkit to assess deep neural networks and to extend the adversarial training approaches towards improving the sustainability of model layers via layer monitoring and analysis. The LSA framework identifies a list of Most Vulnerable Layers (MVL list) of the given network. The relative error, as a comparison measure, is used to evaluate representation sustainability of each layer against adversarial inputs. The proposed approach for obtaining robust neural networks to fend off adversarial attacks is based on a layer-wise regularization (LR) over LSA proposal(s) for adversarial training (AT); i.e. the AT-LR procedure. AT-LR could be used with any benchmark adversarial attack to reduce the vulnerability of network layers and to improve conventional adversarial training approaches. The proposed idea performs well theoretically and experimentally for state-of-the-art multilayer perceptron and convolutional neural network architectures. Compared with the AT-LR and its corresponding base adversarial training, the classification accuracy of more significant perturbations increased by 16.35%, 21.79%, and 10.730% on Moon, MNIST, and CIFAR-10 benchmark datasets, respectively. The LSA framework is available and published at https://github.com/khalooei/LSA.
Efficient Attention Branch Network with Combined Loss Function for Automatic Speaker Verification Spoof Detection
Sep 19, 2021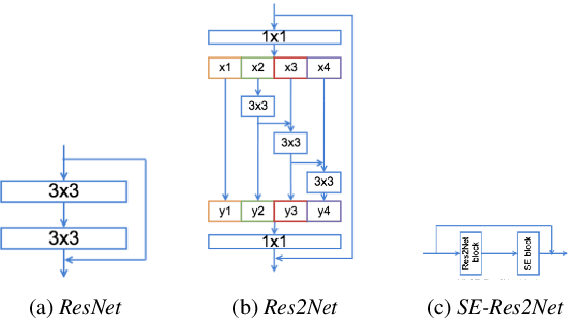
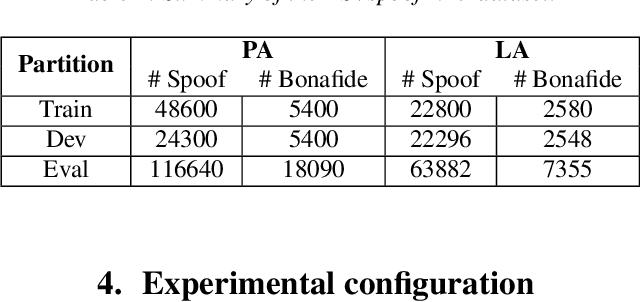
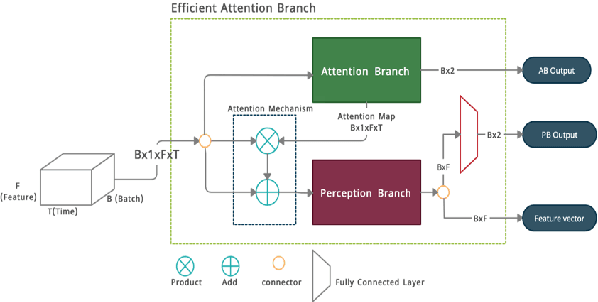

Many endeavors have sought to develop countermeasure techniques as enhancements on Automatic Speaker Verification (ASV) systems, in order to make them more robust against spoof attacks. As evidenced by the latest ASVspoof 2019 countermeasure challenge, models currently deployed for the task of ASV are, at their best, devoid of suitable degrees of generalization to unseen attacks. Upon further investigation of the proposed methods, it appears that a broader three-tiered view of the proposed systems. comprised of the classifier, feature extraction phase, and model loss function, may to some extent lessen the problem. Accordingly, the present study proposes the Efficient Attention Branch Network (EABN) modular architecture with a combined loss function to address the generalization problem...
