 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineLOG: A Training Free Approach for Cinematic Long Video Generation
Dec 13, 2025Controllable video synthesis is a central challenge in computer vision, yet current models struggle with fine grained control beyond textual prompts, particularly for cinematic attributes like camera trajectory and genre. Existing datasets often suffer from severe data imbalance, noisy labels, or a significant simulation to real gap. To address this, we introduce CineLOG, a new dataset of 5,000 high quality, balanced, and uncut video clips. Each entry is annotated with a detailed scene description, explicit camera instructions based on a standard cinematic taxonomy, and genre label, ensuring balanced coverage across 17 diverse camera movements and 15 film genres. We also present our novel pipeline designed to create this dataset, which decouples the complex text to video (T2V) generation task into four easier stages with more mature technology. To enable coherent, multi shot sequences, we introduce a novel Trajectory Guided Transition Module that generates smooth spatio-temporal interpolation. Extensive human evaluations show that our pipeline significantly outperforms SOTA end to end T2V models in adhering to specific camera and screenplay instructions, while maintaining professional visual quality. All codes and data are available at https://cine-log.pages.dev.
Checklist Engineering Empowers Multilingual LLM Judges
Jul 09, 2025
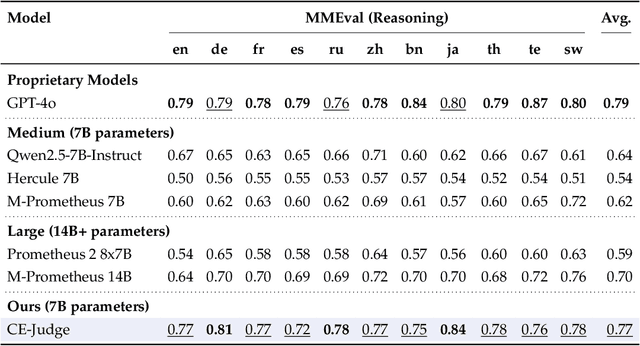
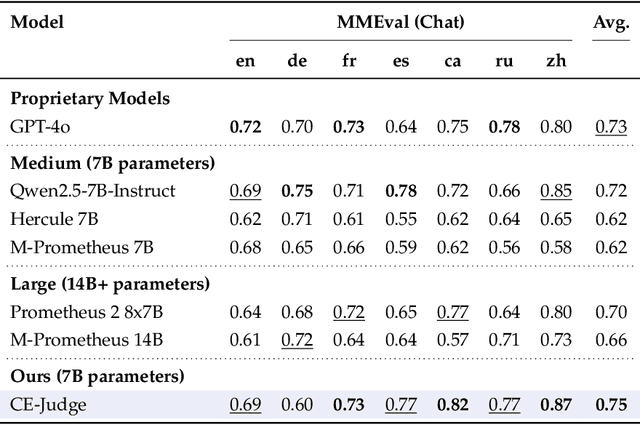

Automated text evaluation has long been a central issue in Natural Language Processing (NLP). Recently, the field has shifted toward using Large Language Models (LLMs) as evaluators-a trend known as the LLM-as-a-Judge paradigm. While promising and easily adaptable across tasks, this approach has seen limited exploration in multilingual contexts. Existing multilingual studies often rely on proprietary models or require extensive training data for fine-tuning, raising concerns about cost, time, and efficiency. In this paper, we propose Checklist Engineering based LLM-as-a-Judge (CE-Judge), a training-free framework that uses checklist intuition for multilingual evaluation with an open-source model. Experiments across multiple languages and three benchmark datasets, under both pointwise and pairwise settings, show that our method generally surpasses the baselines and performs on par with the GPT-4o model.
