 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-Aware Sparse Autoencoders for Effective Mechanistic Interpretability
Jun 04, 2026Sparse Autoencoders (SAEs) are widely used for mechanistic interpretability in large language models, yet their formulation assigns each latent feature a single decoder direction, implicitly assuming features to be one-dimensional. We show that this assumption mismatches with the multi-dimensional structure of model features, provably inducing feature splitting through two distinct mechanisms. Geometrically, reconstructing a feature of intrinsic dimension $d_i \ge 2$ to error $\varepsilon$ with single-direction decoders forces a number of atoms that is exponential in $d_i$. From an end-to-end optimization perspective, this splitting is not merely possible but actively preferred. We prove that there exists a continuous path from the true $d_i$-dimensional basis to a strictly lower risk of the $\ell_1$-regularized SAE objective, whose descent directions drive any trained dictionary into that exponential regime. A single coherent feature is therefore fragmented across many near-collinear latents, producing spurious multiplicity and obscuring the intrinsic geometry. Motivated by this, we introduce Subspace-Aware Sparse Autoencoders (SASA), which replace single-vector decoders with learned decoder subspaces, enforce block sparsity via Top-$s$ group gating, and adapt each group's effective rank with a nuclear-norm regularizer. We then show that once the block size satisfies $r \ge d_i$, a single group not only can represent the entire feature slice but is the global minimizer of the SASA objective. This consolidation yields a sample complexity polynomial in $d_i$ rather than exponential -- a decisive advantage given that every training activation costs an LLM forward pass. Empirically, on GPT-2 and Mistral-7B, SASA reduces feature splitting and absorption, improves monosemanticity and interpretability, and matches or exceeds standard SAEs while training on roughly half the token budget.
Model Merging via Multi-Teacher Knowledge Distillation
Dec 24, 2025Model merging has emerged as a lightweight alternative to joint multi-task learning (MTL), yet the generalization properties of merged models remain largely unexplored. Establishing such theoretical guarantees is non-trivial, as the merging process typically forbids access to the original training data and involves combining fine-tuned models trained on fundamentally heterogeneous data distributions. Without a principled understanding of these dynamics, current methods often rely on heuristics to approximate the optimal combination of parameters. This dependence is most critical in coefficient scaling, the weighting factors that modulate the magnitude of each fine-tuned model's contribution to the shared parameter. However, without a principled objective to guide their selection, these methods lead to brittle performance and are highly sensitive to scaling initialization. We address this gap by (i) establishing a novel flatness-aware PAC-Bayes generalization bound specifically for the model merging setting. This analysis introduces a "cross-task heterogeneity" term that formally captures the mismatch between diverse fine-tuned model priors and the target multi-task distributions. Guided by this theoretical insight, (ii) we frame model merging as multi-teacher knowledge distillation on scarce, unlabeled data. We formally demonstrate that minimizing the student-teacher Kullback-Leibler divergence directly tightens the upper bound on the merged model's excess risk. Guided by the flatness-aware bound derived, (iii) we operationalize this objective via SAMerging, a method that employs Sharpness-Aware Minimization (SAM) to find flat minima. Empirically, SAMerging establishes a new state of the art across vision and NLP benchmarks, achieving remarkable performance. The code is available at https://github.com/arshandalili/SAMerging.
AIMA at SemEval-2024 Task 10: History-Based Emotion Recognition in Hindi-English Code-Mixed Conversations
Jan 19, 2025

In this study, we introduce a solution to the SemEval 2024 Task 10 on subtask 1, dedicated to Emotion Recognition in Conversation (ERC) in code-mixed Hindi-English conversations. ERC in code-mixed conversations presents unique challenges, as existing models are typically trained on monolingual datasets and may not perform well on code-mixed data. To address this, we propose a series of models that incorporate both the previous and future context of the current utterance, as well as the sequential information of the conversation. To facilitate the processing of code-mixed data, we developed a Hinglish-to-English translation pipeline to translate the code-mixed conversations into English. We designed four different base models, each utilizing powerful pre-trained encoders to extract features from the input but with varying architectures. By ensembling all of these models, we developed a final model that outperforms all other baselines.
AIMA at SemEval-2024 Task 3: Simple Yet Powerful Emotion Cause Pair Analysis
Jan 19, 2025The SemEval-2024 Task 3 presents two subtasks focusing on emotion-cause pair extraction within conversational contexts. Subtask 1 revolves around the extraction of textual emotion-cause pairs, where causes are defined and annotated as textual spans within the conversation. Conversely, Subtask 2 extends the analysis to encompass multimodal cues, including language, audio, and vision, acknowledging instances where causes may not be exclusively represented in the textual data. Our proposed model for emotion-cause analysis is meticulously structured into three core segments: (i) embedding extraction, (ii) cause-pair extraction & emotion classification, and (iii) cause extraction using QA after finding pairs. Leveraging state-of-the-art techniques and fine-tuning on task-specific datasets, our model effectively unravels the intricate web of conversational dynamics and extracts subtle cues signifying causality in emotional expressions. Our team, AIMA, demonstrated strong performance in the SemEval-2024 Task 3 competition. We ranked as the 10th in subtask 1 and the 6th in subtask 2 out of 23 teams.
Imaginations of WALL-E : Reconstructing Experiences with an Imagination-Inspired Module for Advanced AI Systems
Aug 20, 2023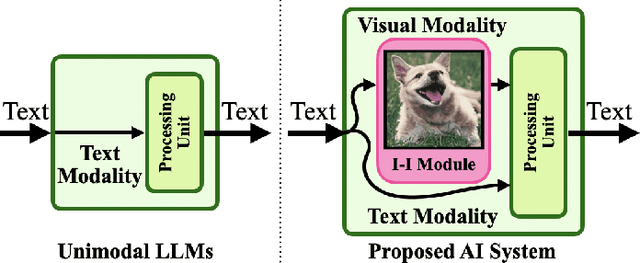



In this paper, we introduce a novel Artificial Intelligence (AI) system inspired by the philosophical and psychoanalytical concept of imagination as a ``Re-construction of Experiences". Our AI system is equipped with an imagination-inspired module that bridges the gap between textual inputs and other modalities, enriching the derived information based on previously learned experiences. A unique feature of our system is its ability to formulate independent perceptions of inputs. This leads to unique interpretations of a concept that may differ from human interpretations but are equally valid, a phenomenon we term as ``Interpretable Misunderstanding". We employ large-scale models, specifically a Multimodal Large Language Model (MLLM), enabling our proposed system to extract meaningful information across modalities while primarily remaining unimodal. We evaluated our system against other large language models across multiple tasks, including emotion recognition and question-answering, using a zero-shot methodology to ensure an unbiased scenario that may happen by fine-tuning. Significantly, our system outperformed the best Large Language Models (LLM) on the MELD, IEMOCAP, and CoQA datasets, achieving Weighted F1 (WF1) scores of 46.74%, 25.23%, and Overall F1 (OF1) score of 17%, respectively, compared to 22.89%, 12.28%, and 7% from the well-performing LLM. The goal is to go beyond the statistical view of language processing and tie it to human concepts such as philosophy and psychoanalysis. This work represents a significant advancement in the development of imagination-inspired AI systems, opening new possibilities for AI to generate deep and interpretable information across modalities, thereby enhancing human-AI interaction.