Neural Machine Translation on Scarce-Resource Condition: A case-study on Persian-English
Jan 07, 2017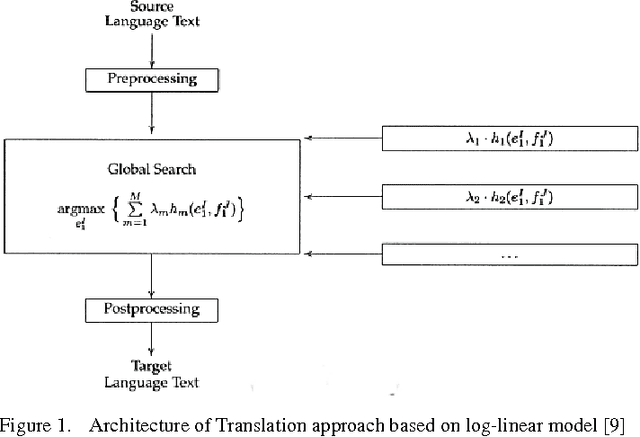
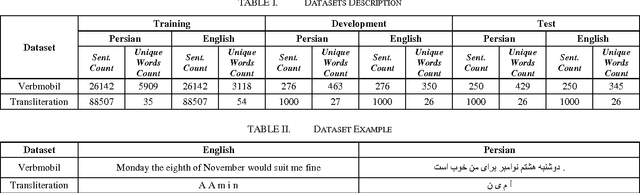
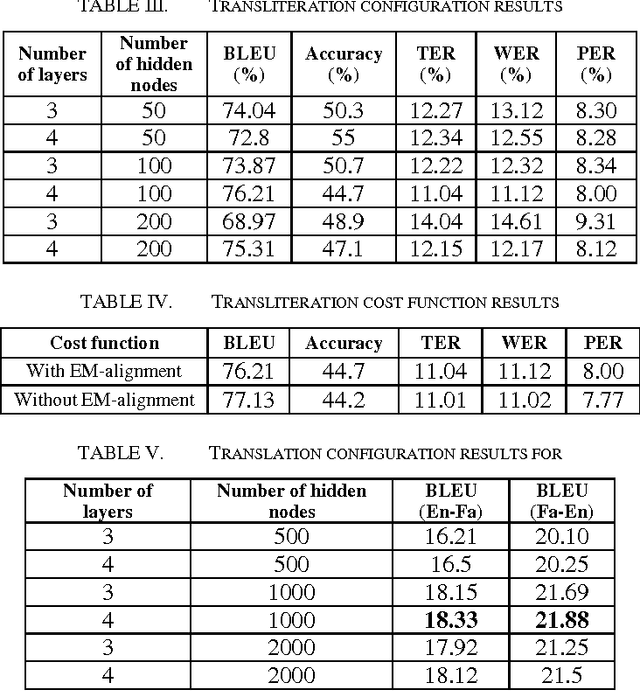
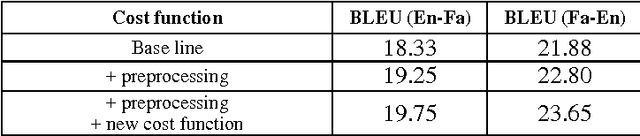
Neural Machine Translation (NMT) is a new approach for Machine Translation (MT), and due to its success, it has absorbed the attention of many researchers in the field. In this paper, we study NMT model on Persian-English language pairs, to analyze the model and investigate the appropriateness of the model for scarce-resourced scenarios, the situation that exists for Persian-centered translation systems. We adjust the model for the Persian language and find the best parameters and hyper parameters for two tasks: translation and transliteration. We also apply some preprocessing task on the Persian dataset which yields to increase for about one point in terms of BLEU score. Also, we have modified the loss function to enhance the word alignment of the model. This new loss function yields a total of 1.87 point improvements in terms of BLEU score in the translation quality.
