 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward IIT-Inspired Consciousness in LLMs: A Reward-Based Learning Framework
Jan 30, 2026The pursuit of Artificial General Intelligence (AGI) is a central goal in language model development, in which consciousness-like processing could serve as a key facilitator. While current language models are not conscious, they exhibit behaviors analogous to certain aspects of consciousness. This paper investigates the implementation of a leading theory of consciousness, Integrated Information Theory (IIT), within language models via a reward-based learning paradigm. IIT provides a formal, axiom-based mathematical framework for quantifying consciousness. Drawing inspiration from its core principles, we formulate a novel reward function that quantifies a text's causality, coherence and integration, characteristics associated with conscious processing. Empirically, it is found that optimizing for this IIT-inspired reward leads to more concise text generation. On out of domain tasks, careful tuning achieves up to a 31% reduction in output length while preserving accuracy levels comparable to the base model. In addition to primary task performance, the broader effects of this training methodology on the model's confidence calibration and test-time computational scaling is analyzed. The proposed framework offers significant practical advantages: it is conceptually simple, computationally efficient, requires no external data or auxiliary models, and leverages a general, capability-driven signal rather than task-specific heuristics. Code available at https://github.com/MH-Sameti/LLM_PostTraining.git
Incorporating Error Level Noise Embedding for Improving LLM-Assisted Robustness in Persian Speech Recognition
Dec 19, 2025Automatic Speech Recognition (ASR) systems suffer significant performance degradation in noisy environments, a challenge that is especially severe for low-resource languages such as Persian. Even state-of-the-art models such as Whisper struggle to maintain accuracy under varying signal-to-noise ratios (SNRs). This study presents a robust noise-sensitive ASR error correction framework that combines multiple hypotheses and noise-aware modeling. Using noisy Persian speech, we generate 5-best hypotheses from a modified Whisper-large decoder. Error Level Noise (ELN) is introduced as a representation that captures semantic- and token-level disagreement across hypotheses, quantifying the linguistic distortions caused by noise. ELN thus provides a direct measure of noise-induced uncertainty, enabling the LLM to reason about the reliability of each hypothesis during correction. Three models are evaluated: (1) a base LLaMA-2-7B model without fine-tuning, (2) a fine-tuned variant trained on text-only hypotheses, and (3) a noise-conditioned model integrating ELN embeddings at both sentence and word levels. Experimental results demonstrate that the ELN-conditioned model achieves substantial reductions in Word Error Rate (WER). Specifically, on the challenging Mixed Noise test set, the proposed Fine-tuned + ELN (Ours) model reduces the WER from a baseline of 31.10\% (Raw Whisper) to 24.84\%, significantly surpassing the Fine-tuned (No ELN) text-only baseline of 30.79\%, whereas the original LLaMA-2-7B model increased the WER to 64.58\%, demonstrating that it is unable to correct Persian errors on its own. This confirms the effectiveness of combining multiple hypotheses with noise-aware embeddings for robust Persian ASR in noisy real-world scenarios.
