 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCached Adaptive Token Merging: Dynamic Token Reduction and Redundant Computation Elimination in Diffusion Model
Jan 01, 2025

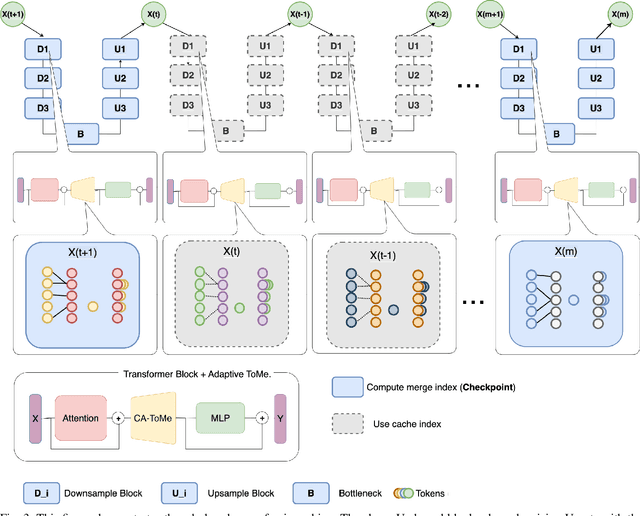
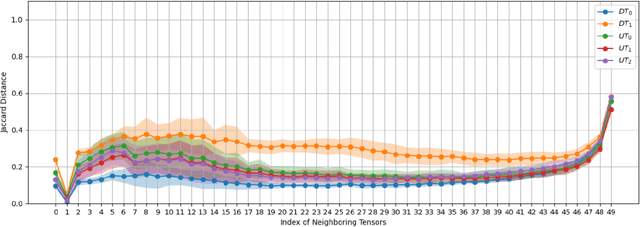
Diffusion models have emerged as a promising approach for generating high-quality, high-dimensional images. Nevertheless, these models are hindered by their high computational cost and slow inference, partly due to the quadratic computational complexity of the self-attention mechanisms with respect to input size. Various approaches have been proposed to address this drawback. One such approach focuses on reducing the number of tokens fed into the self-attention, known as token merging (ToMe). In our method, which is called cached adaptive token merging(CA-ToMe), we calculate the similarity between tokens and then merge the r proportion of the most similar tokens. However, due to the repetitive patterns observed in adjacent steps and the variation in the frequency of similarities, we aim to enhance this approach by implementing an adaptive threshold for merging tokens and adding a caching mechanism that stores similar pairs across several adjacent steps. Empirical results demonstrate that our method operates as a training-free acceleration method, achieving a speedup factor of 1.24 in the denoising process while maintaining the same FID scores compared to existing approaches.
Amirkabir campus dataset: Real-world challenges and scenarios of Visual Inertial Odometry (VIO) for visually impaired people
Jan 07, 2024Visual Inertial Odometry (VIO) algorithms estimate the accurate camera trajectory by using camera and Inertial Measurement Unit (IMU) sensors. The applications of VIO span a diverse range, including augmented reality and indoor navigation. VIO algorithms hold the potential to facilitate navigation for visually impaired individuals in both indoor and outdoor settings. Nevertheless, state-of-the-art VIO algorithms encounter substantial challenges in dynamic environments, particularly in densely populated corridors. Existing VIO datasets, e.g., ADVIO, typically fail to effectively exploit these challenges. In this paper, we introduce the Amirkabir campus dataset (AUT-VI) to address the mentioned problem and improve the navigation systems. AUT-VI is a novel and super-challenging dataset with 126 diverse sequences in 17 different locations. This dataset contains dynamic objects, challenging loop-closure/map-reuse, different lighting conditions, reflections, and sudden camera movements to cover all extreme navigation scenarios. Moreover, in support of ongoing development efforts, we have released the Android application for data capture to the public. This allows fellow researchers to easily capture their customized VIO dataset variations. In addition, we evaluate state-of-the-art Visual Inertial Odometry (VIO) and Visual Odometry (VO) methods on our dataset, emphasizing the essential need for this challenging dataset.
