 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiMind at SemEval-2025 Task 7: Crosslingual Fact-Checked Claim Retrieval via Multi-Source Alignment
Dec 24, 2025This paper presents our system for SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval. In an era where misinformation spreads rapidly, effective fact-checking is increasingly critical. We introduce TriAligner, a novel approach that leverages a dual-encoder architecture with contrastive learning and incorporates both native and English translations across different modalities. Our method effectively retrieves claims across multiple languages by learning the relative importance of different sources in alignment. To enhance robustness, we employ efficient data preprocessing and augmentation using large language models while incorporating hard negative sampling to improve representation learning. We evaluate our approach on monolingual and crosslingual benchmarks, demonstrating significant improvements in retrieval accuracy and fact-checking performance over baselines.
Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025
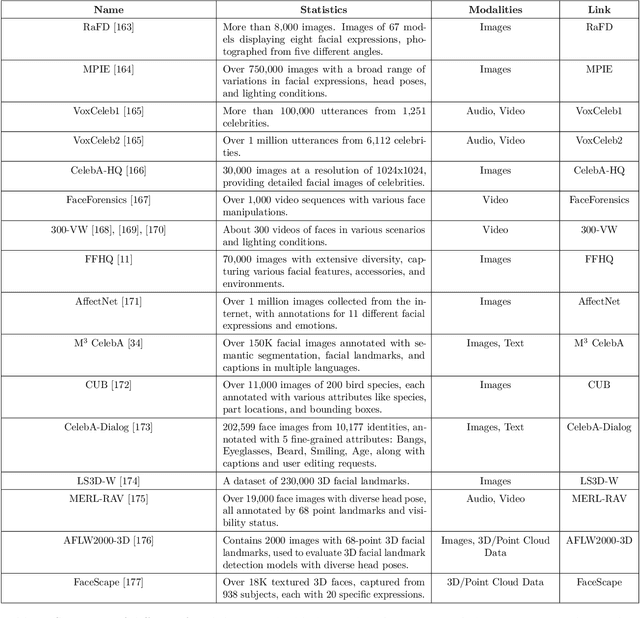
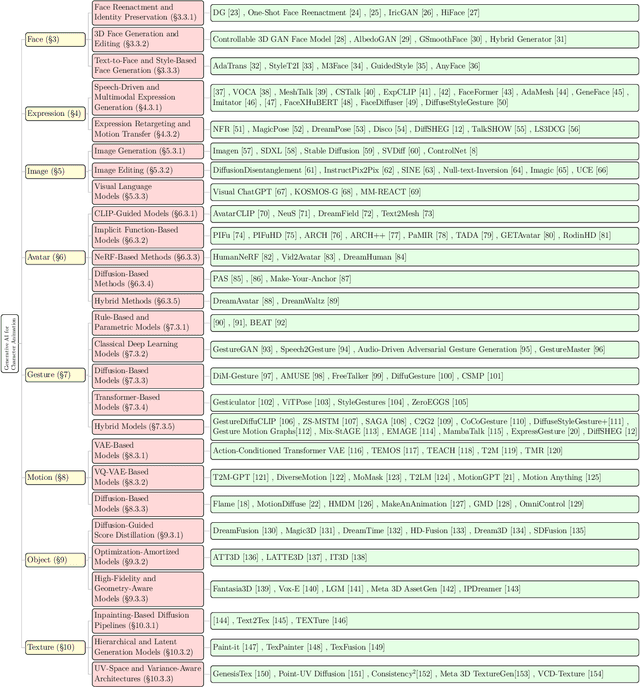
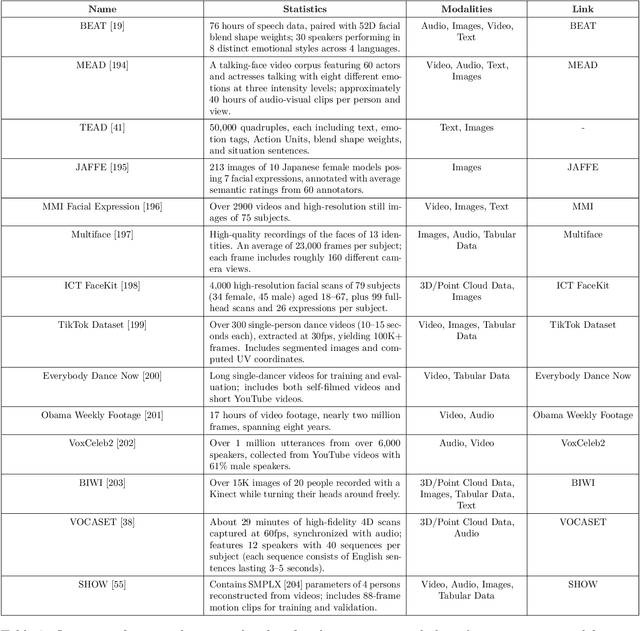
Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
Feb 12, 2025Large Language Models (LLMs) struggle with hallucinations and outdated knowledge due to their reliance on static training data. Retrieval-Augmented Generation (RAG) mitigates these issues by integrating external dynamic information enhancing factual and updated grounding. Recent advances in multimodal learning have led to the development of Multimodal RAG, incorporating multiple modalities such as text, images, audio, and video to enhance the generated outputs. However, cross-modal alignment and reasoning introduce unique challenges to Multimodal RAG, distinguishing it from traditional unimodal RAG. This survey offers a structured and comprehensive analysis of Multimodal RAG systems, covering datasets, metrics, benchmarks, evaluation, methodologies, and innovations in retrieval, fusion, augmentation, and generation. We precisely review training strategies, robustness enhancements, and loss functions, while also exploring the diverse Multimodal RAG scenarios. Furthermore, we discuss open challenges and future research directions to support advancements in this evolving field. This survey lays the foundation for developing more capable and reliable AI systems that effectively leverage multimodal dynamic external knowledge bases. Resources are available at https://github.com/llm-lab-org/Multimodal-RAG-Survey.
AIMA at SemEval-2024 Task 10: History-Based Emotion Recognition in Hindi-English Code-Mixed Conversations
Jan 19, 2025