Improving Direct Persian-English Speech-to-Speech Translation with Discrete Units and Synthetic Parallel Data
Nov 16, 2025
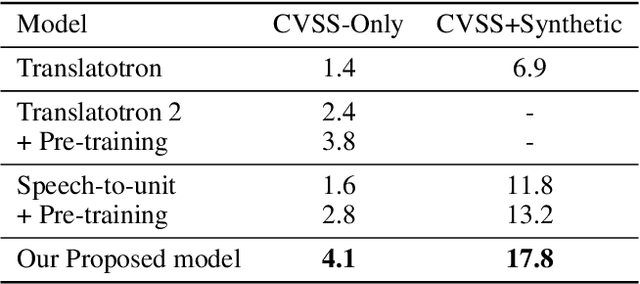
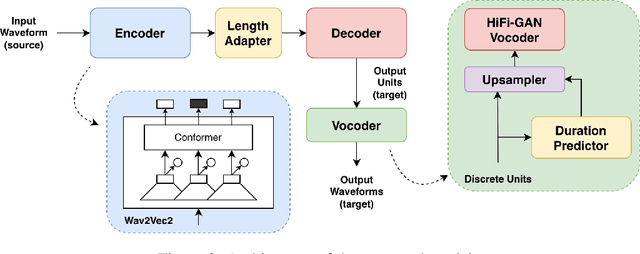
Direct speech-to-speech translation (S2ST), in which all components are trained jointly, is an attractive alternative to cascaded systems because it offers a simpler pipeline and lower inference latency. However, direct S2ST models require large amounts of parallel speech data in the source and target languages, which are rarely available for low-resource languages such as Persian. This paper presents a direct S2ST system for translating Persian speech into English speech, as well as a pipeline for synthetic parallel Persian-English speech generation. The model comprises three components: (1) a conformer-based encoder, initialized from self-supervised pre-training, maps source speech to high-level acoustic representations; (2) a causal transformer decoder with relative position multi-head attention translates these representations into discrete target speech units; (3) a unit-based neural vocoder generates waveforms from the predicted discrete units. To mitigate the data scarcity problem, we construct a new Persian-English parallel speech corpus by translating Persian speech transcriptions into English using a large language model and then synthesizing the corresponding English speech with a state-of-the-art zero-shot text-to-speech system. The resulting corpus increases the amount of available parallel speech by roughly a factor of six. On the Persian-English portion of the CVSS corpus, the proposed model achieves improvement of 4.6 ASR BLEU with the synthetic data over direct baselines. These results indicate that combining self-supervised pre-training, discrete speech units, and synthetic parallel data is effective for improving direct S2ST in low-resource language pairs such as Persian-English
Accent-Invariant Automatic Speech Recognition via Saliency-Driven Spectrogram Masking
Oct 10, 2025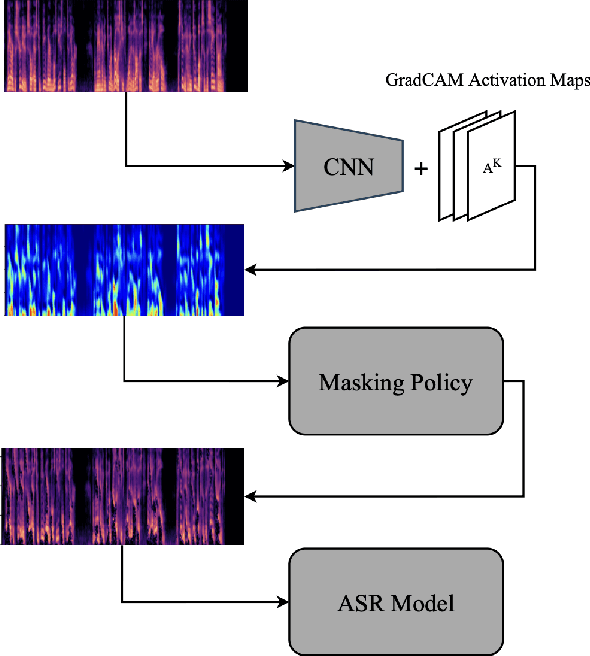
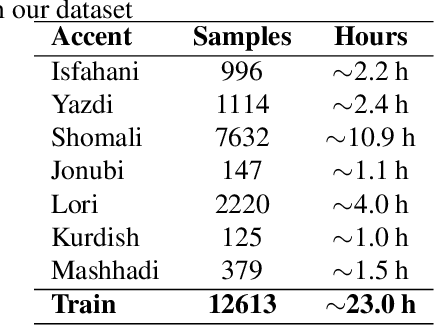
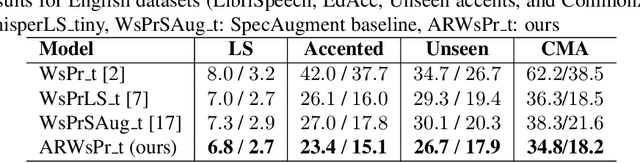
Pre-trained transformer-based models have significantly advanced automatic speech recognition (ASR), yet they remain sensitive to accent and dialectal variations, resulting in elevated word error rates (WER) in linguistically diverse languages such as English and Persian. To address this challenge, we propose an accent-invariant ASR framework that integrates accent and dialect classification into the recognition pipeline. Our approach involves training a spectrogram-based classifier to capture accent-specific cues, masking the regions most influential to its predictions, and using the masked spectrograms for data augmentation. This enhances the robustness of ASR models against accent variability. We evaluate the method using both English and Persian speech. For Persian, we introduce a newly collected