Identity-preserving Editing of Multiple Facial Attributes by Learning Global Edit Directions and Local Adjustments
Sep 25, 2023



Semantic facial attribute editing using pre-trained Generative Adversarial Networks (GANs) has attracted a great deal of attention and effort from researchers in recent years. Due to the high quality of face images generated by StyleGANs, much work has focused on the StyleGANs' latent space and the proposed methods for facial image editing. Although these methods have achieved satisfying results for manipulating user-intended attributes, they have not fulfilled the goal of preserving the identity, which is an important challenge. We present ID-Style, a new architecture capable of addressing the problem of identity loss during attribute manipulation. The key components of ID-Style include Learnable Global Direction (LGD), which finds a shared and semi-sparse direction for each attribute, and an Instance-Aware Intensity Predictor (IAIP) network, which finetunes the global direction according to the input instance. Furthermore, we introduce two losses during training to enforce the LGD to find semi-sparse semantic directions, which along with the IAIP, preserve the identity of the input instance. Despite reducing the size of the network by roughly 95% as compared to similar state-of-the-art works, it outperforms baselines by 10% and 7% in Identity preserving metric (FRS) and average accuracy of manipulation (mACC), respectively.
Enhancing Landmark Detection in Cluttered Real-World Scenarios with Vision Transformers
Aug 25, 2023
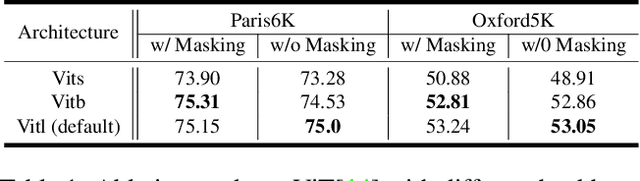
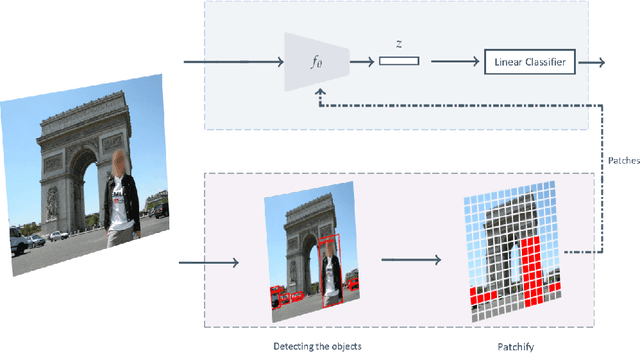

Visual place recognition tasks often encounter significant challenges in landmark detection due to the presence of irrelevant objects such as humans, cars, and trees, despite the remarkable progress achieved by previous models, especially in the context of transformers. To address this issue, we propose a novel method that effectively leverages the strengths of vision transformers. By employing a meticulous selection process, our approach identifies and isolates specific patches within the image that correspond to occluding objects. To evaluate the efficacy of our method, we created augmented datasets and conducted comprehensive testing. The results demonstrate the superior accuracy achieved by our proposed approach. This research contributes to the advancement of landmark detection in visual place recognition and shows the potential of leveraging vision transformers to overcome challenges posed by cluttered real-world scenarios.
