 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace sketch to photo translation using generative adversarial networks
Paper and Code
Oct 23, 2021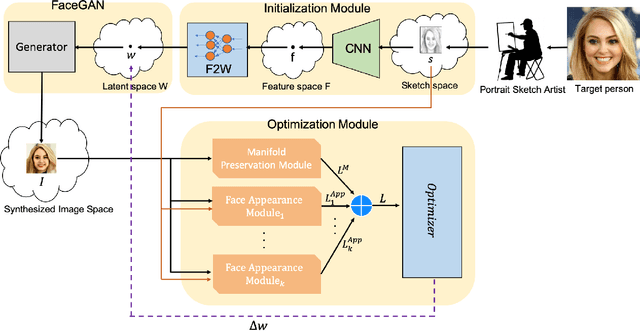
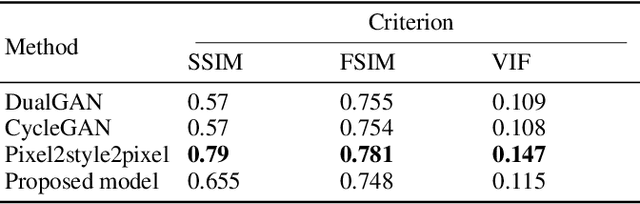
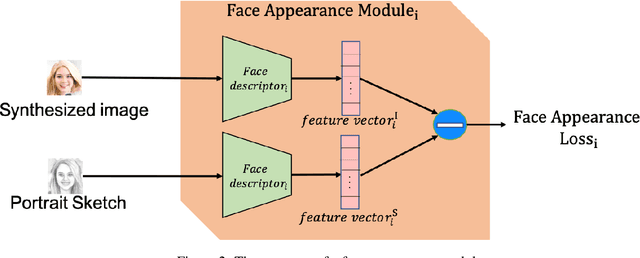
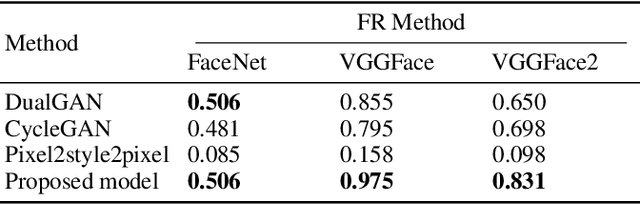
Translating face sketches to photo-realistic faces is an interesting and essential task in many applications like law enforcement and the digital entertainment industry. One of the most important challenges of this task is the inherent differences between the sketch and the real image such as the lack of color and details of the skin tissue in the sketch. With the advent of adversarial generative models, an increasing number of methods have been proposed for sketch-to-image synthesis. However, these models still suffer from limitations such as the large number of paired data required for training, the low resolution of the produced images, or the unrealistic appearance of the generated images. In this paper, we propose a method for converting an input facial sketch to a colorful photo without the need for any paired dataset. To do so, we use a pre-trained face photo generating model to synthesize high-quality natural face photos and employ an optimization procedure to keep high-fidelity to the input sketch. We train a network to map the facial features extracted from the input sketch to a vector in the latent space of the face generating model. Also, we study different optimization criteria and compare the results of the proposed model with those of the state-of-the-art models quantitatively and qualitatively. The proposed model achieved 0.655 in the SSIM index and 97.59% rank-1 face recognition rate with higher quality of the produced images.