dataset spanning multiple regional accents, establishing the first systematic benchmark for accent variation in Persian ASR that fills a critical gap in multilingual speech research and provides a foundation for future studies on low-resource, linguistically diverse languages. Experimental results with the Whisper model demonstrate that our masking and augmentation strategy yields substantial WER reductions in both English and Persian settings, confirming the effectiveness of the approach. This research advances the development of multilingual ASR systems that are resilient to accent and dialect diversity. Code and dataset are publicly available at: https://github.com/MH-Sameti/Accent_invariant_ASR
Sharif-STR at SemEval-2024 Task 1: Transformer as a Regression Model for Fine-Grained Scoring of Textual Semantic Relations
Jul 17, 2024



Semantic Textual Relatedness holds significant relevance in Natural Language Processing, finding applications across various domains. Traditionally, approaches to STR have relied on knowledge-based and statistical methods. However, with the emergence of Large Language Models, there has been a paradigm shift, ushering in new methodologies. In this paper, we delve into the investigation of sentence-level STR within Track A (Supervised) by leveraging fine-tuning techniques on the RoBERTa transformer. Our study focuses on assessing the efficacy of this approach across different languages. Notably, our findings indicate promising advancements in STR performance, particularly in Latin languages. Specifically, our results demonstrate notable improvements in English, achieving a correlation of 0.82 and securing a commendable 19th rank. Similarly, in Spanish, we achieved a correlation of 0.67, securing the 15th position. However, our approach encounters challenges in languages like Arabic, where we observed a correlation of only 0.38, resulting in a 20th rank.
* 10 pages, 9 figures, 4 tables
Sharif-MGTD at SemEval-2024 Task 8: A Transformer-Based Approach to Detect Machine Generated Text
Jul 16, 2024Detecting Machine-Generated Text (MGT) has emerged as a significant area of study within Natural Language Processing. While language models generate text, they often leave discernible traces, which can be scrutinized using either traditional feature-based methods or more advanced neural language models. In this research, we explore the effectiveness of fine-tuning a RoBERTa-base transformer, a powerful neural architecture, to address MGT detection as a binary classification task. Focusing specifically on Subtask A (Monolingual-English) within the SemEval-2024 competition framework, our proposed system achieves an accuracy of 78.9% on the test dataset, positioning us at 57th among participants. Our study addresses this challenge while considering the limited hardware resources, resulting in a system that excels at identifying human-written texts but encounters challenges in accurately discerning MGTs.