Zero-Shot Learning and Key Points Are All You Need for Automated Fact-Checking
Aug 15, 2024

Automated fact-checking is an important task because determining the accurate status of a proposed claim within the vast amount of information available online is a critical challenge. This challenge requires robust evaluation to prevent the spread of false information. Modern large language models (LLMs) have demonstrated high capability in performing a diverse range of Natural Language Processing (NLP) tasks. By utilizing proper prompting strategies, their versatility due to their understanding of large context sizes and zero-shot learning ability enables them to simulate human problem-solving intuition and move towards being an alternative to humans for solving problems. In this work, we introduce a straightforward framework based on Zero-Shot Learning and Key Points (ZSL-KeP) for automated fact-checking, which despite its simplicity, performed well on the AVeriTeC shared task dataset by robustly improving the baseline and achieving 10th place.
Consistency Training by Synthetic Question Generation for Conversational Question Answering
Apr 17, 2024



Efficiently modeling historical information is a critical component in addressing user queries within a conversational question-answering (QA) context, as historical context plays a vital role in clarifying the user's questions. However, irrelevant history induces noise in the reasoning process, especially for those questions with a considerable historical context. In our novel model-agnostic approach, referred to as CoTaH (Consistency-Trained augmented History), we augment the historical information with synthetic questions and subsequently employ consistency training to train a model that utilizes both real and augmented historical data to implicitly make the reasoning robust to irrelevant history. To the best of our knowledge, this is the first instance of research using question generation as a form of data augmentation to model conversational QA settings. By citing a common modeling error prevalent in previous research, we introduce a new baseline model and compare our model's performance against it, demonstrating an improvement in results, particularly when dealing with questions that include a substantial amount of historical context. The source code can be found on our GitHub page.
Multi-BERT: Leveraging Adapters and Prompt Tuning for Low-Resource Multi-Domain Adaptation
Apr 02, 2024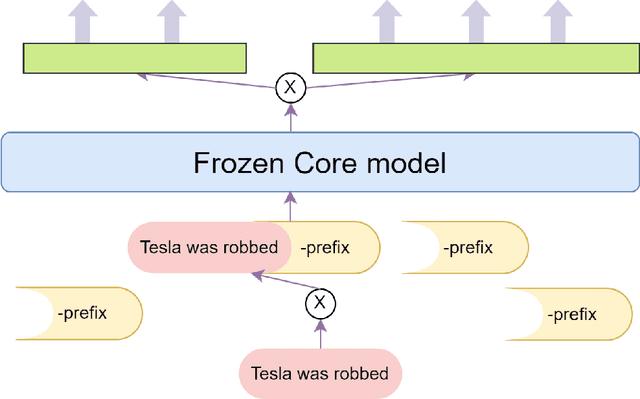



The rapid expansion of texts' volume and diversity presents formidable challenges in multi-domain settings. These challenges are also visible in the Persian name entity recognition (NER) settings. Traditional approaches, either employing a unified model for multiple domains or individual models for each domain, frequently pose significant limitations. Single models often struggle to capture the nuances of diverse domains, while utilizing multiple large models can lead to resource constraints, rendering the training of a model for each domain virtually impractical. Therefore, this paper introduces a novel approach composed of one core model with multiple sets of domain-specific parameters. We utilize techniques such as prompt tuning and adapters, combined with the incorporation of additional layers, to add parameters that we can train for the specific domains. This enables the model to perform comparably to individual models for each domain. Experimental results on different formal and informal datasets show that by employing these added parameters, the proposed model significantly surpasses existing practical models in performance. Remarkably, the proposed model requires only one instance for training and storage, yet achieves outstanding results across all domains, even surpassing the state-of-the-art in some. Moreover, we analyze each adaptation strategy, delineating its strengths, weaknesses, and optimal hyper-parameters for the Persian NER settings. Finally, we introduce a document-based domain detection pipeline tailored for scenarios with unknown text domains, enhancing the adaptability and practicality of this paper in real-world applications.