Modeling State-Conditional Observation Distribution using Weighted Stereo Samples for Factorial Speech Processing Models
Oct 05, 2016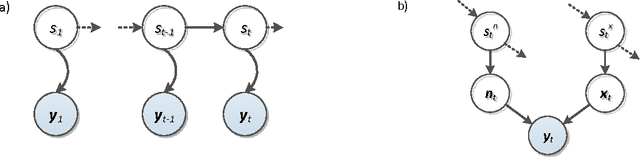

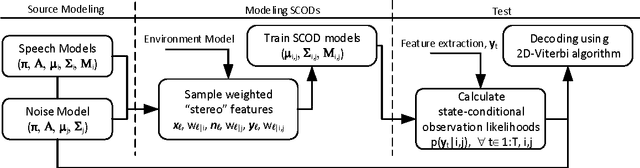
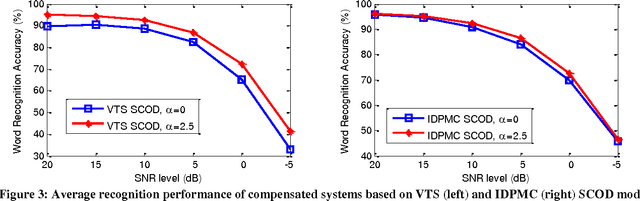
This paper investigates the effectiveness of factorial speech processing models in noise-robust automatic speech recognition tasks. For this purpose, the paper proposes an idealistic approach for modeling state-conditional observation distribution of factorial models based on weighted stereo samples. This approach is an extension to previous single pass retraining for ideal model compensation which is extended here to support multiple audio sources. Non-stationary noises can be considered as one of these audio sources with multiple states. Experiments of this paper over the set A of the Aurora 2 dataset show that recognition performance can be improved by this consideration. The improvement is significant in low signal to noise energy conditions, up to 4% absolute word recognition accuracy. In addition to the power of the proposed method in accurate representation of state-conditional observation distribution, it has an important advantage over previous methods by providing the opportunity to independently select feature spaces for both source and corrupted features. This opens a new window for seeking better feature spaces appropriate for noisy speech, independent from clean speech features.
Monaural Multi-Talker Speech Recognition using Factorial Speech Processing Models
Oct 05, 2016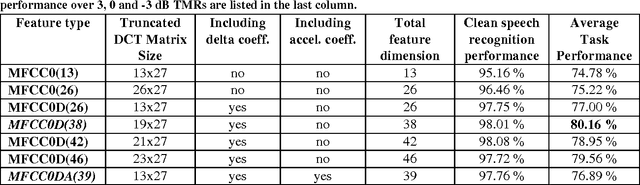
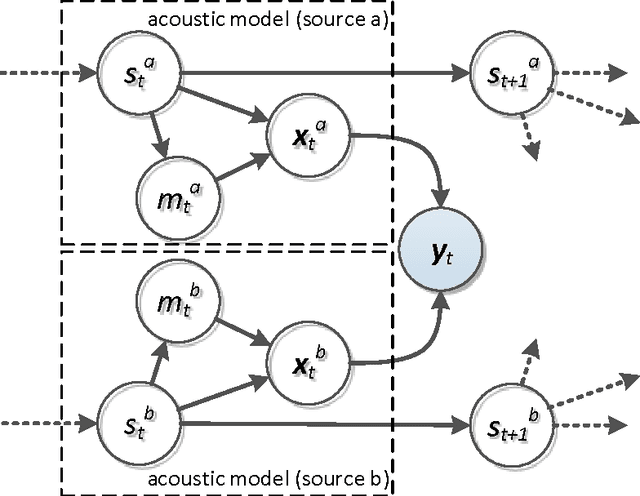

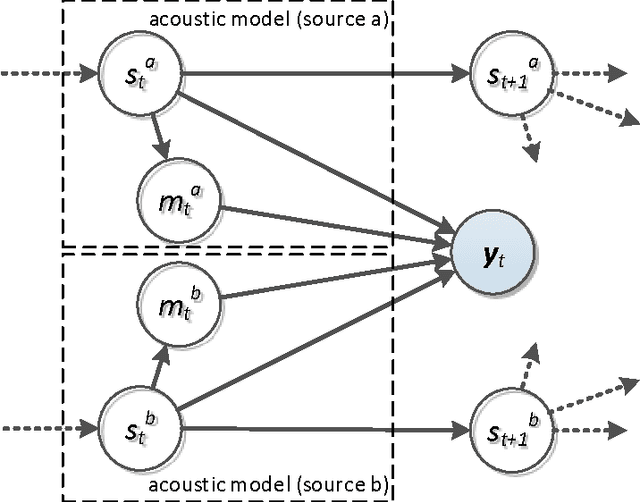
A Pascal challenge entitled monaural multi-talker speech recognition was developed, targeting the problem of robust automatic speech recognition against speech like noises which significantly degrades the performance of automatic speech recognition systems. In this challenge, two competing speakers say a simple command simultaneously and the objective is to recognize speech of the target speaker. Surprisingly during the challenge, a team from IBM research, could achieve a performance better than human listeners on this task. The proposed method of the IBM team, consist of an intermediate speech separation and then a single-talker speech recognition. This paper reconsiders the task of this challenge based on gain adapted factorial speech processing models. It develops a joint-token passing algorithm for direct utterance decoding of both target and masker speakers, simultaneously. Comparing it to the challenge winner, it uses maximum uncertainty during the decoding which cannot be used in the past two-phased method. It provides detailed derivation of inference on these models based on general inference procedures of probabilistic graphical models. As another improvement, it uses deep neural networks for joint-speaker identification and gain estimation which makes these two steps easier than before producing competitive results for these steps. The proposed method of this work outperforms past super-human results and even the results were achieved recently by Microsoft research, using deep neural networks. It achieved 5.5% absolute task performance improvement compared to the first super-human system and 2.7% absolute task performance improvement compared to its recent competitor.
