 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmirkabir campus dataset: Real-world challenges and scenarios of Visual Inertial Odometry (VIO) for visually impaired people
Jan 07, 2024Visual Inertial Odometry (VIO) algorithms estimate the accurate camera trajectory by using camera and Inertial Measurement Unit (IMU) sensors. The applications of VIO span a diverse range, including augmented reality and indoor navigation. VIO algorithms hold the potential to facilitate navigation for visually impaired individuals in both indoor and outdoor settings. Nevertheless, state-of-the-art VIO algorithms encounter substantial challenges in dynamic environments, particularly in densely populated corridors. Existing VIO datasets, e.g., ADVIO, typically fail to effectively exploit these challenges. In this paper, we introduce the Amirkabir campus dataset (AUT-VI) to address the mentioned problem and improve the navigation systems. AUT-VI is a novel and super-challenging dataset with 126 diverse sequences in 17 different locations. This dataset contains dynamic objects, challenging loop-closure/map-reuse, different lighting conditions, reflections, and sudden camera movements to cover all extreme navigation scenarios. Moreover, in support of ongoing development efforts, we have released the Android application for data capture to the public. This allows fellow researchers to easily capture their customized VIO dataset variations. In addition, we evaluate state-of-the-art Visual Inertial Odometry (VIO) and Visual Odometry (VO) methods on our dataset, emphasizing the essential need for this challenging dataset.
Persian Natural Language Inference: A Meta-learning approach
May 18, 2022
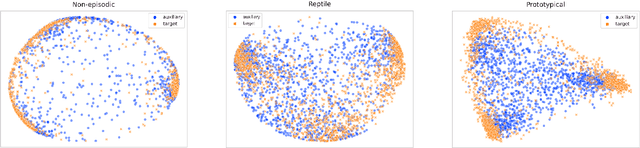
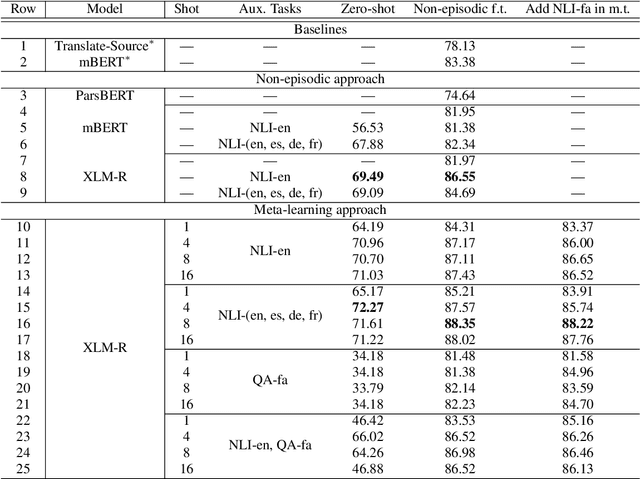
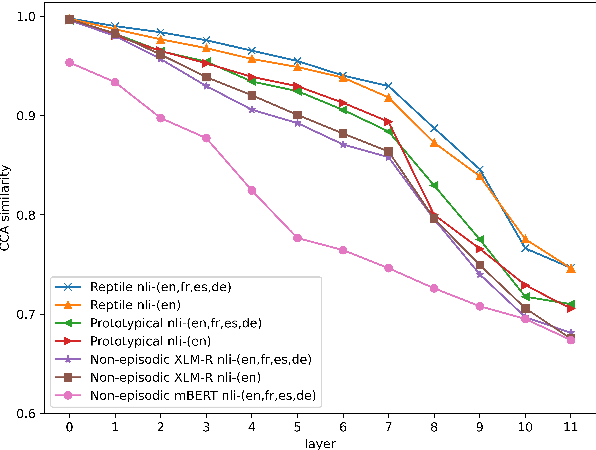
Incorporating information from other languages can improve the results of tasks in low-resource languages. A powerful method of building functional natural language processing systems for low-resource languages is to combine multilingual pre-trained representations with cross-lingual transfer learning. In general, however, shared representations are learned separately, either across tasks or across languages. This paper proposes a meta-learning approach for inferring natural language in Persian. Alternately, meta-learning uses different task information (such as QA in Persian) or other language information (such as natural language inference in English). Also, we investigate the role of task augmentation strategy for forming additional high-quality tasks. We evaluate the proposed method using four languages and an auxiliary task. Compared to the baseline approach, the proposed model consistently outperforms it, improving accuracy by roughly six percent. We also examine the effect of finding appropriate initial parameters using zero-shot evaluation and CCA similarity.