 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Emotion Recognition: Leveraging Self-Supervised Models for Feature Extraction Using Wav2Vec2 and HuBERT
Nov 05, 2024



Speech is the most natural way of expressing ourselves as humans. Identifying emotion from speech is a nontrivial task due to the ambiguous definition of emotion itself. Speaker Emotion Recognition (SER) is essential for understanding human emotional behavior. The SER task is challenging due to the variety of speakers, background noise, complexity of emotions, and speaking styles. It has many applications in education, healthcare, customer service, and Human-Computer Interaction (HCI). Previously, conventional machine learning methods such as SVM, HMM, and KNN have been used for the SER task. In recent years, deep learning methods have become popular, with convolutional neural networks and recurrent neural networks being used for SER tasks. The input of these methods is mostly spectrograms and hand-crafted features. In this work, we study the use of self-supervised transformer-based models, Wav2Vec2 and HuBERT, to determine the emotion of speakers from their voice. The models automatically extract features from raw audio signals, which are then used for the classification task. The proposed solution is evaluated on reputable datasets, including RAVDESS, SHEMO, SAVEE, AESDD, and Emo-DB. The results show the effectiveness of the proposed method on different datasets. Moreover, the model has been used for real-world applications like call center conversations, and the results demonstrate that the model accurately predicts emotions.
Efficient Attention Branch Network with Combined Loss Function for Automatic Speaker Verification Spoof Detection
Sep 19, 2021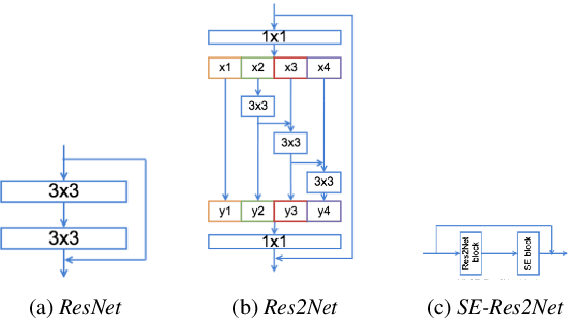
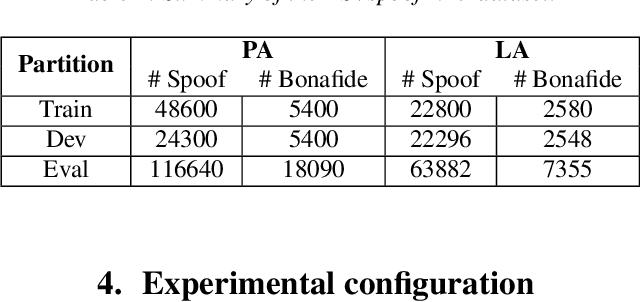
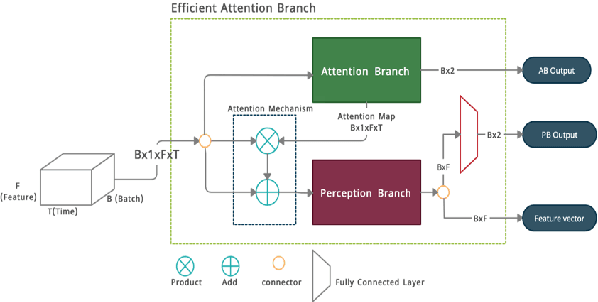

Many endeavors have sought to develop countermeasure techniques as enhancements on Automatic Speaker Verification (ASV) systems, in order to make them more robust against spoof attacks. As evidenced by the latest ASVspoof 2019 countermeasure challenge, models currently deployed for the task of ASV are, at their best, devoid of suitable degrees of generalization to unseen attacks. Upon further investigation of the proposed methods, it appears that a broader three-tiered view of the proposed systems. comprised of the classifier, feature extraction phase, and model loss function, may to some extent lessen the problem. Accordingly, the present study proposes the Efficient Attention Branch Network (EABN) modular architecture with a combined loss function to address the generalization problem...
