 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Training by Synthetic Question Generation for Conversational Question Answering
Apr 17, 2024



Efficiently modeling historical information is a critical component in addressing user queries within a conversational question-answering (QA) context, as historical context plays a vital role in clarifying the user's questions. However, irrelevant history induces noise in the reasoning process, especially for those questions with a considerable historical context. In our novel model-agnostic approach, referred to as CoTaH (Consistency-Trained augmented History), we augment the historical information with synthetic questions and subsequently employ consistency training to train a model that utilizes both real and augmented historical data to implicitly make the reasoning robust to irrelevant history. To the best of our knowledge, this is the first instance of research using question generation as a form of data augmentation to model conversational QA settings. By citing a common modeling error prevalent in previous research, we introduce a new baseline model and compare our model's performance against it, demonstrating an improvement in results, particularly when dealing with questions that include a substantial amount of historical context. The source code can be found on our GitHub page.
PCoQA: Persian Conversational Question Answering Dataset
Dec 07, 2023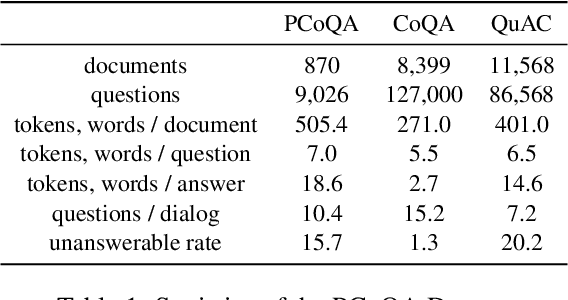
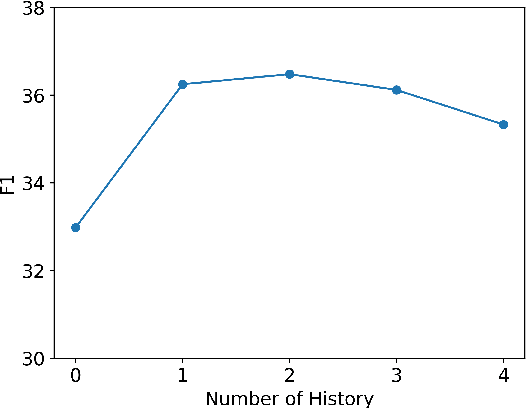
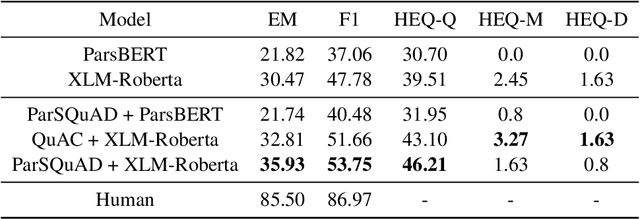
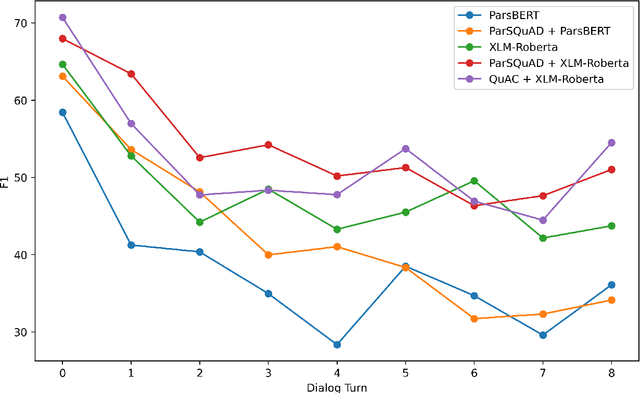
Humans seek information regarding a specific topic through performing a conversation containing a series of questions and answers. In the pursuit of conversational question answering research, we introduce the PCoQA, the first \textbf{P}ersian \textbf{Co}nversational \textbf{Q}uestion \textbf{A}nswering dataset, a resource comprising information-seeking dialogs encompassing a total of 9,026 contextually-driven questions. Each dialog involves a questioner, a responder, and a document from the Wikipedia; The questioner asks several inter-connected questions from the text and the responder provides a span of the document as the answer for each question. PCoQA is designed to present novel challenges compared to previous question answering datasets including having more open-ended non-factual answers, longer answers, and fewer lexical overlaps. This paper not only presents the comprehensive PCoQA dataset but also reports the performance of various benchmark models. Our models include baseline models and pre-trained models, which are leveraged to boost the performance of the model. The dataset and benchmarks are available at our Github page.
KhabarChin: Automatic Detection of Important News in the Persian Language
Dec 06, 2023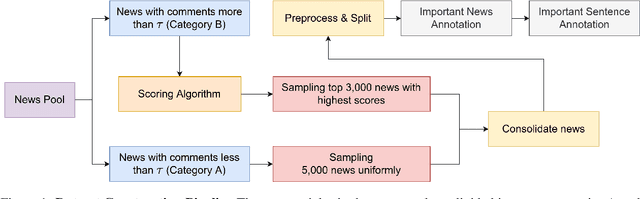
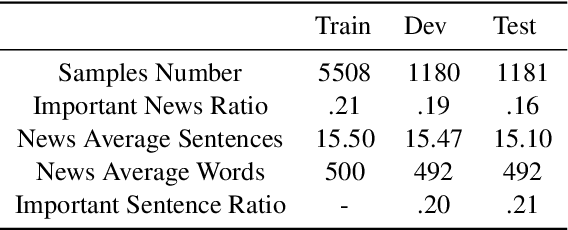
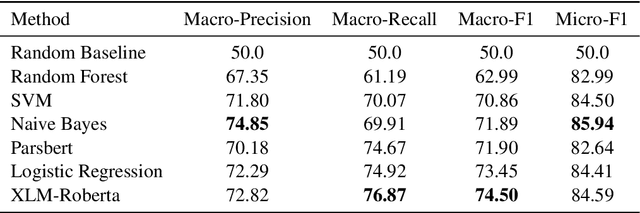

Being aware of important news is crucial for staying informed and making well-informed decisions efficiently. Natural Language Processing (NLP) approaches can significantly automate this process. This paper introduces the detection of important news, in a previously unexplored area, and presents a new benchmarking dataset (Khabarchin) for detecting important news in the Persian language. We define important news articles as those deemed significant for a considerable portion of society, capable of influencing their mindset or decision-making. The news articles are obtained from seven different prominent Persian news agencies, resulting in the annotation of 7,869 samples and the creation of the dataset. Two challenges of high disagreement and imbalance between classes were faced, and solutions were provided for them. We also propose several learning-based models, ranging from conventional machine learning to state-of-the-art transformer models, to tackle this task. Furthermore, we introduce the second task of important sentence detection in news articles, as they often come with a significant contextual length that makes it challenging for readers to identify important information. We identify these sentences in a weakly supervised manner.