A brief survey on deep belief networks and introducing a new object oriented toolbox
Jan 06, 2016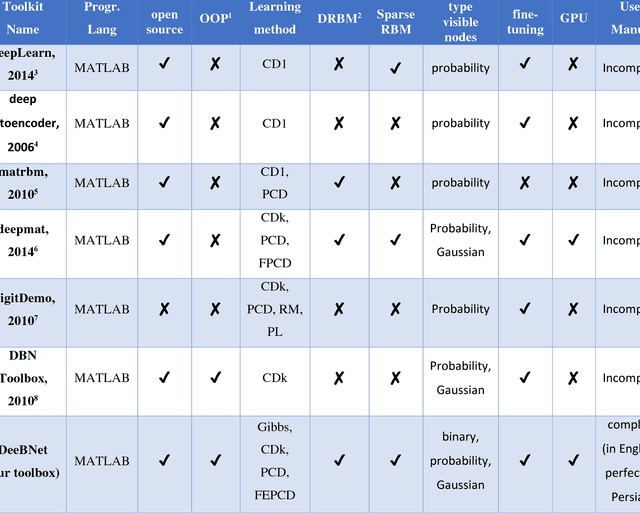
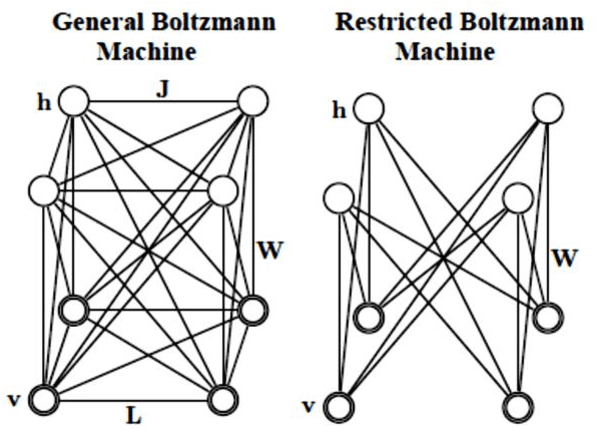
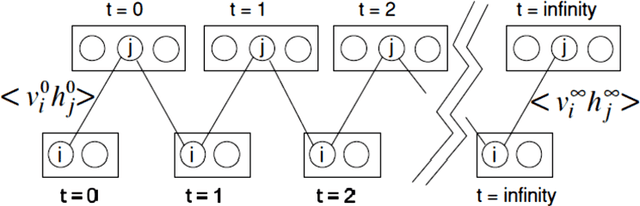
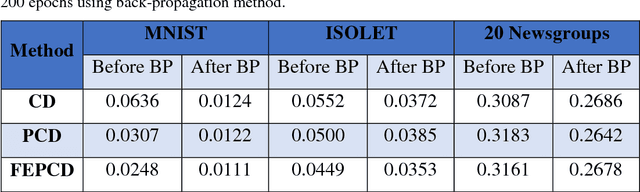
Nowadays, this is very popular to use the deep architectures in machine learning. Deep Belief Networks (DBNs) are deep architectures that use stack of Restricted Boltzmann Machines (RBM) to create a powerful generative model using training data. DBNs have many ability like feature extraction and classification that are used in many applications like image processing, speech processing and etc. This paper introduces a new object oriented MATLAB toolbox with most of abilities needed for the implementation of DBNs. In the new version, the toolbox can be used in Octave. According to the results of the experiments conducted on MNIST (image), ISOLET (speech), and 20 Newsgroups (text) datasets, it was shown that the toolbox can learn automatically a good representation of the input from unlabeled data with better discrimination between different classes. Also on all datasets, the obtained classification errors are comparable to those of state of the art classifiers. In addition, the toolbox supports different sampling methods (e.g. Gibbs, CD, PCD and our new FEPCD method), different sparsity methods (quadratic, rate distortion and our new normal method), different RBM types (generative and discriminative), using GPU, etc. The toolbox is a user-friendly open source software and is freely available on the website http://ceit.aut.ac.ir/~keyvanrad/DeeBNet%20Toolbox.html .
