 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhabarChin: Automatic Detection of Important News in the Persian Language
Dec 06, 2023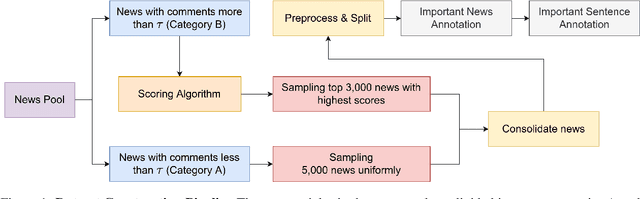
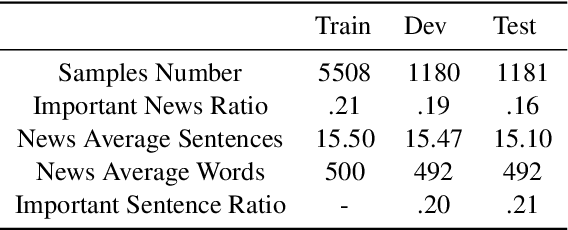
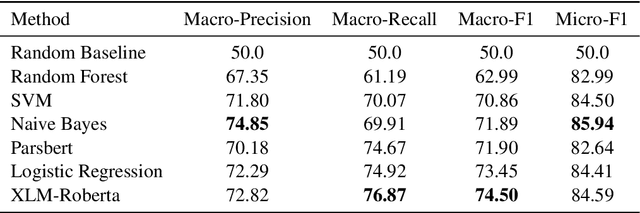

Being aware of important news is crucial for staying informed and making well-informed decisions efficiently. Natural Language Processing (NLP) approaches can significantly automate this process. This paper introduces the detection of important news, in a previously unexplored area, and presents a new benchmarking dataset (Khabarchin) for detecting important news in the Persian language. We define important news articles as those deemed significant for a considerable portion of society, capable of influencing their mindset or decision-making. The news articles are obtained from seven different prominent Persian news agencies, resulting in the annotation of 7,869 samples and the creation of the dataset. Two challenges of high disagreement and imbalance between classes were faced, and solutions were provided for them. We also propose several learning-based models, ranging from conventional machine learning to state-of-the-art transformer models, to tackle this task. Furthermore, we introduce the second task of important sentence detection in news articles, as they often come with a significant contextual length that makes it challenging for readers to identify important information. We identify these sentences in a weakly supervised manner.
Improving Persian Relation Extraction Models by Data Augmentation
Mar 29, 2022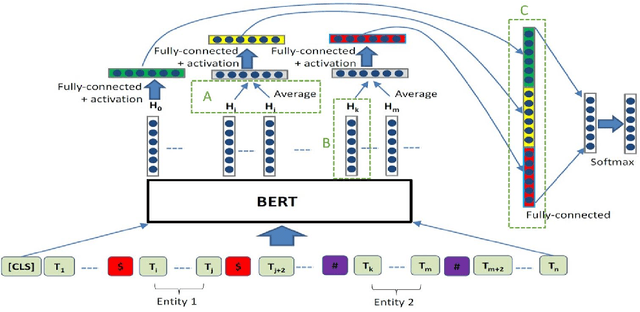

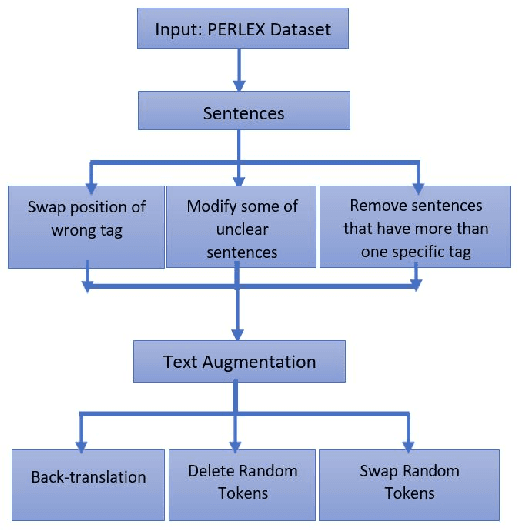
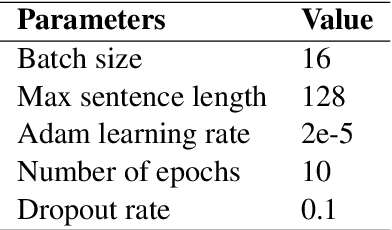
Relation extraction that is the task of predicting semantic relation type between entities in a sentence or document is an important task in natural language processing. Although there are many researches and datasets for English, Persian suffers from sufficient researches and comprehensive datasets. The only available Persian dataset for this task is PERLEX, which is a Persian expert-translated version of the SemEval-2010-Task-8 dataset. In this paper, we present our augmented dataset and the results and findings of our system, participated in the Persian relation Extraction shared task of NSURL 2021 workshop. We use PERLEX as the base dataset and enhance it by applying some text preprocessing steps and by increasing its size via data augmentation techniques to improve the generalization and robustness of applied models. We then employ two different models including ParsBERT and multilingual BERT for relation extraction on the augmented PERLEX dataset. Our best model obtained 64.67% of Macro-F1 on the test phase of the contest and it achieved 83.68% of Macro-F1 on the test set of PERLEX.
* 5 pages, 6 images