A comprehensive survey on semantic facial attribute editing using generative adversarial networks
May 21, 2022
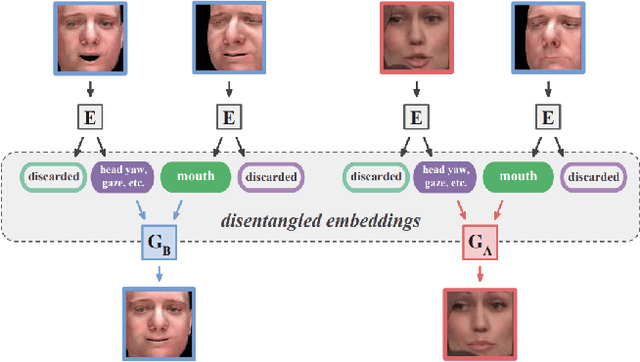
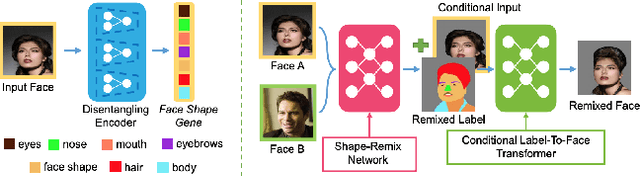
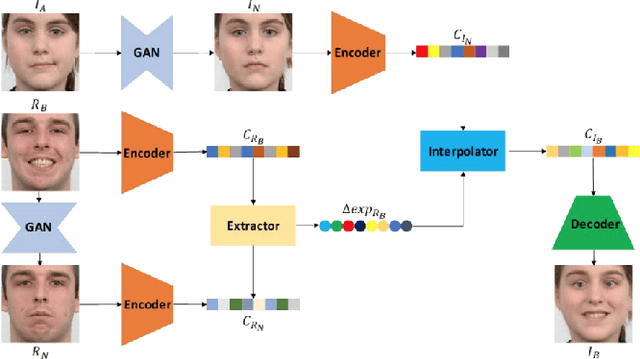
Generating random photo-realistic images has experienced tremendous growth during the past few years due to the advances of the deep convolutional neural networks and generative models. Among different domains, face photos have received a great deal of attention and a large number of face generation and manipulation models have been proposed. Semantic facial attribute editing is the process of varying the values of one or more attributes of a face image while the other attributes of the image are not affected. The requested modifications are provided as an attribute vector or in the form of driving face image and the whole process is performed by the corresponding models. In this paper, we survey the recent works and advances in semantic facial attribute editing. We cover all related aspects of these models including the related definitions and concepts, architectures, loss functions, datasets, evaluation metrics, and applications. Based on their architectures, the state-of-the-art models are categorized and studied as encoder-decoder, image-to-image, and photo-guided models. The challenges and restrictions of the current state-of-the-art methods are discussed as well.
SRVIO: Super Robust Visual Inertial Odometry for dynamic environments and challenging Loop-closure conditions
Jan 14, 2022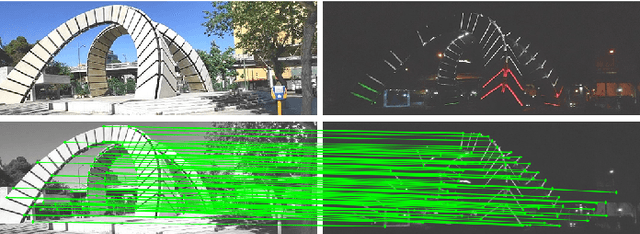
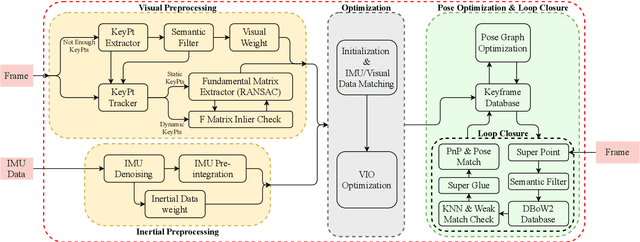

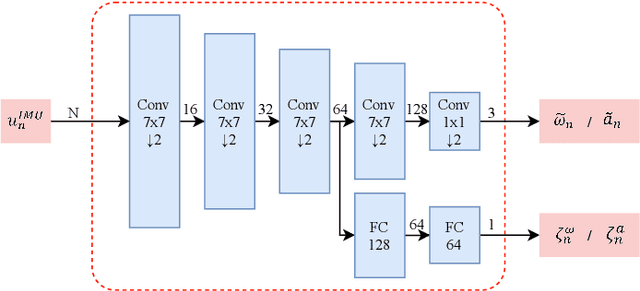
The visual localization or odometry problem is a well-known challenge in the field of autonomous robots and cars. Traditionally, this problem can ba tackled with the help of expensive sensors such as lidars. Nowadays, the leading research is on robust localization using economic sensors, such as cameras and IMUs. The geometric methods based on these sensors are pretty good in normal conditions withstable lighting and no dynamic objects. These methods suffer from significant loss and divergence in such challenging environments. The scientists came to use deep neural networks (DNNs) as the savior to mitigate this problem. The main idea behind using DNNs was to better understand the problem inside the data and overcome complex conditions (such as a dynamic object in front of the camera, extreme lighting conditions, keeping the track at high speeds, etc.) The prior endto-end DNN methods are able to overcome some of the mentioned challenges. However, no general and robust framework for all of these scenarios is available. In this paper, we have combined geometric and DNN based methods to have the pros of geometric SLAM frameworks and overcome the remaining challenges with the DNNs help. To do this, we have modified the Vins-Mono framework (the most robust and accurate framework till now) and we were able to achieve state-of-the-art results on TUM-Dynamic, TUM-VI, ADVIO and EuRoC datasets compared to geometric and end-to-end DNN based SLAMs. Our proposed framework was also able to achieve acceptable results on extreme simulated cases resembling the challenges mentioned earlier easy.
