 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotal Recall QA: A Verifiable Evaluation Suite for Deep Research Agents
Mar 19, 2026Deep research agents have emerged as LLM-based systems designed to perform multi-step information seeking and reasoning over large, open-domain sources to answer complex questions by synthesizing information from multiple information sources. Given the complexity of the task and despite various recent efforts, evaluation of deep research agents remains fundamentally challenging. This paper identifies a list of requirements and optional properties for evaluating deep research agents. We observe that existing benchmarks do not satisfy all identified requirements. Inspired by prior research on TREC Total Recall Tracks, we introduce the task of Total Recall Question Answering and develop a framework for deep research agents evaluation that satisfies the identified criteria. Our framework constructs single-answer, total recall queries with precise evaluation and relevance judgments derived from a structured knowledge base paired with a text corpus, enabling large-scale data construction. Using this framework, we build TRQA, a deep research benchmark constructed from Wikidata-Wikipedia as a real-world source and a synthetically generated e-commerce knowledge base and corpus to mitigate the effects of data contamination. We benchmark the collection with representative retriever and deep research models and establish baseline retrieval and end-to-end results for future comparative evaluation.
Why Uncertainty Estimation Methods Fall Short in RAG: An Axiomatic Analysis
May 12, 2025Large Language Models (LLMs) are valued for their strong performance across various tasks, but they also produce inaccurate or misleading outputs. Uncertainty Estimation (UE) quantifies the model's confidence and helps users assess response reliability. However, existing UE methods have not been thoroughly examined in scenarios like Retrieval-Augmented Generation (RAG), where the input prompt includes non-parametric knowledge. This paper shows that current UE methods cannot reliably assess correctness in the RAG setting. We further propose an axiomatic framework to identify deficiencies in existing methods and guide the development of improved approaches. Our framework introduces five constraints that an effective UE method should meet after incorporating retrieved documents into the LLM's prompt. Experimental results reveal that no existing UE method fully satisfies all the axioms, explaining their suboptimal performance in RAG. We further introduce a simple yet effective calibration function based on our framework, which not only satisfies more axioms than baseline methods but also improves the correlation between uncertainty estimates and correctness.
Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
Mar 07, 2024Large language models (LLMs) memorize a vast amount of factual knowledge, exhibiting strong performance across diverse tasks and domains. However, it has been observed that the performance diminishes when dealing with less-popular or low-frequency concepts and entities, for example in domain specific applications. The two prominent approaches to enhance the performance of LLMs on low-frequent topics are: Retrieval Augmented Generation (RAG) and fine-tuning (FT) over synthetic data. This paper explores and evaluates the impact of RAG and FT on customizing LLMs in handling low-frequency entities on question answering task. Our findings indicate that FT significantly boosts the performance across entities of varying popularity, especially in the most and least popular groups, while RAG surpasses other methods. Additionally, the success of both RAG and FT approaches is amplified by advancements in retrieval and data augmentation techniques. We release our data and code at https://github.com/informagi/RAGvsFT.
Amirkabir campus dataset: Real-world challenges and scenarios of Visual Inertial Odometry (VIO) for visually impaired people
Jan 07, 2024Visual Inertial Odometry (VIO) algorithms estimate the accurate camera trajectory by using camera and Inertial Measurement Unit (IMU) sensors. The applications of VIO span a diverse range, including augmented reality and indoor navigation. VIO algorithms hold the potential to facilitate navigation for visually impaired individuals in both indoor and outdoor settings. Nevertheless, state-of-the-art VIO algorithms encounter substantial challenges in dynamic environments, particularly in densely populated corridors. Existing VIO datasets, e.g., ADVIO, typically fail to effectively exploit these challenges. In this paper, we introduce the Amirkabir campus dataset (AUT-VI) to address the mentioned problem and improve the navigation systems. AUT-VI is a novel and super-challenging dataset with 126 diverse sequences in 17 different locations. This dataset contains dynamic objects, challenging loop-closure/map-reuse, different lighting conditions, reflections, and sudden camera movements to cover all extreme navigation scenarios. Moreover, in support of ongoing development efforts, we have released the Android application for data capture to the public. This allows fellow researchers to easily capture their customized VIO dataset variations. In addition, we evaluate state-of-the-art Visual Inertial Odometry (VIO) and Visual Odometry (VO) methods on our dataset, emphasizing the essential need for this challenging dataset.