Deep Belief Network Training Improvement Using Elite Samples Minimizing Free Energy
Nov 14, 2014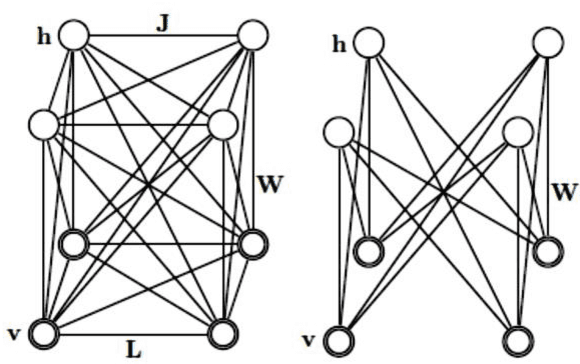
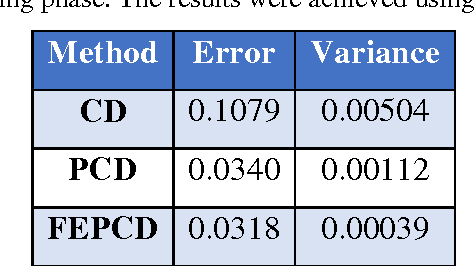
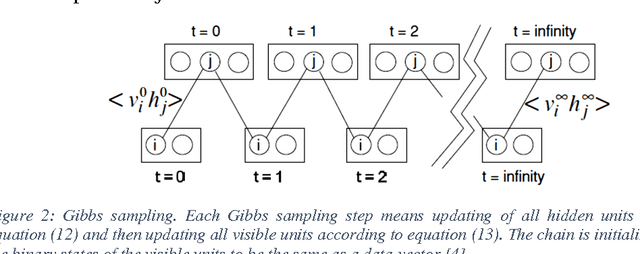
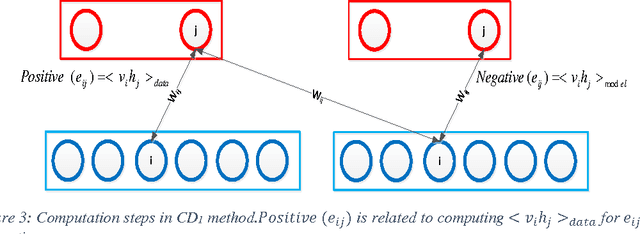
Nowadays this is very popular to use deep architectures in machine learning. Deep Belief Networks (DBNs) are deep architectures that use stack of Restricted Boltzmann Machines (RBM) to create a powerful generative model using training data. In this paper we present an improvement in a common method that is usually used in training of RBMs. The new method uses free energy as a criterion to obtain elite samples from generative model. We argue that these samples can more accurately compute gradient of log probability of training data. According to the results, an error rate of 0.99% was achieved on MNIST test set. This result shows that the proposed method outperforms the method presented in the first paper introducing DBN (1.25% error rate) and general classification methods such as SVM (1.4% error rate) and KNN (with 1.6% error rate). In another test using ISOLET dataset, letter classification error dropped to 3.59% compared to 5.59% error rate achieved in those papers using this dataset. The implemented method is available online at "http://ceit.aut.ac.ir/~keyvanrad/DeeBNet Toolbox.html".
* 18 pages. arXiv admin note: substantial text overlap with arXiv:1408.3264