FaBERT: Pre-training BERT on Persian Blogs
Feb 09, 2024



We introduce FaBERT, a Persian BERT-base model pre-trained on the HmBlogs corpus, encompassing both informal and formal Persian texts. FaBERT is designed to excel in traditional Natural Language Understanding (NLU) tasks, addressing the intricacies of diverse sentence structures and linguistic styles prevalent in the Persian language. In our comprehensive evaluation of FaBERT on 12 datasets in various downstream tasks, encompassing Sentiment Analysis (SA), Named Entity Recognition (NER), Natural Language Inference (NLI), Question Answering (QA), and Question Paraphrasing (QP), it consistently demonstrated improved performance, all achieved within a compact model size. The findings highlight the importance of utilizing diverse and cleaned corpora, such as HmBlogs, to enhance the performance of language models like BERT in Persian Natural Language Processing (NLP) applications. FaBERT is openly accessible at https://huggingface.co/sbunlp/fabert
PCoQA: Persian Conversational Question Answering Dataset
Dec 07, 2023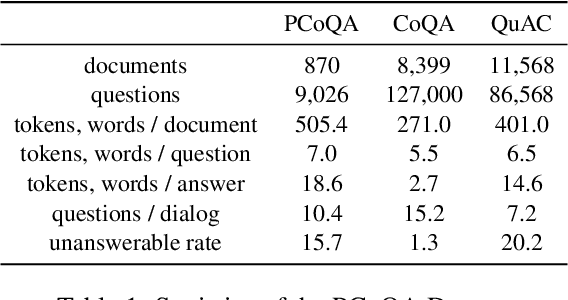
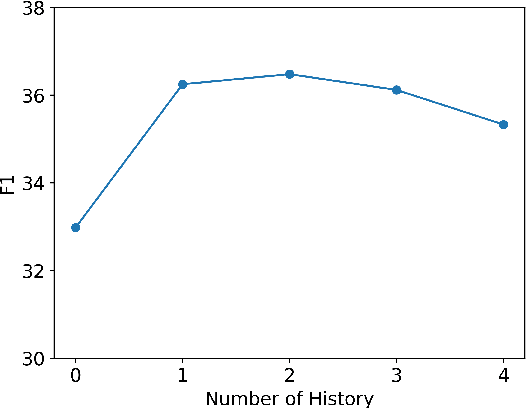
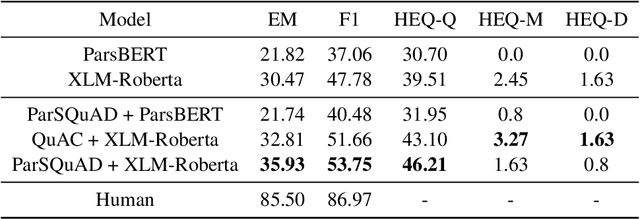
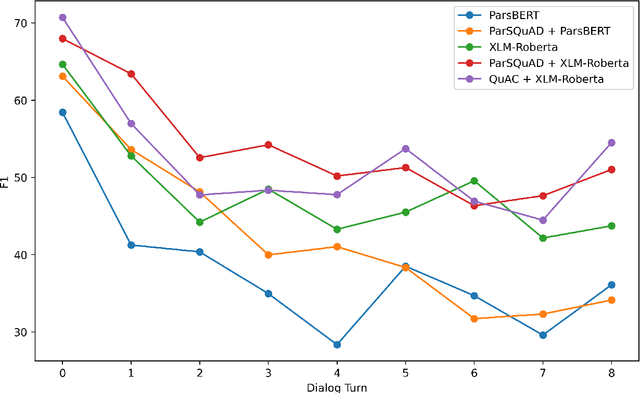
Humans seek information regarding a specific topic through performing a conversation containing a series of questions and answers. In the pursuit of conversational question answering research, we introduce the PCoQA, the first \textbf{P}ersian \textbf{Co}nversational \textbf{Q}uestion \textbf{A}nswering dataset, a resource comprising information-seeking dialogs encompassing a total of 9,026 contextually-driven questions. Each dialog involves a questioner, a responder, and a document from the Wikipedia; The questioner asks several inter-connected questions from the text and the responder provides a span of the document as the answer for each question. PCoQA is designed to present novel challenges compared to previous question answering datasets including having more open-ended non-factual answers, longer answers, and fewer lexical overlaps. This paper not only presents the comprehensive PCoQA dataset but also reports the performance of various benchmark models. Our models include baseline models and pre-trained models, which are leveraged to boost the performance of the model. The dataset and benchmarks are available at our Github page.