GMFIM: A Generative Mask-guided Facial Image Manipulation Model for Privacy Preservation
Jan 10, 2022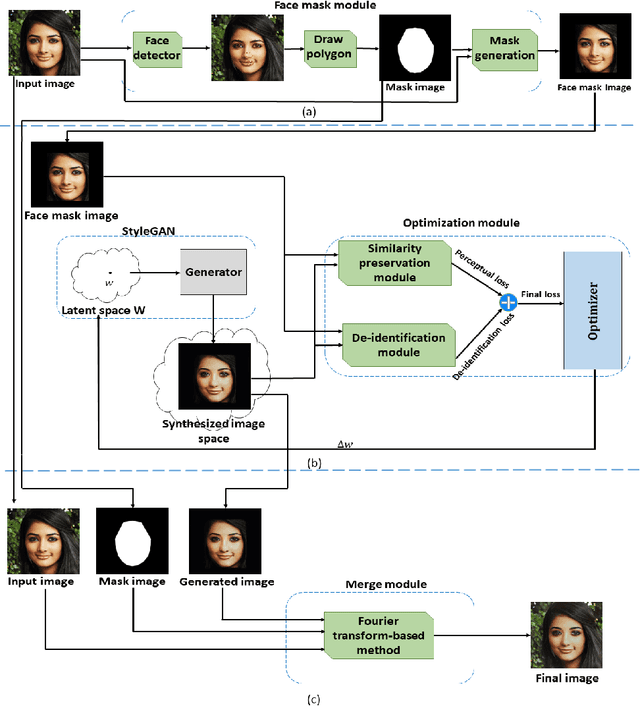



The use of social media websites and applications has become very popular and people share their photos on these networks. Automatic recognition and tagging of people's photos on these networks has raised privacy preservation issues and users seek methods for hiding their identities from these algorithms. Generative adversarial networks (GANs) are shown to be very powerful in generating face images in high diversity and also in editing face images. In this paper, we propose a Generative Mask-guided Face Image Manipulation (GMFIM) model based on GANs to apply imperceptible editing to the input face image to preserve the privacy of the person in the image. Our model consists of three main components: a) the face mask module to cut the face area out of the input image and omit the background, b) the GAN-based optimization module for manipulating the face image and hiding the identity and, c) the merge module for combining the background of the input image and the manipulated de-identified face image. Different criteria are considered in the loss function of the optimization step to produce high-quality images that are as similar as possible to the input image while they cannot be recognized by AFR systems. The results of the experiments on different datasets show that our model can achieve better performance against automated face recognition systems in comparison to the state-of-the-art methods and it catches a higher attack success rate in most experiments from a total of 18. Moreover, the generated images of our proposed model have the highest quality and are more pleasing to human eyes.
