 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Novelty: Improve the Diversity and Novelty of Contents Generated by Large Language Models via inference-time Multi-Views Brainstorming
Feb 18, 2025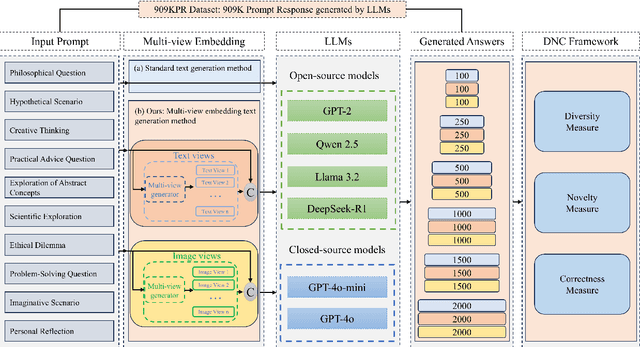


Large Language Models (LLMs) demonstrate remarkable proficiency in generating accurate and fluent text. However, they often struggle with diversity and novelty, leading to repetitive or overly deterministic responses. These limitations stem from constraints in training data, including gaps in specific knowledge domains, outdated information, and an over-reliance on textual sources. Such shortcomings reduce their effectiveness in tasks requiring creativity, multi-perspective reasoning, and exploratory thinking, such as LLM based AI scientist agents and creative artist agents . To address this challenge, we introduce inference-time multi-view brainstorming method, a novel approach that enriches input prompts with diverse perspectives derived from both textual and visual sources, which we refere to as "Multi-Novelty". By incorporating additional contextual information as diverse starting point for chain of thoughts, this method enhances the variety and creativity of generated outputs. Importantly, our approach is model-agnostic, requiring no architectural modifications and being compatible with both open-source and proprietary LLMs.
KhabarChin: Automatic Detection of Important News in the Persian Language
Dec 06, 2023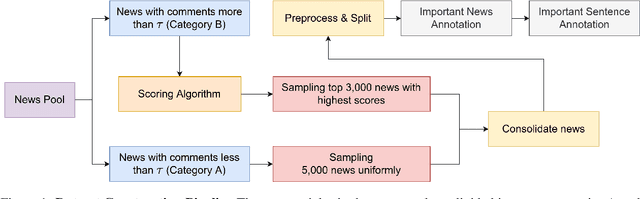
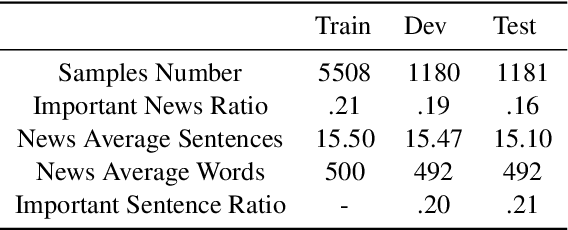
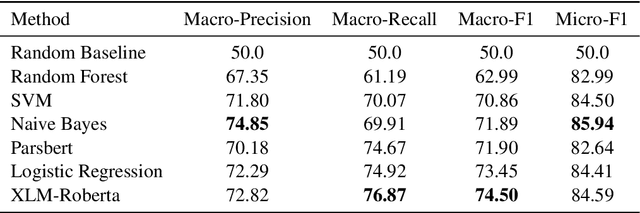

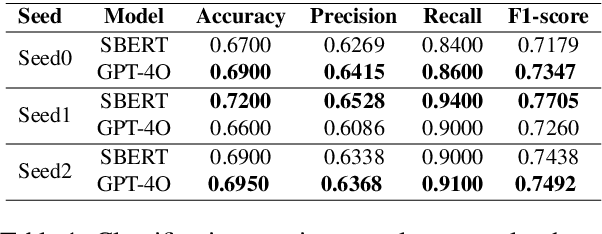
Being aware of important news is crucial for staying informed and making well-informed decisions efficiently. Natural Language Processing (NLP) approaches can significantly automate this process. This paper introduces the detection of important news, in a previously unexplored area, and presents a new benchmarking dataset (Khabarchin) for detecting important news in the Persian language. We define important news articles as those deemed significant for a considerable portion of society, capable of influencing their mindset or decision-making. The news articles are obtained from seven different prominent Persian news agencies, resulting in the annotation of 7,869 samples and the creation of the dataset. Two challenges of high disagreement and imbalance between classes were faced, and solutions were provided for them. We also propose several learning-based models, ranging from conventional machine learning to state-of-the-art transformer models, to tackle this task. Furthermore, we introduce the second task of important sentence detection in news articles, as they often come with a significant contextual length that makes it challenging for readers to identify important information. We identify these sentences in a weakly supervised manner.