KhabarChin: Automatic Detection of Important News in the Persian Language
Dec 06, 2023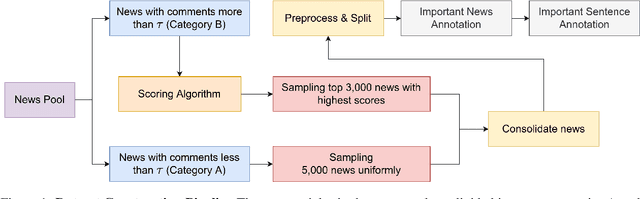
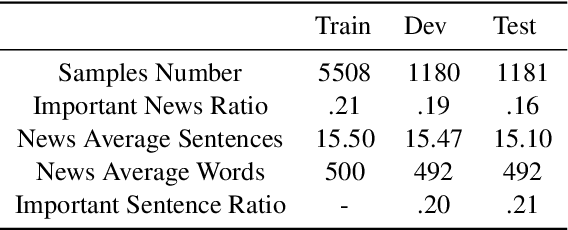
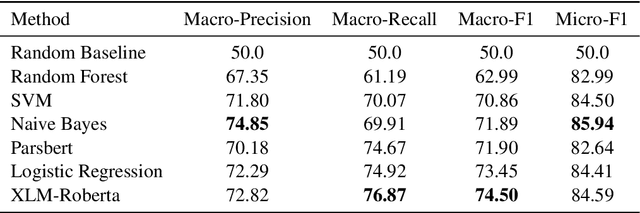

Being aware of important news is crucial for staying informed and making well-informed decisions efficiently. Natural Language Processing (NLP) approaches can significantly automate this process. This paper introduces the detection of important news, in a previously unexplored area, and presents a new benchmarking dataset (Khabarchin) for detecting important news in the Persian language. We define important news articles as those deemed significant for a considerable portion of society, capable of influencing their mindset or decision-making. The news articles are obtained from seven different prominent Persian news agencies, resulting in the annotation of 7,869 samples and the creation of the dataset. Two challenges of high disagreement and imbalance between classes were faced, and solutions were provided for them. We also propose several learning-based models, ranging from conventional machine learning to state-of-the-art transformer models, to tackle this task. Furthermore, we introduce the second task of important sentence detection in news articles, as they often come with a significant contextual length that makes it challenging for readers to identify important information. We identify these sentences in a weakly supervised manner.