Face sketch to photo translation using generative adversarial networks
Oct 23, 2021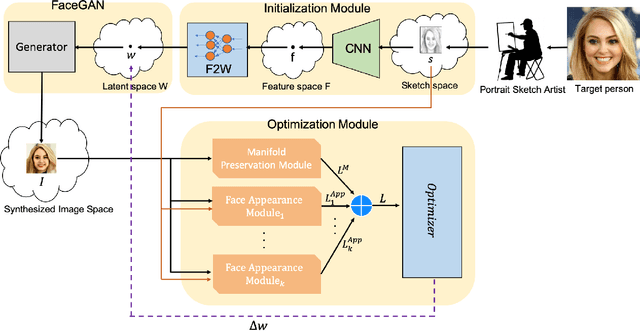
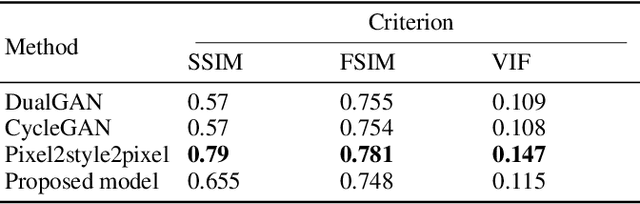
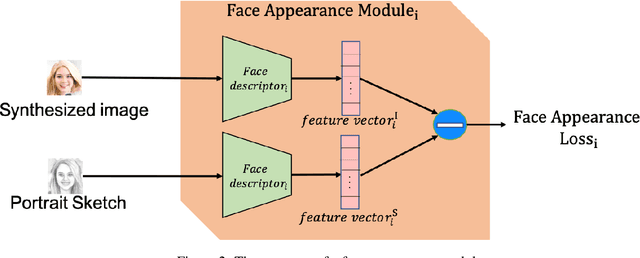
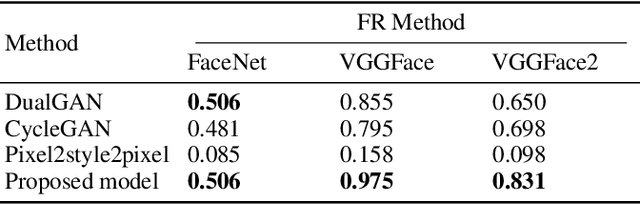
Translating face sketches to photo-realistic faces is an interesting and essential task in many applications like law enforcement and the digital entertainment industry. One of the most important challenges of this task is the inherent differences between the sketch and the real image such as the lack of color and details of the skin tissue in the sketch. With the advent of adversarial generative models, an increasing number of methods have been proposed for sketch-to-image synthesis. However, these models still suffer from limitations such as the large number of paired data required for training, the low resolution of the produced images, or the unrealistic appearance of the generated images. In this paper, we propose a method for converting an input facial sketch to a colorful photo without the need for any paired dataset. To do so, we use a pre-trained face photo generating model to synthesize high-quality natural face photos and employ an optimization procedure to keep high-fidelity to the input sketch. We train a network to map the facial features extracted from the input sketch to a vector in the latent space of the face generating model. Also, we study different optimization criteria and compare the results of the proposed model with those of the state-of-the-art models quantitatively and qualitatively. The proposed model achieved 0.655 in the SSIM index and 97.59% rank-1 face recognition rate with higher quality of the produced images.
Efficient Attention Branch Network with Combined Loss Function for Automatic Speaker Verification Spoof Detection
Sep 19, 2021
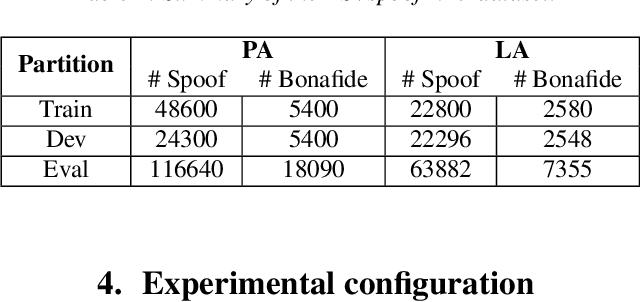
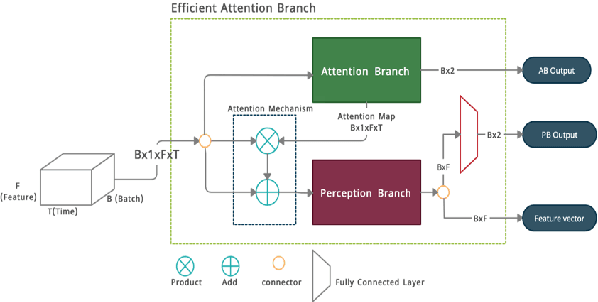

Many endeavors have sought to develop countermeasure techniques as enhancements on Automatic Speaker Verification (ASV) systems, in order to make them more robust against spoof attacks. As evidenced by the latest ASVspoof 2019 countermeasure challenge, models currently deployed for the task of ASV are, at their best, devoid of suitable degrees of generalization to unseen attacks. Upon further investigation of the proposed methods, it appears that a broader three-tiered view of the proposed systems. comprised of the classifier, feature extraction phase, and model loss function, may to some extent lessen the problem. Accordingly, the present study proposes the Efficient Attention Branch Network (EABN) modular architecture with a combined loss function to address the generalization problem...