EfficientNet-Absolute Zero for Continuous Speech Keyword Spotting
Dec 31, 2020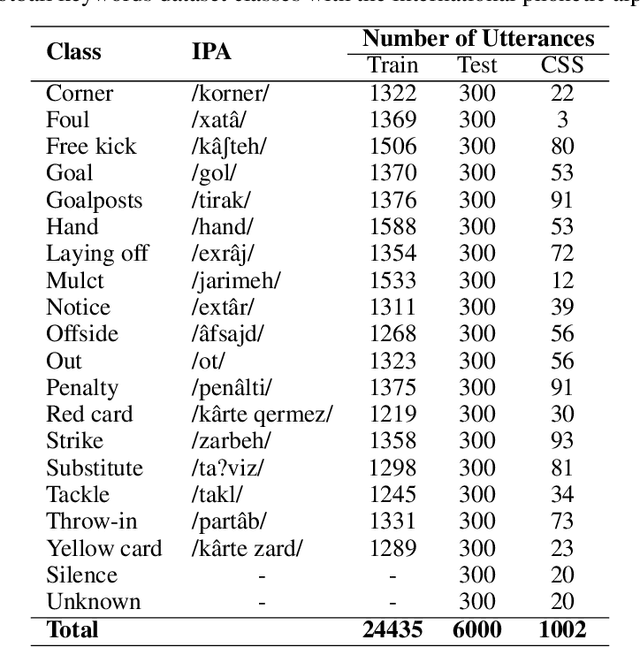
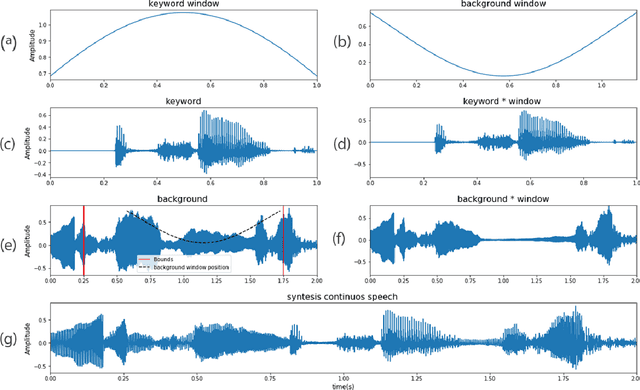
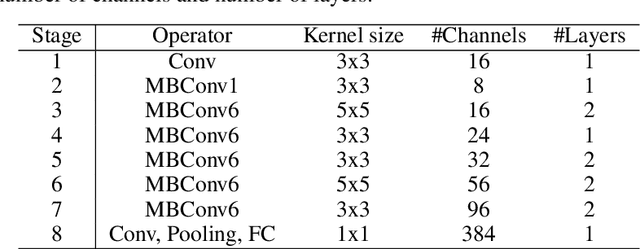
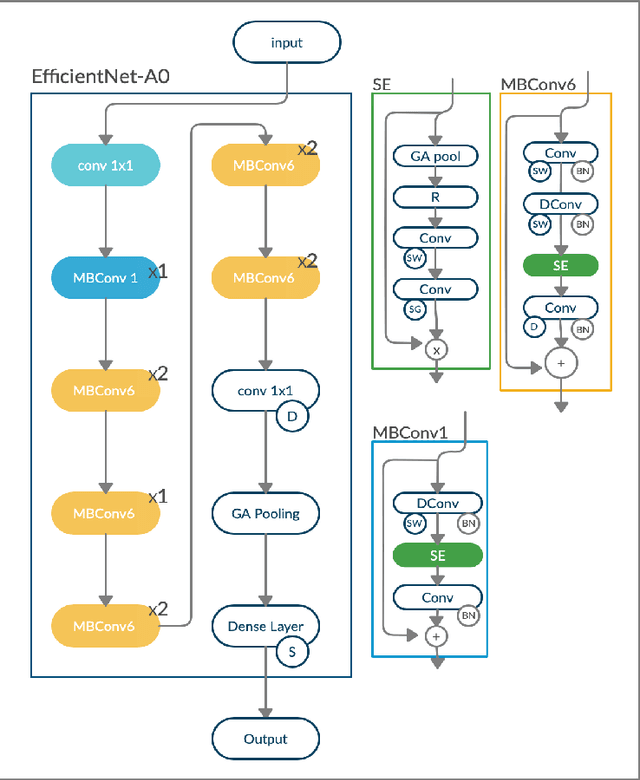
Keyword spotting is a process of finding some specific words or phrases in recorded speeches by computers. Deep neural network algorithms, as a powerful engine, can handle this problem if they are trained over an appropriate dataset. To this end, the football keyword dataset (FKD), as a new keyword spotting dataset in Persian, is collected with crowdsourcing. This dataset contains nearly 31000 samples in 18 classes. The continuous speech synthesis method proposed to made FKD usable in the practical application which works with continuous speeches. Besides, we proposed a lightweight architecture called EfficientNet-A0 (absolute zero) by applying the compound scaling method on EfficientNet-B0 for keyword spotting task. Finally, the proposed architecture is evaluated with various models. It is realized that EfficientNet-A0 and Resnet models outperform other models on this dataset.