Persian Natural Language Inference: A Meta-learning approach
May 18, 2022
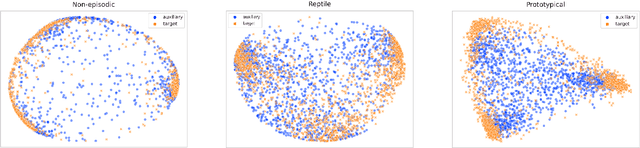
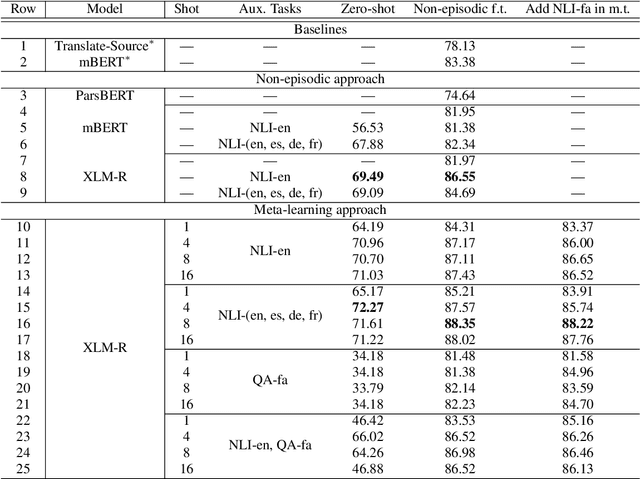
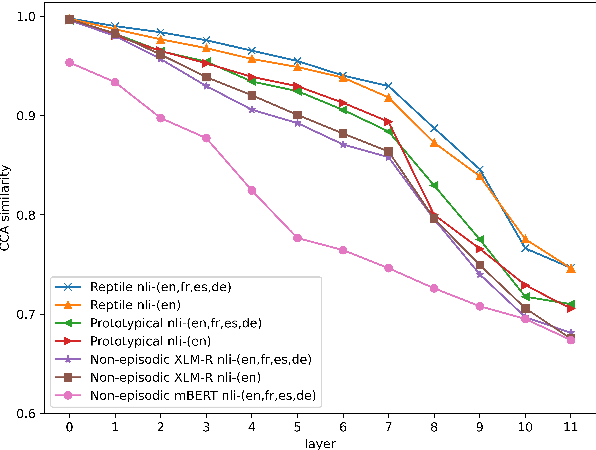
Incorporating information from other languages can improve the results of tasks in low-resource languages. A powerful method of building functional natural language processing systems for low-resource languages is to combine multilingual pre-trained representations with cross-lingual transfer learning. In general, however, shared representations are learned separately, either across tasks or across languages. This paper proposes a meta-learning approach for inferring natural language in Persian. Alternately, meta-learning uses different task information (such as QA in Persian) or other language information (such as natural language inference in English). Also, we investigate the role of task augmentation strategy for forming additional high-quality tasks. We evaluate the proposed method using four languages and an auxiliary task. Compared to the baseline approach, the proposed model consistently outperforms it, improving accuracy by roughly six percent. We also examine the effect of finding appropriate initial parameters using zero-shot evaluation and CCA similarity.
