 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmirkabir campus dataset: Real-world challenges and scenarios of Visual Inertial Odometry (VIO) for visually impaired people
Jan 07, 2024Visual Inertial Odometry (VIO) algorithms estimate the accurate camera trajectory by using camera and Inertial Measurement Unit (IMU) sensors. The applications of VIO span a diverse range, including augmented reality and indoor navigation. VIO algorithms hold the potential to facilitate navigation for visually impaired individuals in both indoor and outdoor settings. Nevertheless, state-of-the-art VIO algorithms encounter substantial challenges in dynamic environments, particularly in densely populated corridors. Existing VIO datasets, e.g., ADVIO, typically fail to effectively exploit these challenges. In this paper, we introduce the Amirkabir campus dataset (AUT-VI) to address the mentioned problem and improve the navigation systems. AUT-VI is a novel and super-challenging dataset with 126 diverse sequences in 17 different locations. This dataset contains dynamic objects, challenging loop-closure/map-reuse, different lighting conditions, reflections, and sudden camera movements to cover all extreme navigation scenarios. Moreover, in support of ongoing development efforts, we have released the Android application for data capture to the public. This allows fellow researchers to easily capture their customized VIO dataset variations. In addition, we evaluate state-of-the-art Visual Inertial Odometry (VIO) and Visual Odometry (VO) methods on our dataset, emphasizing the essential need for this challenging dataset.
SRVIO: Super Robust Visual Inertial Odometry for dynamic environments and challenging Loop-closure conditions
Jan 14, 2022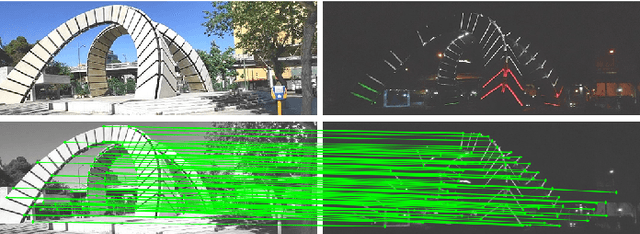
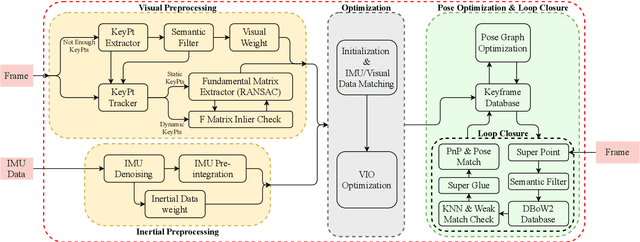

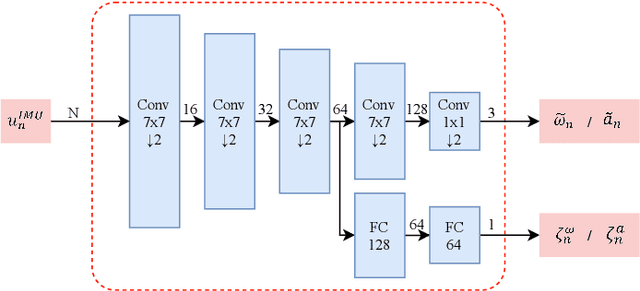
The visual localization or odometry problem is a well-known challenge in the field of autonomous robots and cars. Traditionally, this problem can ba tackled with the help of expensive sensors such as lidars. Nowadays, the leading research is on robust localization using economic sensors, such as cameras and IMUs. The geometric methods based on these sensors are pretty good in normal conditions withstable lighting and no dynamic objects. These methods suffer from significant loss and divergence in such challenging environments. The scientists came to use deep neural networks (DNNs) as the savior to mitigate this problem. The main idea behind using DNNs was to better understand the problem inside the data and overcome complex conditions (such as a dynamic object in front of the camera, extreme lighting conditions, keeping the track at high speeds, etc.) The prior endto-end DNN methods are able to overcome some of the mentioned challenges. However, no general and robust framework for all of these scenarios is available. In this paper, we have combined geometric and DNN based methods to have the pros of geometric SLAM frameworks and overcome the remaining challenges with the DNNs help. To do this, we have modified the Vins-Mono framework (the most robust and accurate framework till now) and we were able to achieve state-of-the-art results on TUM-Dynamic, TUM-VI, ADVIO and EuRoC datasets compared to geometric and end-to-end DNN based SLAMs. Our proposed framework was also able to achieve acceptable results on extreme simulated cases resembling the challenges mentioned earlier easy.
Convolutional Spiking Neural Networks for Spatio-Temporal Feature Extraction
Mar 27, 2020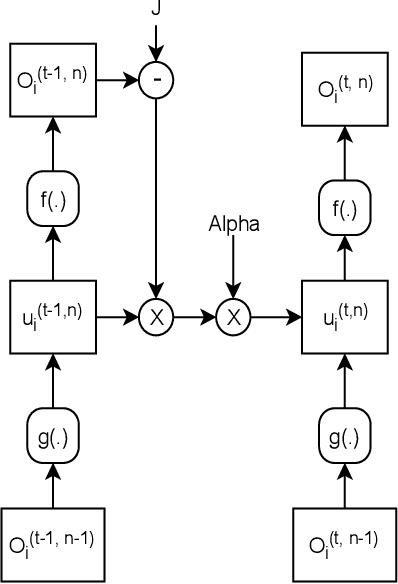
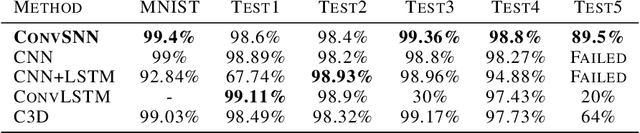


Spiking neural networks (SNNs) can be used in low-power and embedded systems (such as emerging neuromorphic chips) due to their event-based nature. Also, they have the advantage of low computation cost in contrast to conventional artificial neural networks (ANNs), while preserving ANN's properties. However, temporal coding in layers of convolutional spiking neural networks and other types of SNNs has yet to be studied. In this paper, we provide insight into spatio-temporal feature extraction of convolutional SNNs in experiments designed to exploit this property. Our proposed shallow convolutional SNN outperforms state-of-the-art spatio-temporal feature extractor methods such as C3D, ConvLstm, and similar networks. Furthermore, we present a new deep spiking architecture to tackle real-world problems (in particular classification tasks), and the model achieved superior performance compared to other SNN methods on CIFAR10-DVS. It is also worth noting that the training process is implemented based on spatio-temporal backpropagation, and ANN to SNN conversion methods will serve no use.