SLPL SHROOM at SemEval2024 Task 06: A comprehensive study on models ability to detect hallucination
Apr 09, 2024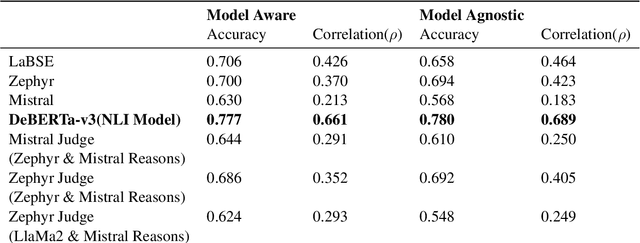
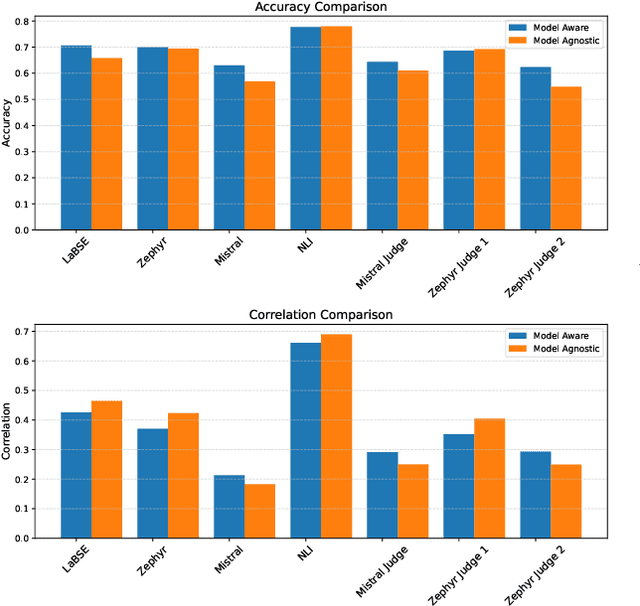
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
PCoQA: Persian Conversational Question Answering Dataset
Dec 07, 2023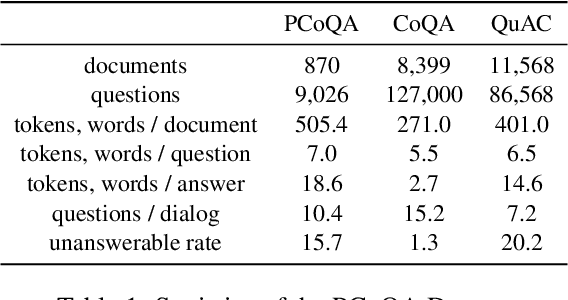
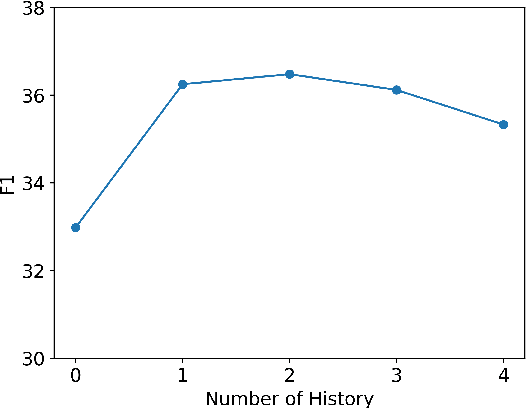
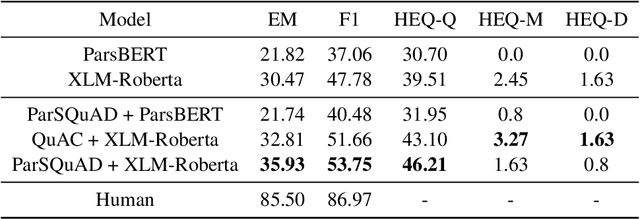
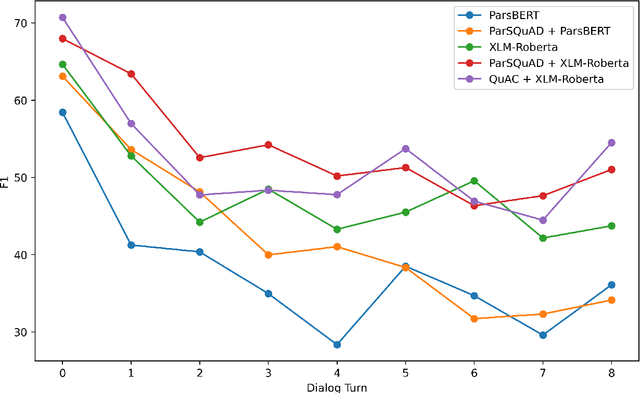
Humans seek information regarding a specific topic through performing a conversation containing a series of questions and answers. In the pursuit of conversational question answering research, we introduce the PCoQA, the first \textbf{P}ersian \textbf{Co}nversational \textbf{Q}uestion \textbf{A}nswering dataset, a resource comprising information-seeking dialogs encompassing a total of 9,026 contextually-driven questions. Each dialog involves a questioner, a responder, and a document from the Wikipedia; The questioner asks several inter-connected questions from the text and the responder provides a span of the document as the answer for each question. PCoQA is designed to present novel challenges compared to previous question answering datasets including having more open-ended non-factual answers, longer answers, and fewer lexical overlaps. This paper not only presents the comprehensive PCoQA dataset but also reports the performance of various benchmark models. Our models include baseline models and pre-trained models, which are leveraged to boost the performance of the model. The dataset and benchmarks are available at our Github page.