Gransformer: Transformer-based Graph Generation
Mar 25, 2022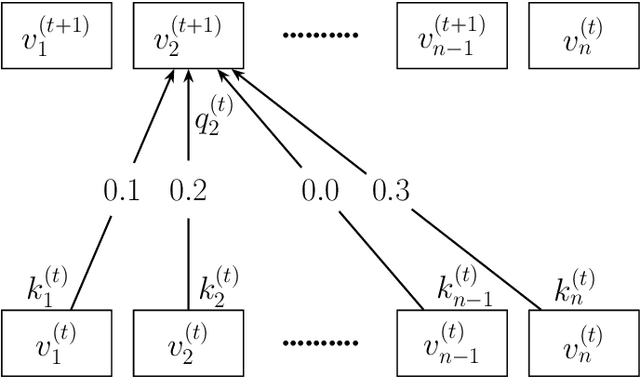
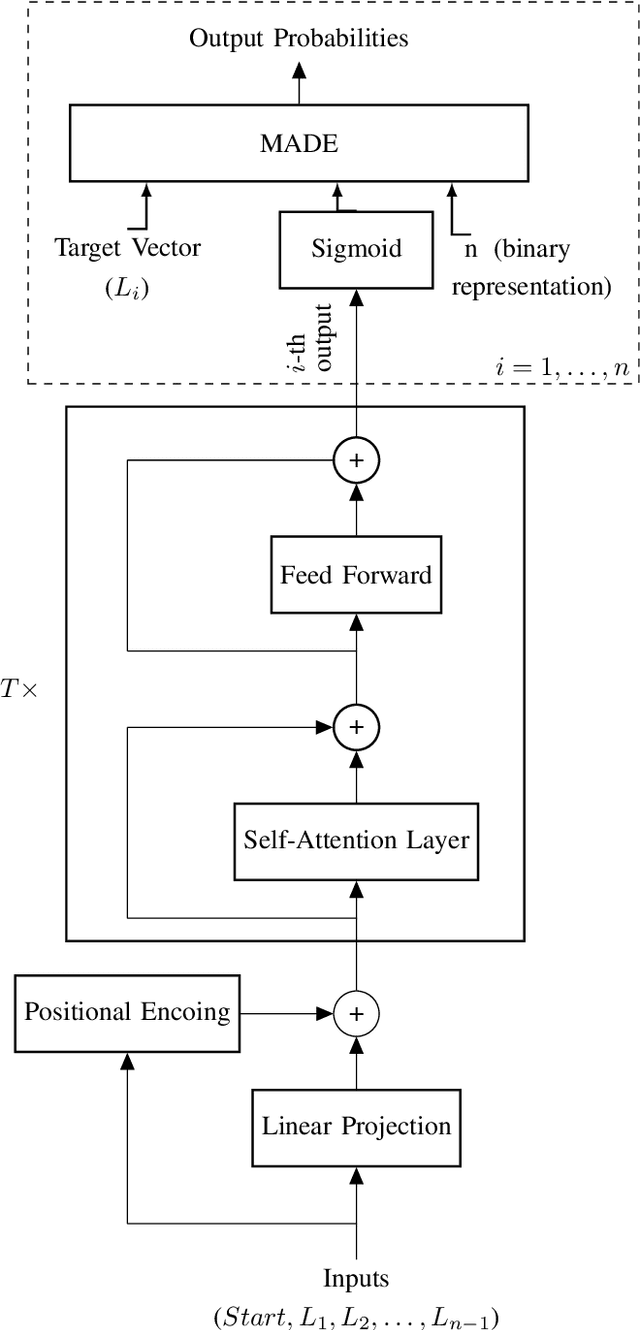
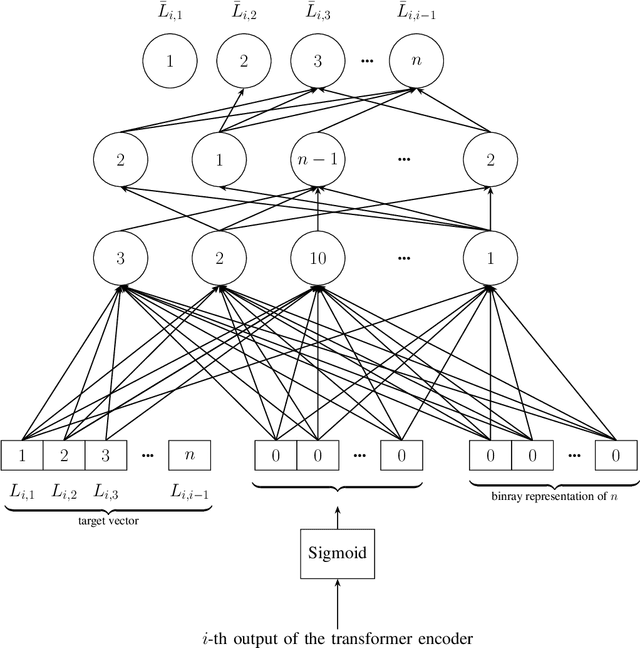

Transformers have become widely used in modern models for various tasks such as natural language processing and machine vision. This paper, proposes Gransformer, an algorithm for generating graphs that takes advantage of the transformer. We extend a simple autoregressive transformer encoder to exploit the structural information of the graph through efficient modifications. The attention mechanism is modified to consider the presence or absence of edges between each pair of nodes. We also introduce a graph-based familiarity measure that applies to both the attention and the positional coding. This autoregressive criterion, inspired by message passing algorithms, contains structural information about the graph. In the output layer, we also use a masked autoencoder for density estimation to efficiently model the generation of dependent edges. We also propose a technique to prevent the model from generating isolated nodes. We evaluate this method on two real-world datasets and compare it with some state-of-the-art autoregressive graph generation methods. Experimental results have shown that the proposed method performs comparative to these methods, including recurrent models and graph convolutional networks.