In this study, we introduce a solution to the SemEval 2024 Task 10 on subtask 1, dedicated to Emotion Recognition in Conversation (ERC) in code-mixed Hindi-English conversations. ERC in code-mixed conversations presents unique challenges, as existing models are typically trained on monolingual datasets and may not perform well on code-mixed data. To address this, we propose a series of models that incorporate both the previous and future context of the current utterance, as well as the sequential information of the conversation. To facilitate the processing of code-mixed data, we developed a Hinglish-to-English translation pipeline to translate the code-mixed conversations into English. We designed four different base models, each utilizing powerful pre-trained encoders to extract features from the input but with varying architectures. By ensembling all of these models, we developed a final model that outperforms all other baselines.
AIMA at SemEval-2024 Task 3: Simple Yet Powerful Emotion Cause Pair Analysis
Jan 19, 2025The SemEval-2024 Task 3 presents two subtasks focusing on emotion-cause pair extraction within conversational contexts. Subtask 1 revolves around the extraction of textual emotion-cause pairs, where causes are defined and annotated as textual spans within the conversation. Conversely, Subtask 2 extends the analysis to encompass multimodal cues, including language, audio, and vision, acknowledging instances where causes may not be exclusively represented in the textual data. Our proposed model for emotion-cause analysis is meticulously structured into three core segments: (i) embedding extraction, (ii) cause-pair extraction & emotion classification, and (iii) cause extraction using QA after finding pairs. Leveraging state-of-the-art techniques and fine-tuning on task-specific datasets, our model effectively unravels the intricate web of conversational dynamics and extracts subtle cues signifying causality in emotional expressions. Our team, AIMA, demonstrated strong performance in the SemEval-2024 Task 3 competition. We ranked as the 10th in subtask 1 and the 6th in subtask 2 out of 23 teams.
CLASP: Contrastive Language-Speech Pretraining for Multilingual Multimodal Information Retrieval
Dec 17, 2024This study introduces CLASP (Contrastive Language-Speech Pretraining), a multilingual, multimodal representation tailored for audio-text information retrieval. CLASP leverages the synergy between spoken content and textual data. During training, we utilize our newly introduced speech-text dataset, which encompasses 15 diverse categories ranging from fiction to religion. CLASP's audio component integrates audio spectrograms with a pre-trained self-supervised speech model, while its language encoding counterpart employs a sentence encoder pre-trained on over 100 languages. This unified lightweight model bridges the gap between various modalities and languages, enhancing its effectiveness in handling and retrieving multilingual and multimodal data. Our evaluations across multiple languages demonstrate that CLASP establishes new benchmarks in HITS@1, MRR, and meanR metrics, outperforming traditional ASR-based retrieval approaches in specific scenarios.