Imaginations of WALL-E : Reconstructing Experiences with an Imagination-Inspired Module for Advanced AI Systems
Aug 20, 2023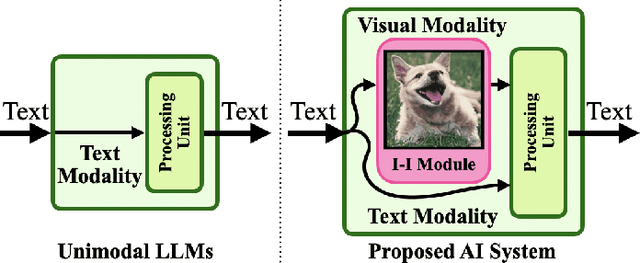



In this paper, we introduce a novel Artificial Intelligence (AI) system inspired by the philosophical and psychoanalytical concept of imagination as a ``Re-construction of Experiences". Our AI system is equipped with an imagination-inspired module that bridges the gap between textual inputs and other modalities, enriching the derived information based on previously learned experiences. A unique feature of our system is its ability to formulate independent perceptions of inputs. This leads to unique interpretations of a concept that may differ from human interpretations but are equally valid, a phenomenon we term as ``Interpretable Misunderstanding". We employ large-scale models, specifically a Multimodal Large Language Model (MLLM), enabling our proposed system to extract meaningful information across modalities while primarily remaining unimodal. We evaluated our system against other large language models across multiple tasks, including emotion recognition and question-answering, using a zero-shot methodology to ensure an unbiased scenario that may happen by fine-tuning. Significantly, our system outperformed the best Large Language Models (LLM) on the MELD, IEMOCAP, and CoQA datasets, achieving Weighted F1 (WF1) scores of 46.74%, 25.23%, and Overall F1 (OF1) score of 17%, respectively, compared to 22.89%, 12.28%, and 7% from the well-performing LLM. The goal is to go beyond the statistical view of language processing and tie it to human concepts such as philosophy and psychoanalysis. This work represents a significant advancement in the development of imagination-inspired AI systems, opening new possibilities for AI to generate deep and interpretable information across modalities, thereby enhancing human-AI interaction.
A Change of Heart: Improving Speech Emotion Recognition through Speech-to-Text Modality Conversion
Jul 21, 2023

Speech Emotion Recognition (SER) is a challenging task. In this paper, we introduce a modality conversion concept aimed at enhancing emotion recognition performance on the MELD dataset. We assess our approach through two experiments: first, a method named Modality-Conversion that employs automatic speech recognition (ASR) systems, followed by a text classifier; second, we assume perfect ASR output and investigate the impact of modality conversion on SER, this method is called Modality-Conversion++. Our findings indicate that the first method yields substantial results, while the second method outperforms state-of-the-art (SOTA) speech-based approaches in terms of SER weighted-F1 (WF1) score on the MELD dataset. This research highlights the potential of modality conversion for tasks that can be conducted in alternative modalities.