Data Augmentation for Conversational AI
Sep 09, 2023Advancements in conversational systems have revolutionized information access, surpassing the limitations of single queries. However, developing dialogue systems requires a large amount of training data, which is a challenge in low-resource domains and languages. Traditional data collection methods like crowd-sourcing are labor-intensive and time-consuming, making them ineffective in this context. Data augmentation (DA) is an affective approach to alleviate the data scarcity problem in conversational systems. This tutorial provides a comprehensive and up-to-date overview of DA approaches in the context of conversational systems. It highlights recent advances in conversation augmentation, open domain and task-oriented conversation generation, and different paradigms of evaluating these models. We also discuss current challenges and future directions in order to help researchers and practitioners to further advance the field in this area.
Persian Natural Language Inference: A Meta-learning approach
May 18, 2022
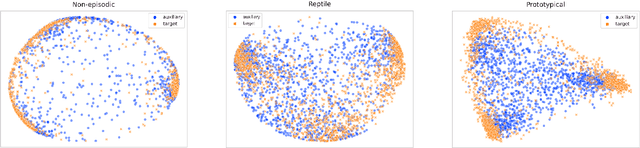
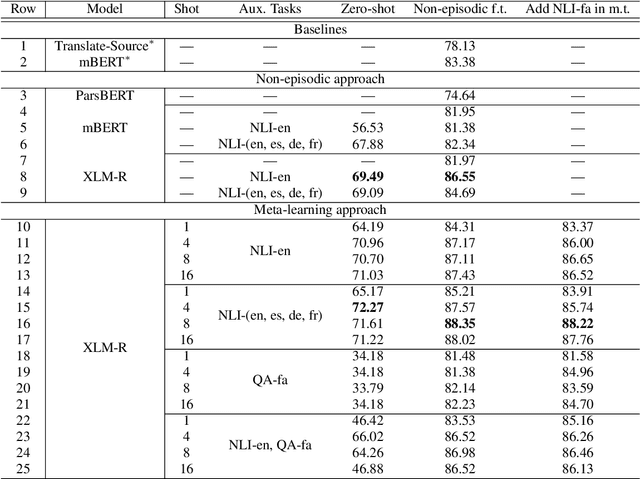
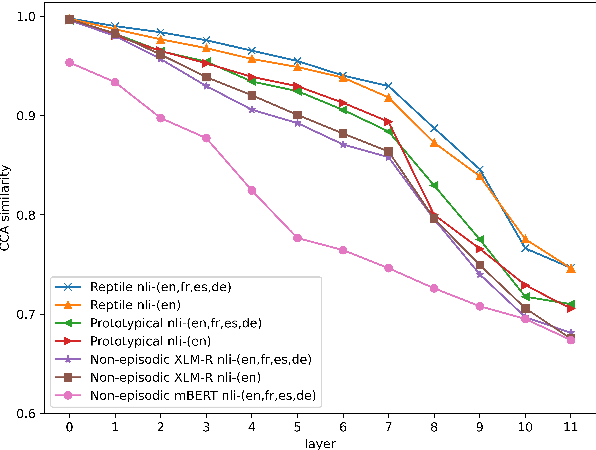
Incorporating information from other languages can improve the results of tasks in low-resource languages. A powerful method of building functional natural language processing systems for low-resource languages is to combine multilingual pre-trained representations with cross-lingual transfer learning. In general, however, shared representations are learned separately, either across tasks or across languages. This paper proposes a meta-learning approach for inferring natural language in Persian. Alternately, meta-learning uses different task information (such as QA in Persian) or other language information (such as natural language inference in English). Also, we investigate the role of task augmentation strategy for forming additional high-quality tasks. We evaluate the proposed method using four languages and an auxiliary task. Compared to the baseline approach, the proposed model consistently outperforms it, improving accuracy by roughly six percent. We also examine the effect of finding appropriate initial parameters using zero-shot evaluation and CCA similarity.