 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFBES at SemEval-2024 Task 8: Investigating Syntactic and Semantic Features for Distinguishing AI-Generated and Human-Written Texts
Feb 19, 2024



Nowadays, the usage of Large Language Models (LLMs) has increased, and LLMs have been used to generate texts in different languages and for different tasks. Additionally, due to the participation of remarkable companies such as Google and OpenAI, LLMs are now more accessible, and people can easily use them. However, an important issue is how we can detect AI-generated texts from human-written ones. In this article, we have investigated the problem of AI-generated text detection from two different aspects: semantics and syntax. Finally, we presented an AI model that can distinguish AI-generated texts from human-written ones with high accuracy on both multilingual and monolingual tasks using the M4 dataset. According to our results, using a semantic approach would be more helpful for detection. However, there is a lot of room for improvement in the syntactic approach, and it would be a good approach for future work.
Improving Persian Relation Extraction Models by Data Augmentation
Mar 29, 2022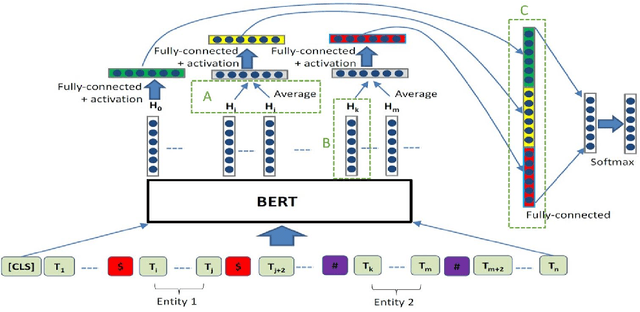

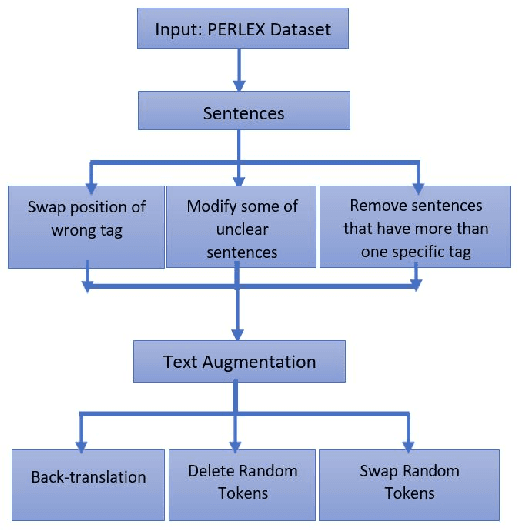
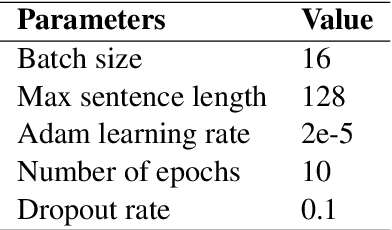
Relation extraction that is the task of predicting semantic relation type between entities in a sentence or document is an important task in natural language processing. Although there are many researches and datasets for English, Persian suffers from sufficient researches and comprehensive datasets. The only available Persian dataset for this task is PERLEX, which is a Persian expert-translated version of the SemEval-2010-Task-8 dataset. In this paper, we present our augmented dataset and the results and findings of our system, participated in the Persian relation Extraction shared task of NSURL 2021 workshop. We use PERLEX as the base dataset and enhance it by applying some text preprocessing steps and by increasing its size via data augmentation techniques to improve the generalization and robustness of applied models. We then employ two different models including ParsBERT and multilingual BERT for relation extraction on the augmented PERLEX dataset. Our best model obtained 64.67% of Macro-F1 on the test phase of the contest and it achieved 83.68% of Macro-F1 on the test set of PERLEX.
* 5 pages, 6 images
A Knowledge-based Approach for Answering Complex Questions in Persian
Jul 05, 2021
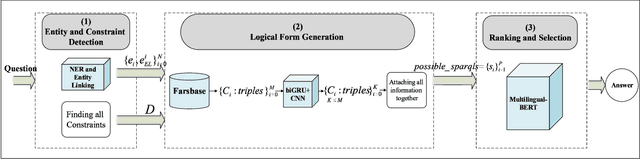
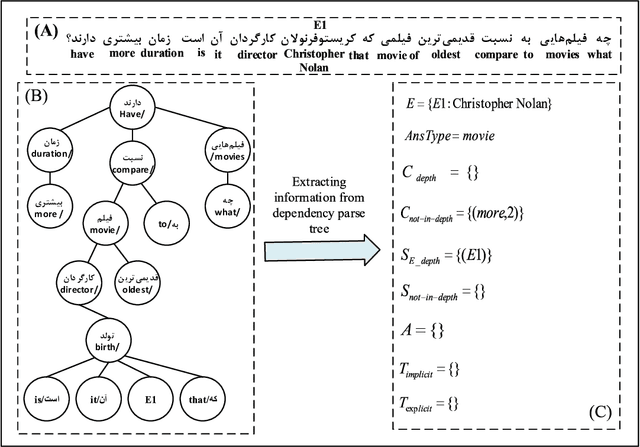

Research on open-domain question answering (QA) has a long tradition. A challenge in this domain is answering complex questions (CQA) that require complex inference methods and large amounts of knowledge. In low resource languages, such as Persian, there are not many datasets for open-domain complex questions and also the language processing toolkits are not very accurate. In this paper, we propose a knowledge-based approach for answering Persian complex questions using Farsbase; the Persian knowledge graph, exploiting PeCoQ; the newly created complex Persian question dataset. In this work, we handle multi-constraint and multi-hop questions by building their set of possible corresponding logical forms. Then Multilingual-BERT is used to select the logical form that best describes the input complex question syntactically and semantically. The answer to the question is built from the answer to the logical form, extracted from the knowledge graph. Experiments show that our approach outperforms other approaches in Persian CQA.
PeCoQ: A Dataset for Persian Complex Question Answering over Knowledge Graph
Jun 27, 2021



Question answering systems may find the answers to users' questions from either unstructured texts or structured data such as knowledge graphs. Answering questions using supervised learning approaches including deep learning models need large training datasets. In recent years, some datasets have been presented for the task of Question answering over knowledge graphs, which is the focus of this paper. Although many datasets in English were proposed, there have been a few question-answering datasets in Persian. This paper introduces \textit{PeCoQ}, a dataset for Persian question answering. This dataset contains 10,000 complex questions and answers extracted from the Persian knowledge graph, FarsBase. For each question, the SPARQL query and two paraphrases that were written by linguists are provided as well. There are different types of complexities in the dataset, such as multi-relation, multi-entity, ordinal, and temporal constraints. In this paper, we discuss the dataset's characteristics and describe our methodology for building it.