Threat of Adversarial Attacks on Face Recognition: A Comprehensive Survey
Jul 22, 2020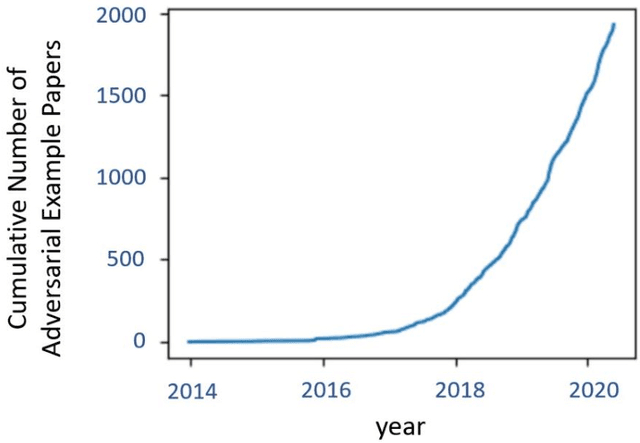
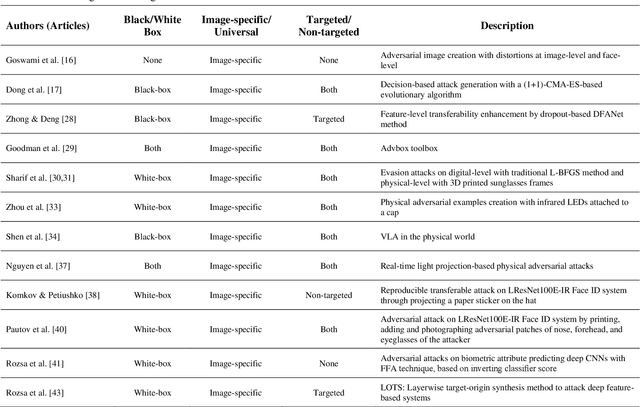

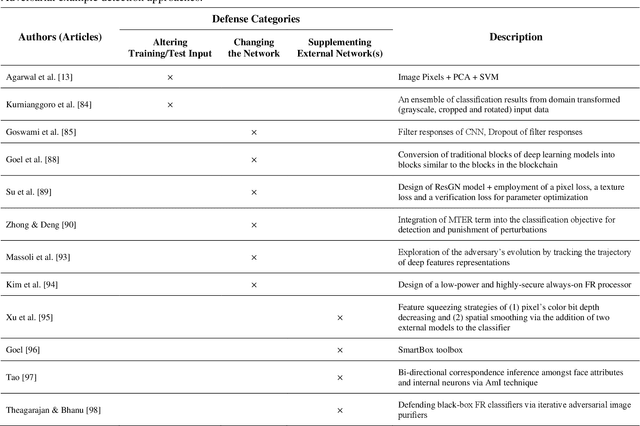
Face recognition (FR) systems have demonstrated outstanding verification performance, suggesting suitability for real-world applications, ranging from photo tagging in social media to automated border control (ABC). In an advanced FR system with deep learning-based architecture, however, promoting the recognition efficiency alone is not sufficient and the system should also withstand potential kinds of attacks designed to target its proficiency. Recent studies show that (deep) FR systems exhibit an intriguing vulnerability to imperceptible or perceptible but natural-looking adversarial input images that drive the model to incorrect output predictions. In this article, we present a comprehensive survey on adversarial attacks against FR systems and elaborate on the competence of new countermeasures against them. Further, we propose a taxonomy of existing attack and defense strategies according to different criteria. Finally, we compare the presented approaches according to techniques' characteristics.